全局视角
我们先以一个全局的视角看看 redis 的数据是怎么存放的:
redisDb (数据库)
└── dict (全局字典)
└── ht[0] (哈希表数组)
└── [Bucket] ──> dictEntry (节点)
├── key: [ SDS ("mykey") ]
└── val: [ redisObject ]
├── type: REDIS_STRING
├── encoding: EMBSTR (或 RAW)
└── ptr ──> [ SDS ("hello") ]Redis 的顶层存储核心是用全局字典(Global Dict,也叫 Keyspace)来管理所有的数据,Dict 采用的是双哈希表结构来保存数据主要是用来做渐进式 rehash,双哈希表结构用ht[0] 和 ht[1]来表示,通常数据只在 ht[0] 中,当哈希表需要扩容或缩容时,Redis 会一边处理请求,一边分批将数据从 ht[0] 迁移到 ht[1]。
哈希表其实就是一张大 bucket 数组,每个 bucket 是 dictEntry,由 dictht 数据结构来进行管理:
typedef struct dictht {
// 哈希表的槽
dictEntry **table;
// 哈希表槽个数,是2的整数次幂
unsigned long size;
// size-1,计算出一个key的hash后,直接 hash & sizemask即可算出所属的槽
unsigned long sizemask;
// 已使用大小
unsigned long used;
} dictht;在全局字典中,每一个键值对都被封装在一个 dictEntry 结构体中:
- Key(键):始终是一个指向 SDS (Simple Dynamic String) 结构的指针。即使你设置的是数字键,Redis 也会将其转为字符串 SDS 存储,SDS 结构下面我们会说;
- Value(值):始终是一个
redisObject结构体(或其指针)。redisObject就像一个通用容器,它封装了所有 Redis 数据类型(String, List, Hash 等)。
redisObject
在 Redis 中使用 redisObject 统一来管理底层的数据结构,无论底层是SDS、ziplist 或 dict统一用 redisObject 来进行封装,然后通过 type 来进行标识。
在 Redis 的 C 语言源码中,它的定义如下(以 64 位系统为例):
| 字段名 | 占用空间 | 作用说明 |
|---|---|---|
| type | 4 bits | 逻辑类型:标识它是 String、List、Hash、Set 还是 ZSet。 |
| encoding | 4 bits | 物理编码:标识底层具体是用什么实现的(如 ziplist、skiplist、int 等)。 |
| lru / lfu | 24 bits | 对象热度:记录最后一次被访问的时间(LRU)或访问频率(LFU),用于内存淘汰。 |
| refcount | 4 bytes | 引用计数:记录有多少地方引用了这个对象。为 0 时对象被销毁。 |
| ptr | 8 bytes | 数据指针:指向底层真实数据的内存地址。 |
合计算下来,一个 redisObject 固定占用 16 字节。
这样做就是统一了接口,当你执行 DEL 命令时,Redis 不需要关心你删的是 String 还是 List,它只需要操作 redisObject 这个通用结构。
除此之外它有三大作用:
-
类型检查与多态
当你输入
LPOP key时,Redis 会先检查这个redisObject的type是不是REDIS_LIST。如果不是,直接返回错误。如果是,它会根据encoding字段去调用对应的函数(比如是从linkedlist弹出还是从listpack弹出)。 -
内存管理与共享
通过 refcount 的引用计数来控制内存的释放,当引用计数归零,Redis 才会真正释放内存。
-
内存淘汰(LRU/LFU 算法)
LRU 模式就会通过时间戳来看该对象是否应该被淘汰。LFU 模式它根据数据被访问的频率来决定淘汰对象,高 16 位存时间,低 8 位存访问计数。 如果这个字段很久没更新,当 Redis 内存不足时,它就会优先被“踢出”内存。
虽然在全局字典看来,所有的 Value 都是一个 redisObject,但 redisObject 内部通过 type 和 ptr 指向了完全不同的底层世界:
| 命令示例 | redisObject -> type | redisObject -> ptr 指向的内容 |
|---|---|---|
SET key "val" |
REDIS_STRING | 指向一个 SDS(可能是 int, embstr 或 raw) |
HSET user:1 name "A" |
REDIS_HASH | 指向一个 Dict 或 listpack/ziplist |
LPUSH list "item" |
REDIS_LIST | 指向一个 quicklist(由多个 listpack 组成的双端链表) |
SADD tags "java" |
REDIS_SET | 指向一个 Dict (value 为 NULL) 或 intset |
ZADD rank 100 "A" |
REDIS_ZSET | 指向一个 zset 结构(内含 Skiplist + Dict) |
String
Redis 设计了简单动态字符串(Simple Dynamic String,SDS)的结构,用来表示字符串,动态字符串结构如下图所示:
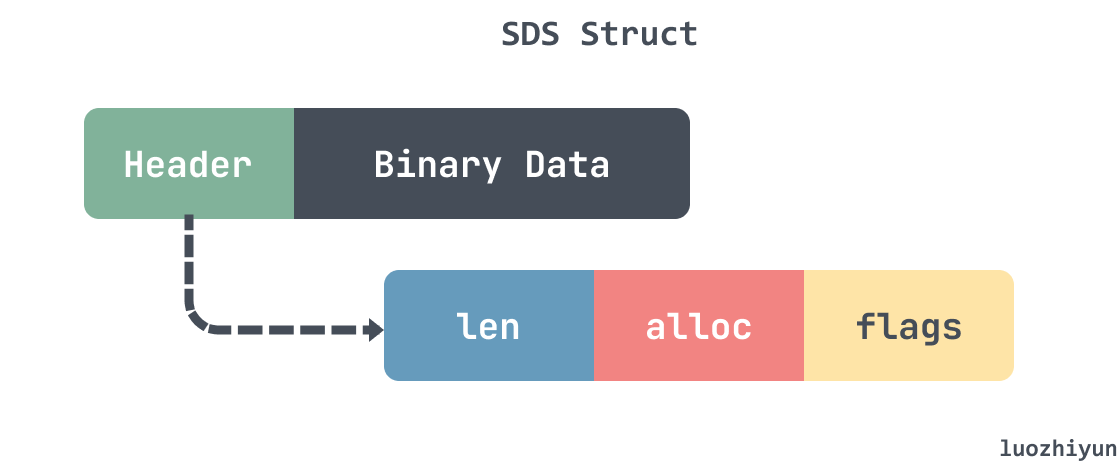
SDS 大致由两部分构成:header以及 数据段,其中 header 还包含3个字段 len、alloc、flags。len 表示数据长度,alloc 表示分配的内存长度,flags 表示了 sds 的数据类型。
在以前的版本中,sds 的header其实占用内存是固定8字节大小的,所以如果在redis中存放的都是小字符串,那么 sds 的 header 将会占用很多的内存空间。
但是随着 sds 的版本变迁,其实在内存占用方面还是做了一些优化:
- 在 sds 2.0 之前 header 的大小是固定的 int 类型,2.0 版本之后会根据传入的字符大小调整 header 的 len 和 alloc 的类型以便节省内存占用。
- header 的结构体使用
__attribute__修饰,这里主要是防止编译器自动进行内存对齐,这样可以减少编译器因为内存对齐而引起的 padding 的数量所占用的内存。
目前的版本中共定义了五种类型的 sds header,其中 sdshdr5 是没用的,所以没画:
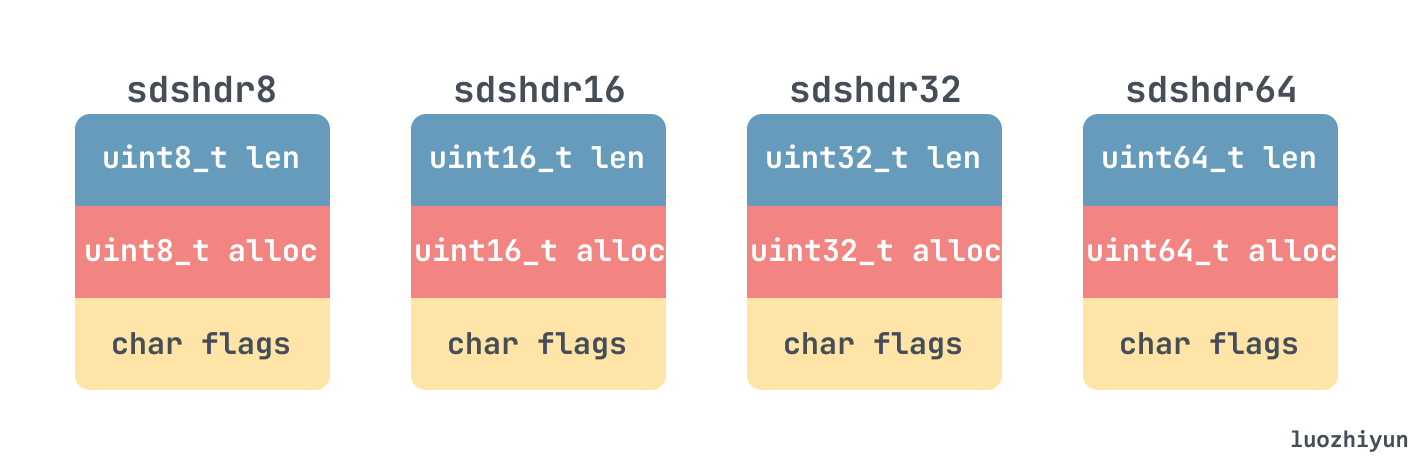
当执行 SET key value 时,对于 key 来说存放方式就是:
DictEntry
│
└── key (指针)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ [ SDS Header ] [ SDS Body (buf) ] [ \0 ] │
└──────────────────────────────────────────────────────────────┘
▲ ▲ ▲
│ │ │
│ │ └── 结尾 (1 byte)
│ │
│ └── 你的 1MB 甚至 512MB 的数据
│
└── 这里的元数据结构会根据大小变化
(sdshdr8 -> sdshdr16 -> ... -> sdshdr64)对于 value 来说,Redis 会根据 value 的情况选择以下三者之一:
int编码
- 适用场景:如果字符串内容可以转为 long 类型的整数。
- 实现方式:直接将整数值存在
redisObject的ptr指针位置(指针 8 字节,正好存下一个 long)。 - 优点:零额外内存分配。不需要 SDS,不需要额外的内存块。
embstr编码
- 适用场景:长度小于等于 44 字节 的字符串。
- 实现方式:
redisObject结构体与SDS结构体在内存中是连续的一块空间。 - 优点:
- 只需一次内存分配/释放。
- 利用 CPU 缓存局部性(连续内存读取更快)。
- 阈值由来:16 字节 (robj) + 3 字节 (sdshdr8) + 44 字节 (data) + 1 字节 (\0) = 64 字节。这正好是常见的 CPU Cache Line 大小。
raw编码
- 适用场景:长度大于 44 字节 的字符串。
- 实现方式:
redisObject和SDS是两块独立的内存区域,通过指针连接。 - 优点:适合大字符串,扩容时不需要重新分配整个
redisObject。
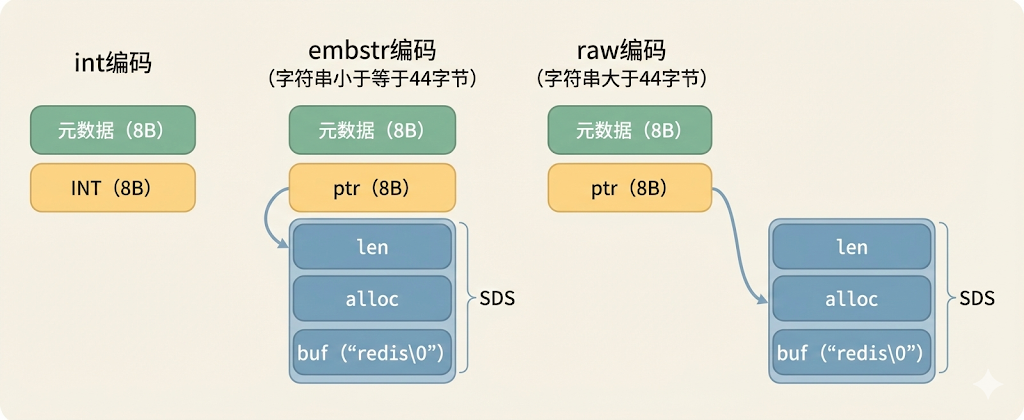
所以我们可以看到 key 和 value 其实是分两部分存储:
-
Value (值):可能会因为 RAW 编码 而导致
redisObject和SDS分离(不挨着)。 -
Key (键):永远没有
redisObject包装,它直接就是一个 SDS。所以 Key 的 Header 和数据永远是连在一起的,没有任何例外。
容量估算
jemalloc
在估算容量之前,我们来看看 redis 使用的 jemalloc 是怎么做内存分配的。
jemalloc 预先定义了一系列固定的内存块大小(称为 Size Class)。当 Redis 请求分配 N 字节时,jemalloc 会查找第一个大于等于 N 的规格(Size Class)内存块进行分配。
为了减少浪费,jemalloc 的规格设计得很科学,并不是单纯的 2 的幂次方(2, 4, 8, 16…),而是更加细密:
| 规格区间 | 具体的 Size Class (字节) |
|---|---|
| 8B – 128B | 8, 16, 32, 48, 64, 80, 96, 112, 128 |
| 128B – … | 160, 192, 224, 256, 320 … |
举个具体的例子:
假设你在 Redis 里存一个简单的字符串,算上 SDS 头部等开销,Redis 向系统申请了 20 字节。
- 查找:jemalloc 看了看手里的规格表:8, 16, 32…
- 判定:16 字节装不下 20 字节。
- 取整:下一个规格是 32 字节。
- 分配:给 Redis 分配 32 字节 的内存块。
结果:
- 实际使用:20 字节。
- 实际占用:32 字节。
- 浪费:12 字节(这被称为内部碎片)。
为什么要这样做?(好处)
虽然看起来浪费了一点点空间(内部碎片),但对整个系统来说,收益巨大:
- 速度极快: 不需要每次都去计算哪里有空闲内存。jemalloc 维护了许多“桶”(Bin),比如“32字节桶”、“64字节桶”。要 20 字节?直接从“32字节桶”里拿一个出来就行,O(1) 复杂度。
- 减少外部碎片: 当你释放这 32 字节后,它会干干净净地回到“32字节桶”里。下一个申请 17~32 字节的请求来了,可以直接复用这块内存,严丝合缝。
- 缓存友好: 数据按照固定大小排列,更容易被 CPU 缓存(Cache Line)命中。
以 string 为例估算分析
所以根据我们上面的介绍,应该知道一个 String 键值对的总内存占用主要由三部分组成:
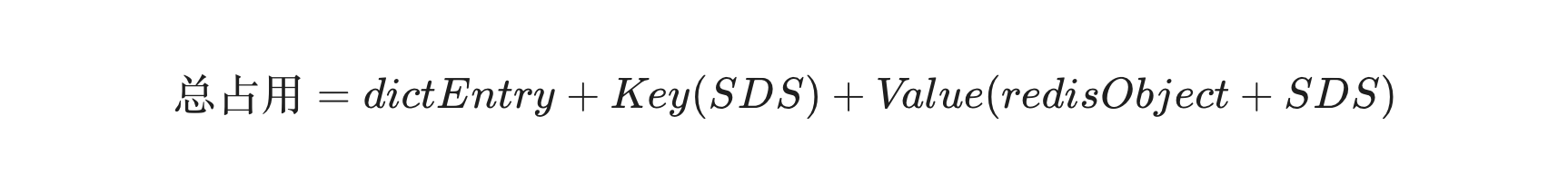
-
全局字典节点 (
dictEntry):固定 24 字节- 包含三个指针(Key 指针、Value 指针、Next 指针),各占 8 字节。
-
键 (Key):SDS 结构
- 包含:SDS Header + Data + 1 (\0)
- 需要注意的是 redis 使用的是 jemalloc 来做内存分配,jemalloc 会将结果向上取整到最近的分配阶梯(如 8, 16, 32, 48, 64 字节)
-
值 (Value):取决于编码方式,上面我们有介绍,就不细说了 int、embstr、raw 编码;
编码方式 计算公式 说明 INT 16 字节 只有 redisObject,数值直接存在指针里。EMBSTR $malloc(16 + 3 + len(Val) + 1)$ redisObject与 SDS 连续分配,整体向上取整。RAW $16 + malloc(3 + len(Val) + 1)$ redisObject与 SDS 分开分配,各自取整后再求和。
实例估算:存储 SET "key" "value"
我们来算一下这个极小键值对实际占了多少地儿:
- dictEntry: 24 字节。
- Key ("key"):
- 长度为 3,计算:3(Header) + 3(Data) + 1(\0) = 7 字节。
- jemalloc 向上取整为 8 字节。
- Value ("value"):
- 长度为 5,采用 EMBSTR 编码。
- 计算:16(robj) + 3(Header) + 5(Data) + 1(\0) = 25 字节。
- jemalloc 向上取整为 32 字节。
- 总计:24 + 8 + 32 = 64 字节。
所以我们可以看到个有趣的事实,存储 8 字节的原始数据,Redis 实际需要 64 字节,膨胀率高达 8 倍。
估算建议
实测采样法
不要试图用数学公式去死算每一个字节(因为 jemalloc 和 struct padding 很难完全算准),而是采用 “小规模采样 + 线性推演”。
我们可以启动一个空的 Redis 实例,记录初始内存 used_memory(通常在 1MB 左右,是 Redis 自身的启动开销)。编写脚本,写入 10,000 个 具有代表性的 Key-Value 数据(长度和类型要符合你的生产场景)。
然后计算初始内存使用 和 最终内存使用的差值,然后计算出单挑数据消耗,将单条数据消耗 X 预计总数据量就可以得到最终的预估结果。
经验法则:估算膨胀系数
如果你没法做测试,只能盲算,必须根据 Key/Value 的平均大小 来应用不同的膨胀系数。
-
小对象场景(最容易翻车)
-
场景:Key = 10 字节,Value = 10 字节。
-
原始数据:20 字节。
-
Redis 实际占用:约 64 ~ 80 字节。
-
膨胀系数:3倍 ~ 4倍。
- 原因:
dictEntry(24B) +redisObject(16B) 即使什么都不存就已经 40B 了。加上 jemalloc 的 8B/16B/32B 对齐,开销巨大。
- 原因:
-
-
中等对象场景
- 场景:Key = 30 字节,Value = 500 字节。
- 膨胀系数:1.1倍 ~ 1.2倍。
- 原因:此时数据的占比上来,头部元数据(Overhead)的占比下降。
-
大对象场景
-
场景:Key = 50 字节,Value = 10 KB。
-
膨胀系数:接近 1.05倍。
- 原因:jemalloc 对大内存块的分配非常精准(Page 对齐),且元数据占比可忽略不计。
-