看完这个实现之后,感觉还是要多看源码,多研究。其实JRaft的定时任务调度器是基于Netty的时间轮来做的,如果没有看过Netty的源码,很可能并不知道时间轮算法,也就很难想到要去使用这么优秀的定时调度算法了。
对于介绍RepeatedTimer,我拿Node初始化的时候的electionTimer进行讲解
this.electionTimer = new RepeatedTimer("JRaft-ElectionTimer", this.options.getElectionTimeoutMs()) {
@Override
protected void onTrigger() {
handleElectionTimeout();
}
@Override
protected int adjustTimeout(final int timeoutMs) {
//在一定范围内返回一个随机的时间戳
//为了避免同时发起选举而导致失败
return randomTimeout(timeoutMs);
}
};构造器
由electionTimer的构造方法可以看出RepeatedTimer需要传入两个参数,一个是name,另一个是time
//timer是HashedWheelTimer
private final Timer timer;
//实例是HashedWheelTimeout
private Timeout timeout;
public RepeatedTimer(String name, int timeoutMs) {
//name代表RepeatedTimer实例的种类,timeoutMs是超时时间
this(name, timeoutMs, new HashedWheelTimer(new NamedThreadFactory(name, true), 1, TimeUnit.MILLISECONDS, 2048));
}
public RepeatedTimer(String name, int timeoutMs, Timer timer) {
super();
this.name = name;
this.timeoutMs = timeoutMs;
this.stopped = true;
this.timer = Requires.requireNonNull(timer, "timer");
}在构造器中会根据传进来的值初始化一个name和一个timeoutMs,然后实例化一个timer,RepeatedTimer的run方法是由timer进行回调。在RepeatedTimer中会持有两个对象,一个是timer,一个是timeout
启动RepeatedTimer
对于一个RepeatedTimer实例,我们可以通过start方法来启动它:
public void start() {
//加锁,只能一个线程调用这个方法
this.lock.lock();
try {
//destroyed默认是false
if (this.destroyed) {
return;
}
//stopped在构造器中初始化为ture
if (!this.stopped) {
return;
}
//启动完一次后下次就无法再次往下继续
this.stopped = false;
//running默认为false
if (this.running) {
return;
}
this.running = true;
schedule();
} finally {
this.lock.unlock();
}
}在调用start方法进行启动后会进行一系列的校验和赋值,从上面的赋值以及加锁的情况来看,这个是只能被调用一次的。然后会调用到schedule方法中
private void schedule() {
if(this.timeout != null) {
this.timeout.cancel();
}
final TimerTask timerTask = timeout -> {
try {
RepeatedTimer.this.run();
} catch (final Throwable t) {
LOG.error("Run timer task failed, taskName={}.", RepeatedTimer.this.name, t);
}
};
this.timeout = this.timer.newTimeout(timerTask, adjustTimeout(this.timeoutMs), TimeUnit.MILLISECONDS);
}如果timeout不为空,那么会调用HashedWheelTimeout的cancel方法。然后封装一个TimerTask实例,当执行TimerTask的run方法的时候会调用RepeatedTimer实例的run方法。然后传入到timer中,TimerTask的run方法由timer进行调用,并将返回值赋值给timeout。
如果timer调用了TimerTask的run方法,那么便会回调到RepeatedTimer的run方法中:
RepeatedTimer#run
public void run() {
//加锁
this.lock.lock();
try {
//表示RepeatedTimer已经被调用过
this.invoking = true;
} finally {
this.lock.unlock();
}
try {
//然后会调用RepeatedTimer实例实现的方法
onTrigger();
} catch (final Throwable t) {
LOG.error("Run timer failed.", t);
}
boolean invokeDestroyed = false;
this.lock.lock();
try {
this.invoking = false;
//如果调用了stop方法,那么将不会继续调用schedule方法
if (this.stopped) {
this.running = false;
invokeDestroyed = this.destroyed;
} else {
this.timeout = null;
schedule();
}
} finally {
this.lock.unlock();
}
if (invokeDestroyed) {
onDestroy();
}
}
protected void onDestroy() {
// NO-OP
}
这个run方法会由timer进行回调,如果没有调用stop或destroy方法的话,那么调用完onTrigger方法后会继续调用schedule,然后一次次循环调用RepeatedTimer的run方法。
如果调用了destroy方法,在这里会有一个onDestroy的方法,可以由实现类override复写执行一个钩子。
HashedWheelTimer的基本介绍
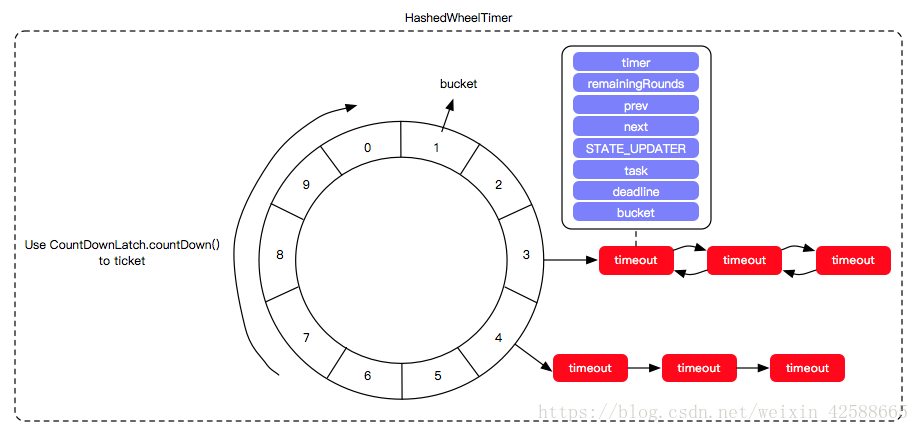
HashedWheelTimer通过一定的hash规则将不同timeout的定时任务划分到HashedWheelBucket进行管理,而HashedWheelBucket利用双向链表结构维护了某一时刻需要执行的定时任务列表
Wheel
时间轮,是一个HashedWheelBucket数组,数组数量越多,定时任务管理的时间精度越精确。tick每走一格都会将对应的wheel数组里面的bucket拿出来进行调度。
Worker
Worker继承自Runnable,HashedWheelTimer必须通过Worker线程操作HashedWheelTimer中的定时任务。Worker是整个HashedWheelTimer的执行流程管理者,控制了定时任务分配、全局deadline时间计算、管理未执行的定时任务、时钟计算、未执行定时任务回收处理。
HashedWheelTimeout
是HashedWheelTimer的执行单位,维护了其所属的HashedWheelTimer和HashedWheelBucket的引用、需要执行的任务逻辑、当前轮次以及当前任务的超时时间(不变)等,可以认为是自定义任务的一层Wrapper。
HashedWheelBucket
HashedWheelBucket维护了hash到其内的所有HashedWheelTimeout结构,是一个双向队列。
HashedWheelTimer的构造器
在初始化RepeatedTimer实例的时候会实例化一个HashedWheelTimer:
new HashedWheelTimer(new NamedThreadFactory(name, true), 1, TimeUnit.MILLISECONDS, 2048)然后调用HashedWheelTimer的构造器:
private final HashedWheelBucket[] wheel;
private final int mask;
private final long tickDuration;
private final Worker worker = new Worker();
private final Thread workerThread;
private final long maxPendingTimeouts;
private static final int INSTANCE_COUNT_LIMIT = 256;
private static final AtomicInteger instanceCounter = new AtomicInteger();
private static final AtomicBoolean warnedTooManyInstances = new AtomicBoolean();
public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel) {
tickDuration
this(threadFactory, tickDuration, unit, ticksPerWheel, -1);
}
public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel,
long maxPendingTimeouts) {
if (threadFactory == null) {
throw new NullPointerException("threadFactory");
}
//unit = MILLISECONDS
if (unit == null) {
throw new NullPointerException("unit");
}
if (tickDuration <= 0) {
throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
}
if (ticksPerWheel <= 0) {
throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
}
// Normalize ticksPerWheel to power of two and initialize the wheel.
// 创建一个HashedWheelBucket数组
// 创建时间轮基本的数据结构,一个数组。长度为不小于ticksPerWheel的最小2的n次方
wheel = createWheel(ticksPerWheel);
// 这是一个标示符,用来快速计算任务应该呆的格子。
// 我们知道,给定一个deadline的定时任务,其应该呆的格子=deadline%wheel.length.但是%操作是个相对耗时的操作,所以使用一种变通的位运算代替:
// 因为一圈的长度为2的n次方,mask = 2^n-1后低位将全部是1,然后deadline&mast == deadline%wheel.length
// java中的HashMap在进行hash之后,进行index的hash寻址寻址的算法也是和这个一样的
mask = wheel.length - 1;
// Convert tickDuration to nanos.
//tickDuration传入是1的话,这里会转换成1000000
this.tickDuration = unit.toNanos(tickDuration);
// Prevent overflow.
// 校验是否存在溢出。即指针转动的时间间隔不能太长而导致tickDuration*wheel.length>Long.MAX_VALUE
if (this.tickDuration >= Long.MAX_VALUE / wheel.length) {
throw new IllegalArgumentException(String.format(
"tickDuration: %d (expected: 0 < tickDuration in nanos < %d", tickDuration, Long.MAX_VALUE
/ wheel.length));
}
//将worker包装成thread
workerThread = threadFactory.newThread(worker);
//maxPendingTimeouts = -1
this.maxPendingTimeouts = maxPendingTimeouts;
//如果HashedWheelTimer实例太多,那么就会打印一个error日志
if (instanceCounter.incrementAndGet() > INSTANCE_COUNT_LIMIT
&& warnedTooManyInstances.compareAndSet(false, true)) {
reportTooManyInstances();
}
}这个构造器里面主要做一些初始化的工作。
- 初始化一个wheel数据,我们这里初始化的数组长度为2048.
- 初始化mask,用来计算槽位的下标,类似于hashmap的槽位的算法,因为wheel的长度已经是一个2的n次方,所以2^n-1后低位将全部是1,用&可以快速的定位槽位,比%耗时更低
- 初始化tickDuration,这里会将传入的tickDuration转化成纳秒,那么这里是1000,000
- 校验整个时间轮走完的时间不能过长
- 包装worker线程
- 因为HashedWheelTimer是一个很消耗资源的一个结构,所以校验HashedWheelTimer实例不能太多,如果太多会打印error日志
启动timer
时间轮算法中并不需要手动的去调用start方法来启动,而是在添加节点的时候会启动时间轮。
我们在RepeatedTimer的schedule方法里会调用newTimeout向时间轮中添加一个任务。
HashedWheelTimer#newTimeout
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts (" + pendingTimeoutsCount
+ ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
// 如果时间轮没有启动,则启动
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
//在delay为正数的情况下,deadline是不可能为负数
//如果为负数,那么说明超过了long的最大值
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
// 这里定时任务不是直接加到对应的格子中,而是先加入到一个队列里,然后等到下一个tick的时候,
// 会从队列里取出最多100000个任务加入到指定的格子中
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
//Worker会去处理timeouts队列里面的数据
timeouts.add(timeout);
return timeout;
}在这个方法中,在校验之后会调用start方法启动时间轮,然后设置deadline,这个时间等于时间轮启动的时间点+延迟的的时间;
然后新建一个HashedWheelTimeout实例,会直接加入到timeouts队列中去,timeouts对列会在worker的run方法里面取出来放入到wheel中进行处理。
然后我们来看看start方法:
HashedWheelTimer#start
private static final AtomicIntegerFieldUpdater<HashedWheelTimer> workerStateUpdater = AtomicIntegerFieldUpdater.newUpdater(HashedWheelTimer.class,"workerState");
private volatile int workerState;
//不需要你主动调用,当有任务添加进来的的时候他就会跑
public void start() {
//workerState一开始的时候是0(WORKER_STATE_INIT),然后才会设置为1(WORKER_STATE_STARTED)
switch (workerStateUpdater.get(this)) {
case WORKER_STATE_INIT:
//使用cas来获取启动调度的权力,只有竞争到的线程允许来进行实例启动
if (workerStateUpdater.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {
//如果成功设置了workerState,那么就调用workerThread线程
workerThread.start();
}
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
throw new IllegalStateException("cannot be started once stopped");
default:
throw new Error("Invalid WorkerState");
}
// 等待worker线程初始化时间轮的启动时间
// Wait until the startTime is initialized by the worker.
while (startTime == 0) {
try {
//这里使用countDownLauch来确保调度的线程已经被启动
startTimeInitialized.await();
} catch (InterruptedException ignore) {
// Ignore - it will be ready very soon.
}
}
}由这里我们可以看出,启动时间轮是不需要手动去调用的,而是在有任务的时候会自动运行,防止在没有任务的时候空转浪费资源。
在start方法里面会使用AtomicIntegerFieldUpdater的方式来更新workerState这个变量,如果没有启动过那么直接在cas成功之后调用start方法启动workerThread线程。
如果workerThread还没运行,那么会在while循环中等待,直到workerThread运行为止才会往下运行。
开始时间轮转
时间轮的运转是在Worker的run方法中进行的:
Worker#run
private final Set<Timeout> unprocessedTimeouts = new HashSet<>();
private long tick;
public void run() {
// Initialize the startTime.
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
//HashedWheelTimer的start方法会继续往下运行
// Notify the other threads waiting for the initialization at start().
startTimeInitialized.countDown();
do {
//返回的是当前的nanoTime- startTime
//也就是返回的是 每 tick 一次的时间间隔
final long deadline = waitForNextTick();
if (deadline > 0) {
//算出时间轮的槽位
int idx = (int) (tick & mask);
//移除cancelledTimeouts中的bucket
// 从bucket中移除timeout
processCancelledTasks();
HashedWheelBucket bucket = wheel[idx];
// 将newTimeout()方法中加入到待处理定时任务队列中的任务加入到指定的格子中
transferTimeoutsToBuckets();
bucket.expireTimeouts(deadline);
tick++;
}
// 校验如果workerState是started状态,那么就一直循环
} while (workerStateUpdater.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
// Fill the unprocessedTimeouts so we can return them from stop() method.
for (HashedWheelBucket bucket : wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (;;) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
//如果有没有被处理的timeout,那么加入到unprocessedTimeouts对列中
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
//处理被取消的任务
processCancelledTasks();
}- 这个方法首先会设置一个时间轮的开始时间startTime,然后调用startTimeInitialized的countDown让被阻塞的线程往下运行
- 调用waitForNextTick等待到下次tick的到来,并返回当次的tick时间-startTime
- 通过&的方式获取时间轮的槽位
- 移除掉被取消的task
- 将timeouts中的任务转移到对应的wheel槽位中,如果槽位中不止一个bucket,那么串成一个链表
- 执行格子中的到期任务
- 遍历整个wheel,将过期的bucket放入到unprocessedTimeouts队列中
- 将timeouts中过期的bucket放入到unprocessedTimeouts队列中
上面所有的过期但未被处理的bucket会在调用stop方法的时候返回unprocessedTimeouts队列中的数据。所以unprocessedTimeouts中的数据只是做一个记录,并不会再次被执行。
时间轮的所有处理过程都在do-while循环中被处理,我们下面一个个分析
处理被取消的任务
Worker#processCancelledTasks
private void processCancelledTasks() {
for (;;) {
HashedWheelTimeout timeout = cancelledTimeouts.poll();
if (timeout == null) {
// all processed
break;
}
try {
timeout.remove();
} catch (Throwable t) {
if (LOG.isWarnEnabled()) {
LOG.warn("An exception was thrown while process a cancellation task", t);
}
}
}
}这个方法相当的简单,因为在调用HashedWheelTimer的stop方法的时候会将要取消的HashedWheelTimeout实例放入到cancelledTimeouts队列中,所以这里只需要循环把队列中的数据取出来,然后调用HashedWheelTimeout的remove方法将自己在bucket移除就好了
HashedWheelTimeout#remove
void remove() {
HashedWheelBucket bucket = this.bucket;
if (bucket != null) {
//这里面涉及到链表的引用摘除,十分清晰易懂,想了解的可以去看看
bucket.remove(this);
} else {
timer.pendingTimeouts.decrementAndGet();
}
}转移数据到时间轮中
Worker#transferTimeoutsToBuckets
private void transferTimeoutsToBuckets() {
// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
// adds new timeouts in a loop.
// 每次tick只处理10w个任务,以免阻塞worker线程
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
//已经被取消了;
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
//calculated = tick 次数
long calculated = timeout.deadline / tickDuration;
// 计算剩余的轮数, 只有 timer 走够轮数, 并且到达了 task 所在的 slot, task 才会过期
timeout.remainingRounds = (calculated - tick) / wheel.length;
//如果任务在timeouts队列里面放久了, 以至于已经过了执行时间, 这个时候就使用当前tick, 也就是放到当前bucket, 此方法调用完后就会被执行
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
//// 算出任务应该插入的 wheel 的 slot, slotIndex = tick 次数 & mask, mask = wheel.length - 1
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
//将timeout加入到bucket链表中
bucket.addTimeout(timeout);
}
}- 每次调用这个方法会处理10w个任务,以免阻塞worker线程
- 在校验之后会用timeout的deadline除以每次tick运行的时间tickDuration得出需要tick多少次才会运行这个timeout的任务
- 由于timeout的deadline实际上还包含了worker线程启动到timeout加入队列这段时间,所以在算remainingRounds的时候需要减去当前的tick次数
|_____________________|____________ worker启动时间 timeout任务加入时间
4. 最后根据计算出来的ticks来&算出wheel的槽位,加入到bucket链表中
#### 执行到期任务
在worker的run方法的do-while循环中,在根据当前的tick拿到wheel中的bucket后会调用expireTimeouts方法来处理这个bucket的到期任务
**HashedWheelBucket#expireTimeouts**
```java
// 过期并执行格子中的到期任务,tick到该格子的时候,worker线程会调用这个方法,
//根据deadline和remainingRounds判断任务是否过期
public void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
//遍历格子中的所有定时任务
while (timeout != null) {
// 先保存next,因为移除后next将被设置为null
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
//从bucket链表中移除当前timeout,并返回链表中下一个timeout
next = remove(timeout);
//如果timeout的时间小于当前的时间,那么就调用expire执行task
if (timeout.deadline <= deadline) {
timeout.expire();
} else {
//不可能发生的情况,就是说round已经为0了,deadline却>当前槽的deadline
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)",
timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
next = remove(timeout);
} else {
//因为当前的槽位已经过了,说明已经走了一圈了,把轮数减一
timeout.remainingRounds--;
}
//把指针放置到下一个timeout
timeout = next;
}
}expireTimeouts方法会根据当前tick到的槽位,然后获取槽位中的bucket并找到链表中到期的timeout并执行
- 因为每一次的指针都会指向bucket中的下一个timeout,所以timeout为空时说明整个链表已经遍历完毕,所以用while循环做非空校验
- 因为没一次循环都会把当前的轮数大于零的做减一处理,所以当轮数小于或等于零的时候就需要把当前的timeout移除bucket链表
- 在校验deadline之后执行expire方法,这里会真正进行任务调用
HashedWheelTimeout#task
public void expire() {
if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {
return;
}
try {
task.run(this);
} catch (Throwable t) {
if (LOG.isWarnEnabled()) {
LOG.warn("An exception was thrown by " + TimerTask.class.getSimpleName() + '.', t);
}
}
}这里这个task就是在schedule方法中构建的timerTask实例,调用timerTask的run方法会调用到外层的RepeatedTimer的run方法,从而调用到RepeatedTimer子类实现的onTrigger方法。
到这里Jraft的定时调度就讲完了,感觉还是很有意思的。