什么是列式存储数据库
我们平时见到的最多的就是行式存储数据库,如:MySQL、PostgreSQL等,它们通常是将属于同一行的值存储在一起,它的布局非常的像我们 Excel 表格的布局,比如下面面向行的数据库存储用户数据:
|ID|Name |Birth Date|Phone Number|
|10|John |1-Aug-82 |1111 222 333|
|20|Sam |14-Sep-88 |5553 888 999|
|30|Keith|7-Jan-84 |3333 444 555|在需要按行访问数据的情况下,面向行的存储最有用,将整行存储在一起可以提高空间局部性。因为对磁盘来说不管是 HDD 还是 SSD 通常都是按块访问的,所以单个块可能将包含某行中所有列的数据。这对于我们希望访问整个用户记录的情况非常有用,但这样存储布局会使访问多个用户记录某个字段的查询开销更大,因为其他字段的数据在这个过程中也会被读入。
比如上面这个用户表的数据,我这样查询:
select Name from user;我只需要 Name 这个字段,但是每次都会都会逐行扫描、并获取每行数据的全部字段,然后返回 Name 字段。这是由行式存储的存储方式决定一定需要这样做。
而对于列式存储数据库同一列的值被连续的存储在磁盘上,例如我们想要存储股票市场的历史价格,那么股票这一列的数据便会被存储在一起。将同一列的值存储在一起可以便于按列查询,不需要对整行进行读取后再丢弃掉不需要的列。列式存储数据库非常适合计算聚合的分析型需求,如查找趋势、计算平均值等。
所以列式存储数据库的存储布局由于需要按列存储,所以很容易你可以想到,最简单的列存储引擎数据可能长这样:
Name: 10:John;20:Sam;30:Keith
Birth Date: 10:1-Aug-82;20:14-Sep-88;30:7-Jan-84
Phone Number: 10:1111 222 333;20:5553 888 999;30:3333 444 555那么我们如果只查询 Name 这个字段,列式存储数据库就可以直接扫描 Name 这列数据的文件并返回,从而避免了多余的数据扫描。
ClickHouse 简介
ClickHouse 是一个开源的列式数据库管理系统(DBMS),专门设计用于在线分析处理查询(OLAP)。由俄罗斯的Yandex公司开发,首次发布于2016年,它的主要目标是快速进行数据分析。也就是说 ClickHouse 主要用于在大数据的场景下做一些实时的数据分析。
得益于列式存储的特性,以及 ClickHouse 做的诸多优化,使得它在批量查询分析上面非常的具有优势。 对一张拥有 133 个字段的数据表分别在 1000 万、1 亿和 10 亿三种数据体量下执行基准测试,基准测试的范围涵盖 43 项SQL查询。在 1 亿数据级体量的情况下,ClickHouse 的平均响应速度是 Vertica 的2.63倍、InfiniDB 的 17 倍、MonetDB 的 27 倍、Hive 的 126 倍、MySQL 的 429 倍以及 Greenplum 的 10 倍。
具体的Benchmark可以看这里:https://benchmark.clickhouse.com/,这里随便放一下对比差异:

基于 ClickHouse 这么快的查询和分析速度,所以一般可以用来:
- 数据分析
- 数据挖掘
- 日志分析
Clickhouse是一个支持多种数据存储引擎的数据库。它可以将几乎任何数据源导入Clickhouse数据库,并支持快速灵活的下钻分析。例如,微信目前使用Clickhouse来存储日志数据,因为日志通常包含大量重复项。使用Clickhouse可以实现高压缩比,减少日志占用的存储空间。Cloudflare、Mux、Plausible、GraphCDN和PanelBear等公司使用Clickhouse来存储流量数据,并在其仪表板中向用户呈现相关报告。Percona也在使用Clickhouse来存储和分析数据库性能指标。
但是 Clickhouse 不能替代关系数据,ClickHouse 不支持事务,并且希望数据保持不变,尽管从技术上讲可以从ClickHouse数据库中删除大块数据,但速度并不快。ClickHouse根本不是为数据修改而设计的。由于稀疏索引,按键查找和检索单行的效率也很低。
ClickHouse 数据存储 & 索引
ClickHouse 的数据全都在 /var/lib/clickhouse/data 这个目录下面,比如我按照官网教程 https://clickhouse.com/docs/en/getting-started/example-datasets/ontime#creating-a-table 创建一个这样的表:
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0; 在这个表里面我们指定了一个复合主键(UserID, URL),排序键(UserID, URL, EventTime)。如果只指定排序键,那么主键会被隐式设置为排序键。如果同时指定了主键和排序键,则主键必须是排序键的前缀。
执行成功后会在文件系统 /var/lib/clickhouse/data/default/hits_UserID_URL 中创建如下的目录结构:
.
├── all_1_1_0
...
│ ├── primary.cidx
│ ├── URL.bin
│ ├── URL.cmrk
│ ├── UserID.bin
│ └── UserID.cmrk
├── all_1_7_1
...
│ ├── primary.cidx
│ ├── serialization.json
│ ├── URL.bin
│ ├── URL.cmrk
│ ├── UserID.bin
│ └── UserID.cmrk
├── detached
└── format_version.txt/var/lib/clickhouse/data 目录里面的一层 default 表示 database 名称,没有指定默认就是default,然后再往里面就是 hits_UserID_URL 表示表名,all_1_1_0 表示分区目录。
然后就是列字段相关的文件了,每列都会有两个字段:
{column}.bin:列数据的存储文件,以列名+bin为文件名,默认设置采用 lz4 压缩格式;
{column}.cmrk:列数据的标记信息,记录了数据块在 bin 文件中的偏移量;
primary.cidx:这个是主键索引相关的文件的,用于存放稀疏索引的数据。通过查询条件与稀疏索引能够快速的过滤无用的数据,减少需要加载的数据量。
因为我们设定了主键和排序键,所以数据在写入的时候会按照 UserID、URL、EventTime 顺序写入到bin 文件里面:

因为主键的顺序和文件的写入是相关的,所以一张表也只能有一个主键。
最小数据集 granule
出于数据处理的目的,表的列值在逻辑上被划分为 granule。granule 是为进行数据处理而流式传输到ClickHouse中的最小的不可分数据集。这意味着ClickHouse不是读取单个行,而是始终读取(以流式传输方式并行读取)整个组(granule)行数据。
比如我们上面在创建表的时候指定了 index_granularity 为 8192,即数据将会以 8192 行为一个组,表里面我们插入了 886w 条数据,那么就分为了 1083 个组:
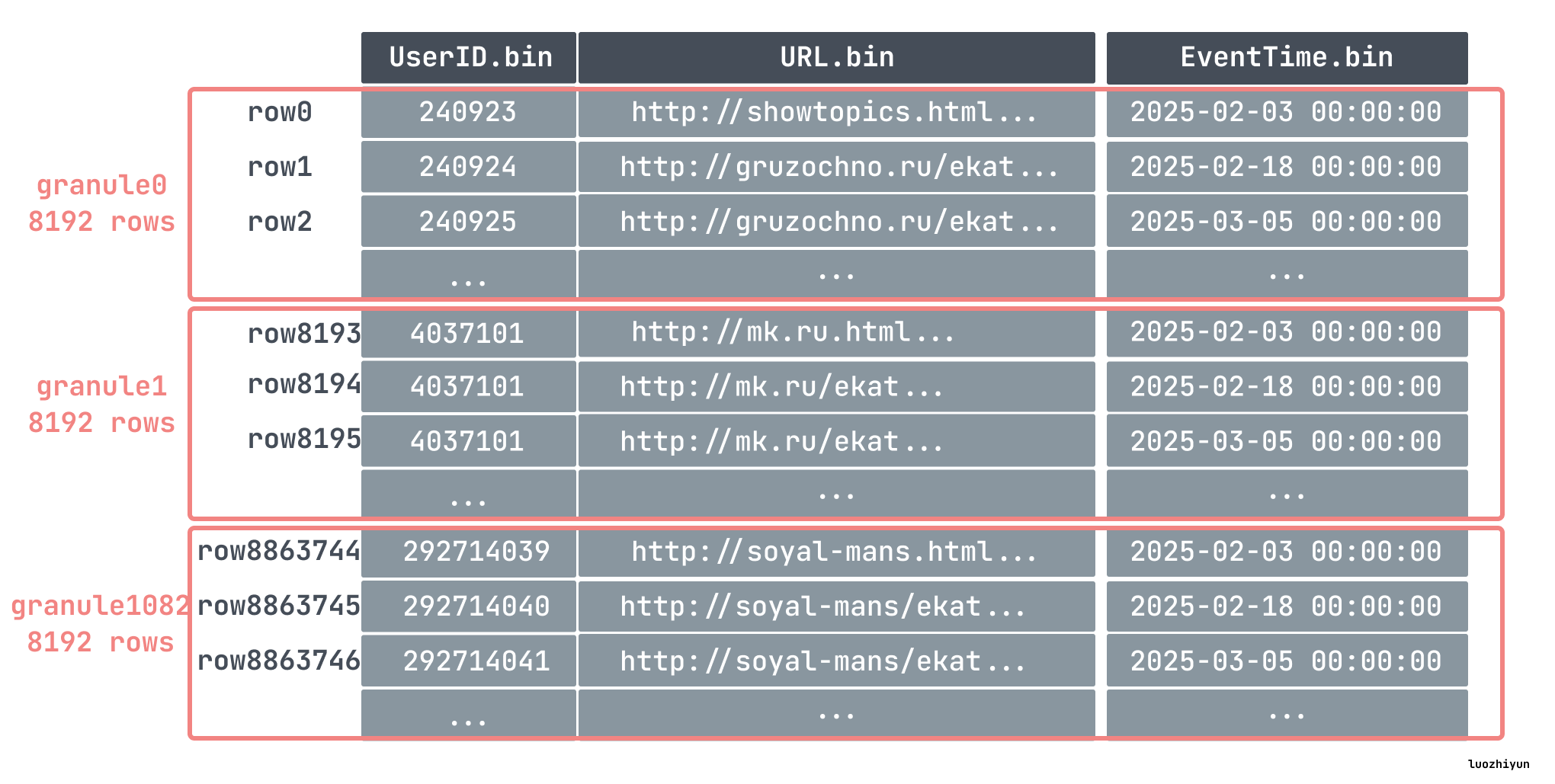
每个 granule 分组的第一条数据会被写入到 primary.cidx 当作索引处理。
主键索引 primary.cidx
ClickHouse 是通过稀疏索引的方式来构建主键索引的,所以它只记录 granule 的开始位置,一条索引记录就能标记大量的数据。所以像我们上面的例子中,886w 条数据,只有 1083 个 granule ,那么索引数量也只有 1083 条,索引少占用的空间就小,所以对 ClickHouse 而言,primary.cidx 中的数据是可以常驻内存。
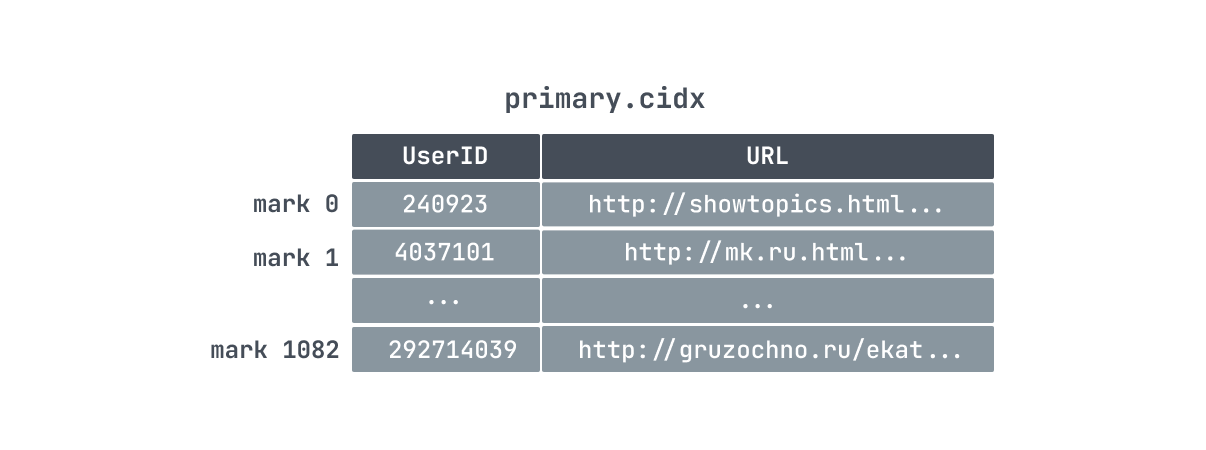
再加上数据存储的时候就是顺序存储,所以 ClickHouse 在利用索引过滤查找数据的时候可以用二分查找快速的定位到索引数据位置。
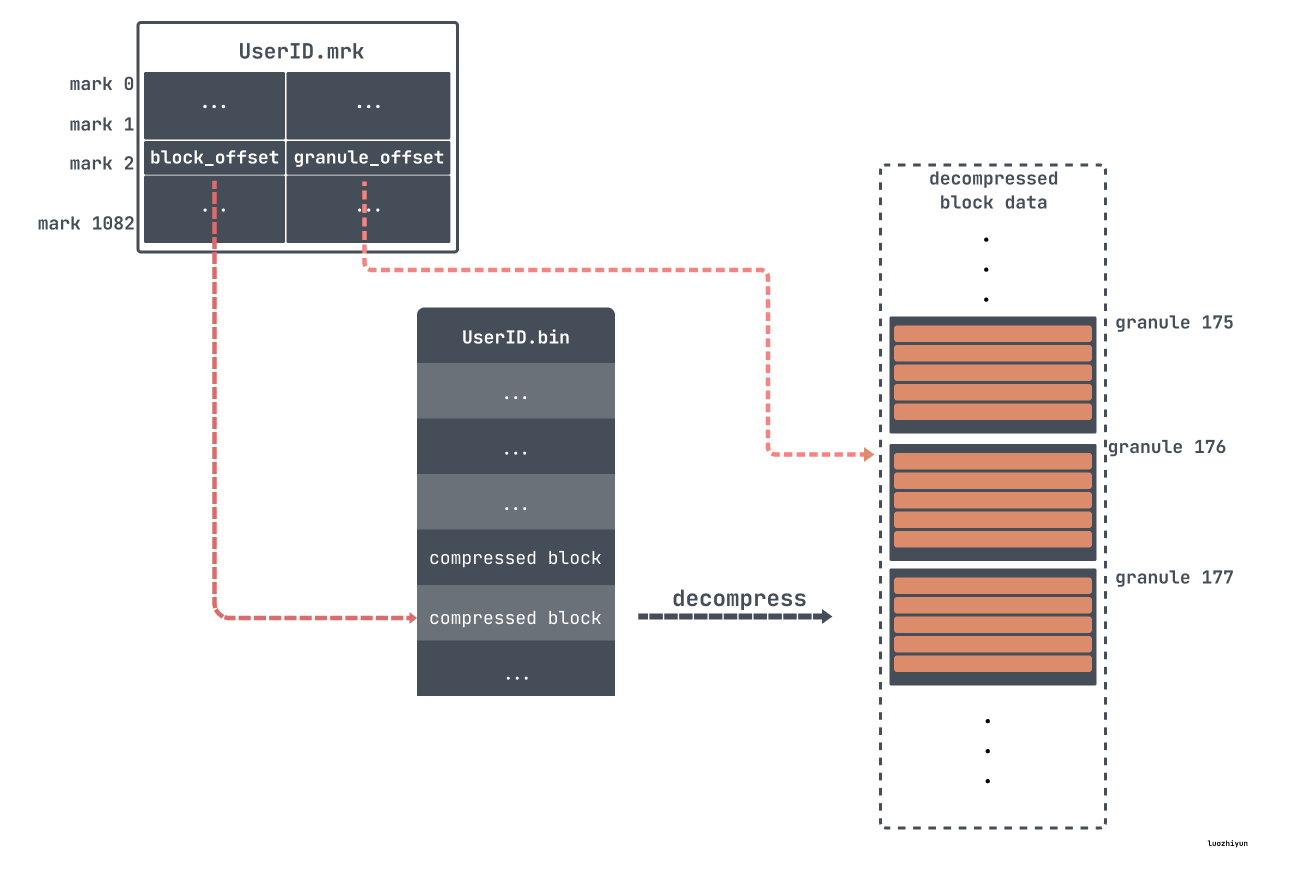
但是由于 granule 是个逻辑数据块,我们并不直接知道它在数据文件(.bin)中的存储位置。因此,我们还需要一个文件用来定位 granule,这就是标记(.mrk)文件。
标记文件 .mrk
这里需要说明一下,根据 ClickHouse 版本、数据情况、压缩格式,标记文件会有不同的结尾,如:cmrk 、cmrk2、mrk2、mrk3 等等,由于它们的作用都是用来做文件映射,找到数据的物理地址用的,所以这里都叫它们 mrk 标记文件好了。
对于 mrk 标记文件每一行包含了两部分的信息,block offset 以及 granule offset,在 bin 文件中,为了减少数据文件大小,数据需要进行压缩存储。如果直接将整个文件压缩,则查询时必须读取整个文件进行解压,显然如果需要查询的数据集比较小,这样做的开销就会显得特别大。因此,数据是以块(Block) 为单位进行压缩,一个压缩数据块可以包含若干个 granule 的数据,如下:

比如上面我们通过 primary.cidx 找到了对应数据所在 mark176,然后就可以对应的去 mrk 里面找对应的 block offset 和 granule offset。然后通过 block offset 找到该数据文件包含的压缩数据。一旦所定位的文件块被解压缩到主内存中,就可以使用标记文件的 granule offset 在未压缩的数据中定位对应的数据。
联合主键查询
像我们上面的例子中,key 设定的是 UserID, URL 两个字段,这种 key 被称为联合主键。机遇我们上面给出的 ClickHouse 主键索引构造的方式可以很容易想到,如果 where 条件里面包含了联合主键的第一个键列,那么ClickHouse可以使用二分查找法进行快速的索引。
但是,当查询过滤的列是联合主键的一部分,但不是第一个键列时会发生什么?比如我们 where 条件里面只写了 URL='xxx',那么ClickHouse会执行全表扫描,因为数据是首先按 UserID 排列,当 UserID 相同时,才会按照 URL 排列,那么URL可能分布在各个地方。
delete & update 操作
前面我们也说了,ClickHouse 主键或排序键都是按照顺序存储,然后按 block 进行压缩存储,那么如果删除又是怎样做的呢?
Clickhouse是个分析型数据库。这种场景下,数据一般是不变的,因此Clickhouse对update、delete的支持是比较弱的。标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果,而Clickhouse的update、delete是通过异步方式实现的。
对于删除操作来说有两种方式 DELETE FROM和ALTER…DELETE。
对于 DELETE FROM 操作操作来说,只是对已经删除的数据做了个标记,表示已经删了,并将自动从所有后续查询中过滤出来。但是,在下一次数据合并整理期间会清理数据。因此,在可能存在一定的时间段内,数据可能不会从存储中实际删除,而只是标记为已删除。这种删除属于轻量级删除,这种方式的缺点是数据并没有立即从磁盘种被清理。
执行删除时,ClickHouse为每一行保存一个掩码,指示它是否在 _row_exists 列中被删除。后续查询反过来会排除那些已删除的行。
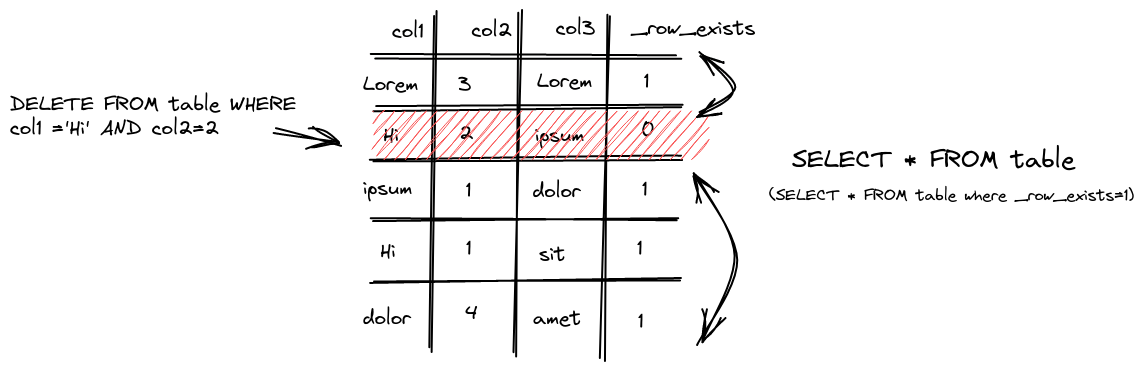
对于立即需要从磁盘中清理需求,可以通过使用ALTER…DELETE操作:
alter table hits_UserID_URL delete where UserID = 240923ALTER…DELETE操作默认情况是异步执行的,我们可以通过 system.mutations 表执行监控:
SELECT
command,
is_done
FROM system.mutations
WHERE `table` = 'hits_UserID_URL'
Query id: 78c3169a-abbc-415a-bcb2-0377d29fa547
┌─command──────────────────────┬─is_done─┐
│ DELETE WHERE UserID = 240923 │ 1 │
└──────────────────────────────┴─────────┘如果 is_done 的值为 0 ,表示它仍在执行中, is_done 的值为 1表示执行完毕。
对于 update 来说,主键的列或者排序键的值就不能被更改了,这是因为更改键列的值可能会需要重写大量的数据和索引,这对于一个以高性能读操作为设计目标的列式数据库来说,是非常低效的。所以只能修改非主键的列或者排序键的值。更新ClickHouse表中数据的最简单方法是使用ALTER… UPDATE语句。
ALTER TABLE hits_UserID_URL
UPDATE col1 = 'Hi' WHERE UserID = 240923 ALTER… UPDATE操作和ALTER…DELETE一样都同属于 mutation 操作,都是异步的。那么对于异步的方式来更新删除数据,就会涉及到一致性的问题。
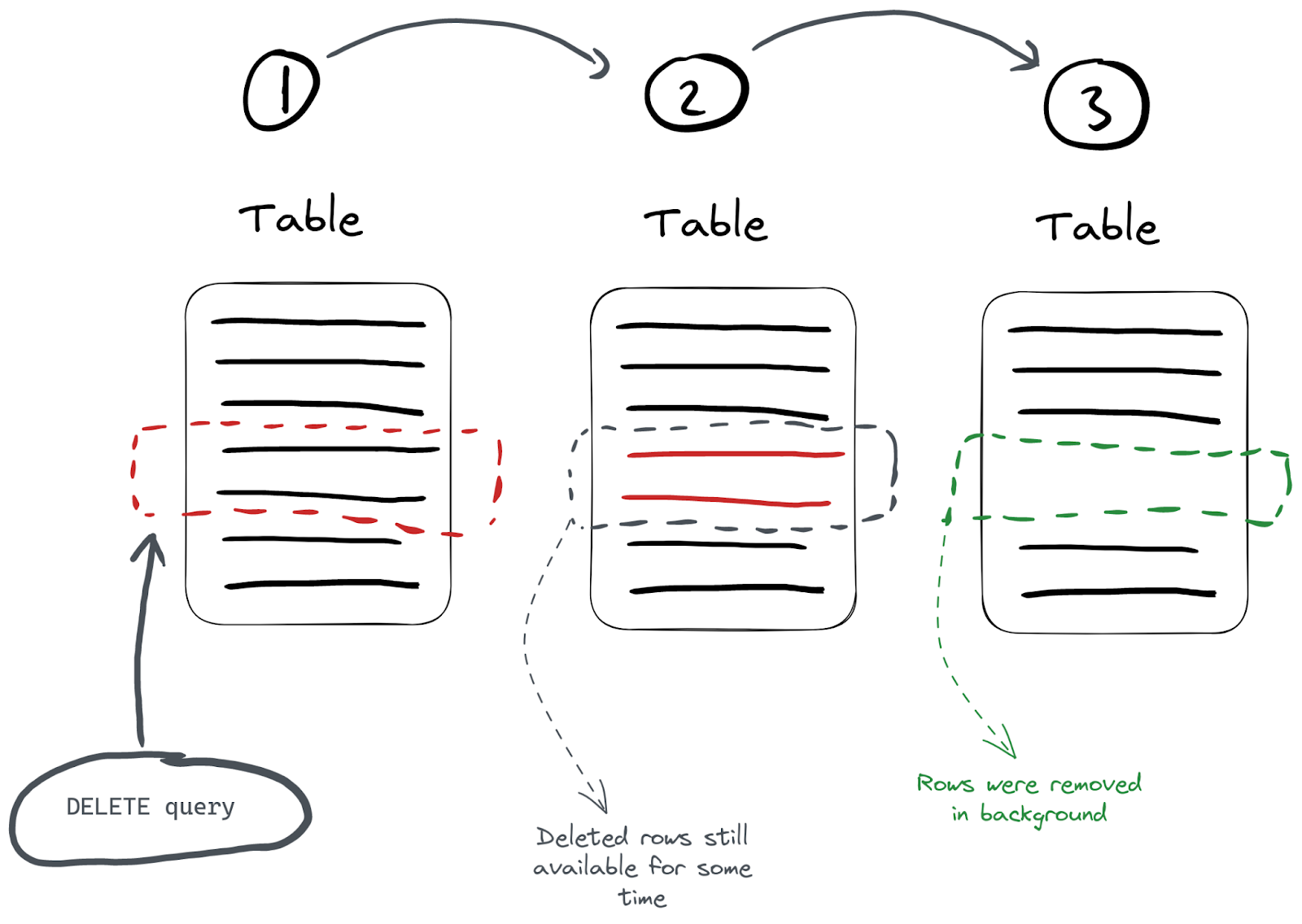
像上图所示,mutation 操作具体过程实际上分为这么几步:
- 使用where条件找到需要修改的分区;
- 重建每个分区;
- 用新的分区替换旧的;
数据的重建替换不是全部同时执行的,而是分批执行的。
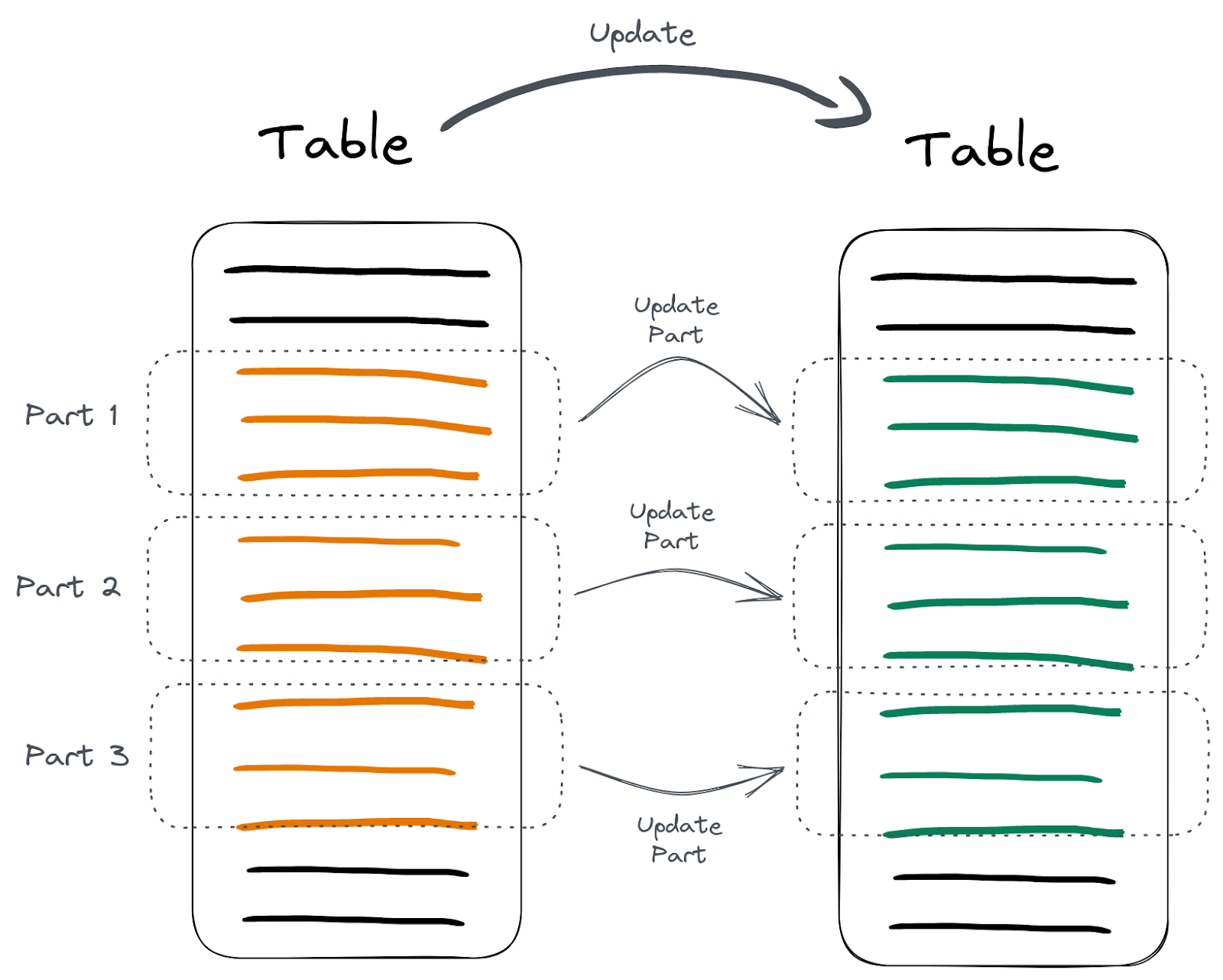
如果在重建替换的过程中,用户去查询数据,如果查询跨越了部分已经被更新的数据段和部分尚未被更新的数据段,用户可能会同时看到旧数据和新数据,也就是说ClickHouse是不做原子性保证的。
按照官方的说明,update/delete 的使用场景是一次更新大量数据,也就是where条件筛选的结果应该是一大片数据。
总结
通过上面ClickHouse的分析我们大概知道了列式数据库有啥优缺点,优点是可以忽略不需要的字段查询非常快,数据可以压缩,索引使用稀疏索引的方式不需要占用很多空间,可以支持超大量的数据分析;缺点是没有事务,对于单行数据的查询效率并不高,删除修改效率很低。所以在选型上面可以根据自己的业务需求,如果是有大量数据分析的需求,不妨试一下 ClickHouse。
Reference
《Database Internals A Deep-Dive into How Distributed Data Systems Work》
https://clickhouse.com/docs/en/optimize/sparse-primary-indexes
https://www.cnblogs.com/traditional/p/15218565.html
https://xie.infoq.cn/article/9f325fb7ddc5d12362f4c88a8
https://zhuanlan.zhihu.com/p/646518360
https://chistadata.com/why-clickhouse-is-so-fast/
https://clickhouse.com/docs/zh/guides/improving-query-performance/skipping-indexes
https://clickhouse.com/blog/handling-updates-and-deletes-in-clickhouse
https://altinitydb.medium.com/updates-and-deletes-in-clickhouse-d5df6f336ce9
