像经常用 LLM 的同学都知道现在最头疼的问题就是幻觉问题,在金融或精密计算领域,不确定性意味着风险。 如果 Agent 负责分析 NVDA 或 TSLA 的财报,开发者希望它在处理相同数据时,逻辑推导链条是严密的,而不是在不同时间给出自相矛盾的结论。或是需要 LLM 输出 JSON 来触发一个 API,我们不会希望 LLM 在 JSON 里多加了一个逗号或改变了字段名。
最后我还尝试用 LangGraph 的理念自己写了一个 smallest-LangGraph,
LangGraph 可以做什么?
传统的 LangChain 核心逻辑是 DAG(有向无环图)。我们可以轻松定义 A -> B -> C 的步骤,但如果你想让 AI 在 B 步骤发现结果不满意,自动跳回 A 重新执行,LangChain 的普通 Chain 很难优雅地实现。并且在复杂的长对话或多步骤任务中,维护一个全局的、可持久化的“状态快照”非常困难。
所以为了解决这些问题,LangGraph 就诞生了。LangGraph 的主要有这些核心优势:
-
支持“循环(Cycles)”与“迭代”
思考 -> 2. 行动 -> 3. 观察结果 -> 4. 如果不满意,回到第1步。 LangGraph 允许你定义这种闭环逻辑,这在长任务、自我修正代码、多轮调研场景下是刚需。
-
状态管理
LangGraph 引入了
State的概念,所有节点共享同一个TypedDict,你可以精确定义哪些数据是追加的(operator.add),哪些是覆盖的。并且它可以自动保存每一步的状态。即使程序崩溃或需要人工审核,你也可以从特定的“存档点”恢复,而不需要从头运行。 -
人机协作
LangGraph 允许你将流程设计为“在某处强制停下”,等待人类信号后再继续。这在 LangChain 的线性模型中极难实现,但在 LangGraph 的状态机模型中只是一个节点属性。
-
高度可控
“如果工具返回报错,必须走 A 路径。” 这种确定性对于生产环境的后端服务至关重要。不能让模型乱输出,在生产环境上严格把控输出结果是很重要的。
LangGraph 结构
由于 LangGraph 的核心思想是将 Agent 的工作流建模为一张有向图(Directed Graph)。所以 LangGraph 有如下几个结构组成
-
全局状态(State)
这个状态通常被定义为一个 Python 的
TypedDict,它可以包含任何你需要追踪的信息,如对话历史、中间结果、迭代次数等,所有的节点都能读取和更新这个中心状态。 -
节点(Nodes)
每个节点都是一个接收当前状态作为输入、并返回一个更新后的状态作为输出的 Python 函数。
-
边(Edges)
边负责连接节点,定义工作流的方向。最简单的边是常规边,它指定了一个节点的输出总是流向另一个固定的节点。而 LangGraph 最强大的功能在于条件边(Conditional Edges)。它通过一个函数来判断当前的状态,然后动态地决定下一步应该跳转到哪个节点。
基于上面的概念,我们来做一个例子,假设我们要开发一个 Agent:它先翻译一段话,然后自己检查是否有语法错误,如果有,就打回重新翻译;如果没有,就结束。
首先,我们先定义状态 (State):
from typing import TypedDict, List
class AgentState(TypedDict):
# 原始文本
input_text: str
# 翻译后的文本
translated_text: str
# 反思反馈
feedback: str
# 循环次数(防止死循环)
iterations: int定义节点逻辑 (Nodes):
def translator_node(state: AgentState):
print("--- 正在翻译 ---")
# 这里通常会调用 LLM
new_text = f"Translated: {state['input_text']}"
return {"translated_text": new_text, "iterations": state.get("iterations", 0) + 1}
def critic_node(state: AgentState):
print("--- 正在自检 ---")
# 模拟检查逻辑,如果包含 'bad' 字符就认为不合格
if "bad" in state['translated_text']:
return {"feedback": "发现不当词汇,请重试"}
return {"feedback": "OK"}定义路由逻辑 (Conditional Edges):
def should_continue(state: AgentState):
if state["feedback"] == "OK" or state["iterations"] > 3:
return "end"
else:
return "rephrase"构建图 (Graph Construction):
from langgraph.graph import StateGraph, END
# 1. 初始化图
workflow = StateGraph(AgentState)
# 2. 添加节点
workflow.add_node("translator", translator_node)
workflow.add_node("critic", critic_node)
# 3. 设置入口点
workflow.set_entry_point("translator")
# 4. 连接节点
workflow.add_edge("translator", "critic")
# 5. 添加条件边 (根据 critic 的反馈决定去向)
workflow.add_conditional_edges(
"critic",
should_continue,
{
"rephrase": "translator", # 如果不 OK,回到翻译节点
"end": END # 如果 OK,结束
}
)
# 6. 编译成可执行应用
app = workflow.compile()通过上面这种编排方式,可以让 LLM 概率性输出产生确定性的输出,通过各种限制节点,很好的控制了 LLM 的访问的节点。
下面我给出完整的例子,大家可以用这个例子去尝试一下:
from typing import TypedDict, List
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
from langchain_core.messages import SystemMessage, HumanMessage
llm = ChatOpenAI(
temperature=0.6,
model="glm-4.6V",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
class AgentState(TypedDict):
# 原始文本
input_text: str
# 翻译后的文本
translated_text: str
# 反思反馈
feedback: str
# 循环次数(防止死循环)
iterations: int
def translator_node(state: AgentState):
"""翻译节点:负责将中文翻译成英文"""
print(f"\n--- [节点:翻译器] 第 {state.get('iterations', 0) + 1} 次尝试 ---")
iters = state.get("iterations", 0)
feedback = state.get("feedback", "无")
# 构建提示词:如果是重试,带上反馈建议
system_prompt = "你是一个专业的翻译官。请将用户的中文翻译成地道、优雅的英文。"
if iters > 0:
system_prompt += f" 注意:这是第二次尝试,请参考之前的反馈进行改进:{feedback}"
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=state["input_text"])
])
return {
"translated_text": response.content,
"iterations": iters + 1
}
def critic_node(state: AgentState):
"""评审节点:检查翻译质量"""
print("--- [节点:评审员] 正在检查翻译质量... ---")
system_prompt = (
"你是一个严苛的英文编辑。请评价以下翻译是否准确、地道。"
"如果翻译得很好,请只回复关键词:【PASS】。"
"如果翻译有改进空间,请直接指出问题并给出改进建议。"
)
user_content = f"原文:{state['input_text']}\n译文:{state['translated_text']}"
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=user_content)
])
return {"feedback": response.content}
# 4. 定义路由逻辑
def should_continue(state: AgentState):
"""判断是继续修改还是直接结束"""
if "【PASS】" in state["feedback"] or state["iterations"] >= 3:
if state["iterations"] >= 3:
print("!!! 达到最大尝试次数,停止优化。")
return "end"
else:
print(f">>> 反馈建议:{state['feedback']}")
return "rephrase"
# 1. 初始化图
workflow = StateGraph(AgentState)
# 2. 添加节点
workflow.add_node("translator", translator_node)
workflow.add_node("critic", critic_node)
# 3. 设置入口点
workflow.set_entry_point("translator")
# 4. 连接节点
workflow.add_edge("translator", "critic")
# 5. 添加条件边 (根据 critic 的反馈决定去向)
workflow.add_conditional_edges(
"critic",
should_continue,
{
"rephrase": "translator", # 如果不 OK,回到翻译节点
"end": END # 如果 OK,结束
}
)
# 6. 编译成可执行应用
app = workflow.compile()
# 7. 运行时交互
if __name__ == "__main__":
print("=== LangGraph 智能翻译 Agent (输入 'exit' 退出) ===")
while True:
user_input = input("\n请输入想要翻译的中文内容: ")
if user_input.lower() == 'exit':
break
# 初始状态
initial_state = {
"input_text": user_input,
"iterations": 0
}
# 运行图并获取最终状态
final_state = app.invoke(initial_state)
print("\n" + "=" * 30)
print(f"最终翻译结果:\n{final_state['translated_text']}")
print("=" * 30)LangGraph 是如何管理状态的?
State Reducer 自动合并 state
Reducer 在 LangGraph 中就是一种更新状态的处理逻辑,如果没有指定默认行为是 用新值覆盖旧值。想要指定 Reducer 只需要通过 typing.Annotated 字段绑定一个 Reducer 函数即可。
比如使用 operator.add 定义这是一个“追加型”字段:
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, END
import operator
# 定义状态结构 (类似 Go 的 Struct)
class AgentState(TypedDict):
# 使用 Annotated 和 operator.add 定义这是一个“追加型”字段
# 每次节点返回消息,都会 append 到这个列表,而不是覆盖它
messages: Annotated[list[str], operator.add]
# 普通字段,默认行为是 Overwrite (覆盖)
# 适合存储状态机当前的步骤或分析结论
current_status: str
# 计数器,也可以使用 operator.add 实现增量累加
retry_count: Annotated[int, operator.add]Checkpointer + Thread 持久化状态
在 LangGraph 中,Checkpointer 是一个持久化层接口,这意味着历史的对话记录,可以被自动持久化到数据库(如 SQLite 或其他外部数据库)中。这使得即使应用程序重启或用户断开连接,对话历史也能被保存和恢复,从而实现“真正的多轮记忆”。
LangGraph 提供了多种 Checkpointer 以便应对不同的使用场景:
-
MemorySaver 保存在内存,适用开发调试、单元测试;
-
SqliteSaver 保存在本地的.db文件,轻量级应用、边缘计算适合单机部署;
-
PostgresSaver 保存在 PostgreSQL,适合用在生产环境、多实例部署;
-
RedisSaver 适合处理高频、短时会话;
LangGraph 通过 thread_id 会话的唯一标识,结合 Checkpointer 就可以实现状态的隔离:
首先指定一个 指定一个 thread_id,所有相关的状态都会被保存到这个线程中。
config = {"configurable": {"thread_id": "conversation_1"}}
graph.invoke(input_data, config)编译的时候传入 Checkpointer 即可。
# 创建 checkpointer
checkpointer = InMemorySaver()
# 编译图时传入 checkpointer
graph = builder.compile(checkpointer=checkpointer)完整示例:
from langgraph.checkpoint.memory import InMemorySaver
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END, MessagesState
llm = ChatOpenAI(
temperature=0.6,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 定义节点函数
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("agent", call_model)
builder.add_edge(START, "agent")
# 创建 checkpointer
checkpointer = InMemorySaver()
# 编译图时传入 checkpointer
graph = builder.compile(checkpointer=checkpointer)
# 第一次对话
config = {"configurable": {"thread_id": "user_123"}}
response1 = graph.invoke(
{"messages": [{"role": "user", "content": "你好,我的名字是张三"}]},
config
)
print(f"AI: {response1['messages'][-1].content}")
# 第二次对话(相同 thread_id)
response2 = graph.invoke(
{"messages": [{"role": "user", "content": "我的名字是什么?"}]},
config # 使用相同的 thread_id
)
print(f"AI: {response2['messages'][-1].content}")
# 获取当前的状态信息
print(f"AI: {graph.get_state(config)}")除此之外,可以 graph.get_state() / graph.get_state_history() 拿到当前/历史状态;也可以基于 checkpoint 做 replay、update_state(时间旅行能力通常要求启用 checkpointer)。
Super-step 原子循环单元
由于一个 node 也可以连接多个 node,多个 node 也可以连接到 一个 node,所以 LangGraph 设计了 Super-step 来作为原子循环单元。比如下面的例子:
graph.set_entry_point("n1")
graph.add_edge("n1", "n2")
graph.add_edge("n1", "n3")
graph.add_edge("n2", "n4")
graph.add_edge("n3", "n4")
graph.add_edge("n4", END)LangGraph 只分了三步就执行完了该循环。如下图,第二步的时候会 n2、n3 节点并行执行。

并且每个 super-step 都会自动保存一个 checkpoint,这就是持久化机制的基础。即使程序中断,也能从最后一个 super-step 的 checkpoint 恢复执行。
Human-in-the-loop 人机协同
Human-in-the-loop 本质上就是让 agent “关键时刻”暂停,它的底层靠的是 interrupt + 持久化(checkpoint):暂停时把状态存起来,恢复时从存档续跑。
比如我们想要是线一个场景就是让 AI 去判断是否应该要人工审核,如过需要人工审核,那么就 interrupt 进行中断,然后等人工输入之后根据执行逻辑进行恢复,然后配合Command(resume=...) 恢复。
基本流程可以是这样:
import uuid
from langgraph.types import interrupt, Command
def ask_human(state):
answer = interrupt("Do you approve?")
return {"approved": answer}
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
# 第一次跑:会中断,返回 __interrupt__
graph.invoke({"input": "x"}, config=config)
# 人给了答复后:用 Command(resume=...) 恢复
graph.invoke(Command(resume=True), config=config)这个例子中interrupt() 会暂停图执行,把一个值(必须可 JSON 序列化)抛给调用方,并依赖 checkpointer 持久化状态;然后你用同一个 thread_id 重新调用图,并传入 Command(resume=...) 来继续。
接下来我们看一个完整的例子,设计一个常见的场景,当模型觉得需要“找专家/找人类”时,会调用一个工具 human_assistance,而这个工具会用 interrupt() 把流程暂停下来,等你在命令行里输入专家建议后,再用 Command(resume=...) 把图唤醒继续跑。
from langgraph.checkpoint.memory import InMemorySaver
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict
from typing import Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.types import Command, interrupt
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(
temperature=0.6,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
class State(TypedDict):
messages: Annotated[list, add_messages]
@tool
def human_assistance(query: str) -> str:
"""Request assistance from a human."""
human_response = interrupt({"query": query})
return human_response["data"]
tools = [human_assistance]
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
message = llm_with_tools.invoke(state["messages"])
return {"messages": [message]}
tool_node = ToolNode(tools=tools)
graph_builder = StateGraph(State)
graph_builder.add_node("tools", tool_node)
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
memory = InMemorySaver()
graph = graph_builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "test_thread_123"}}
# 第一步:用户提出一个需要“人工协助”的问题
print("--- 第一阶段:AI 运行并遇到 interrupt ---")
initial_input = HumanMessage(content="你好,帮我找个专家回答我的问题")
for event in graph.stream({"messages": [initial_input]}, config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()
# 此时,你会发现程序停止了,因为它卡在 `human_assistance` 的 `interrupt` 处。
# 第二步:模拟人类(你)在一段时间后看到了请求并回复
print("\n--- 第二阶段:模拟人类介入并提供答案 ---")
# 我们构造一个 Command 对象来“唤醒”它
# resume 里的内容会直接成为 interrupt() 函数的返回值
expert_input = input("专家建议: ")
human_feedback = {"data": expert_input}
for event in graph.stream(
Command(resume=human_feedback), # 这里是恢复运行的关键
config,
stream_mode="values"
):
if "messages" in event:
event["messages"][-1].pretty_print()
snapshot = graph.get_state(config)
print(snapshot.values)LangGraph如何轻松实现 Agent 多种执行范式
ReAct
ReAct由Shunyu Yao于2022年提出[1],其核心思想是模仿人类解决问题的方式,将推理 (Reasoning) 与行动 (Acting) 显式地结合起来,形成一个“思考-行动-观察”的循环。
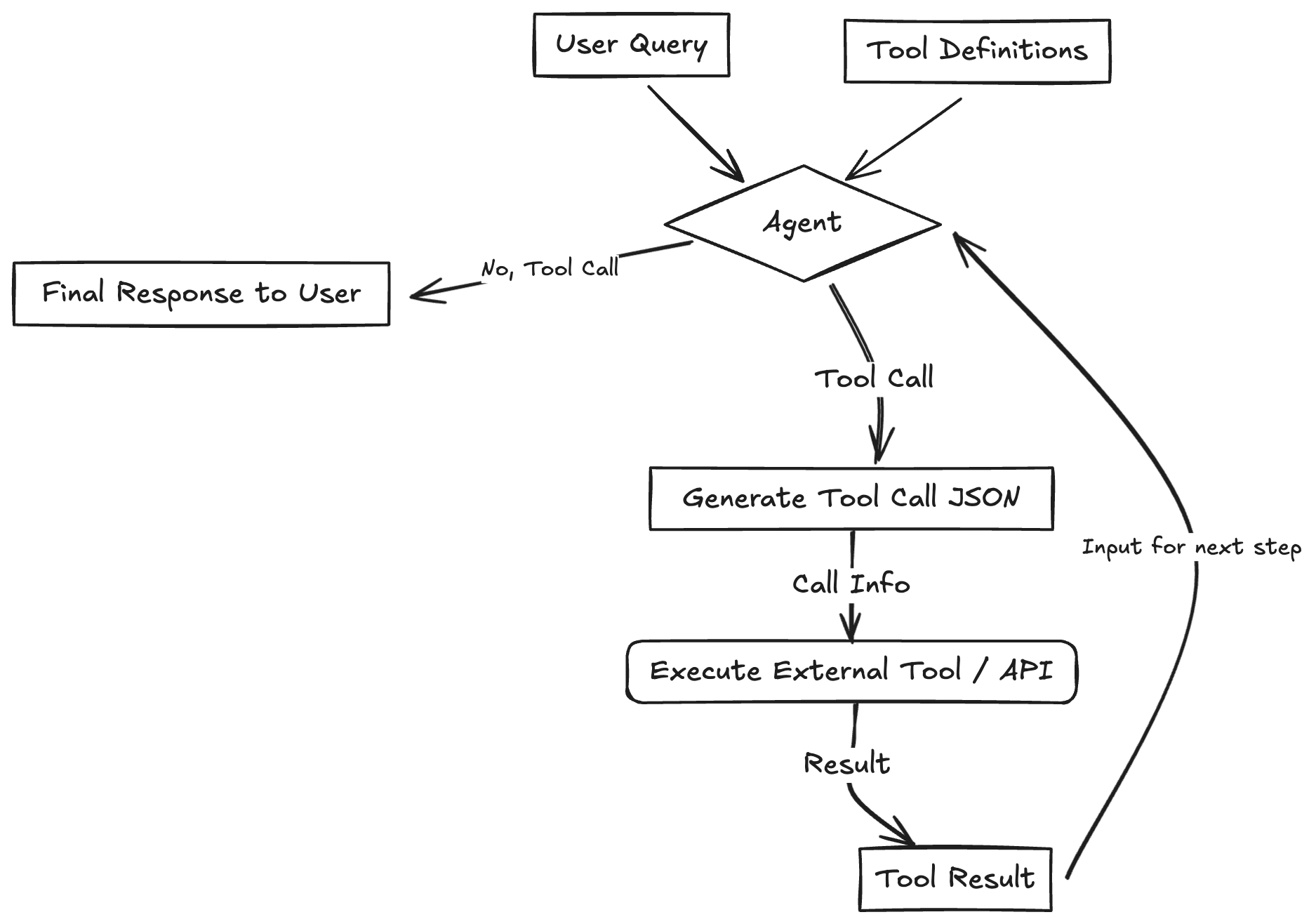
ReAct范式通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹:
- Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
- Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具API 。
- Observation (观察): 这是执行
Action后从外部工具返回的结果,例如或API的返回值。
智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
# --- 1. 双手:定义查天气的工具 ---
@tool
def get_weather(city: str):
"""查询指定城市的天气"""
# 这里模拟后端 API 返回数据
if "北京" in city:
return "晴天,25度"
return "阴天,20度"
tools = [get_weather]
tool_node = ToolNode(tools)
# --- 2. 记忆:定义存储对话的状态 ---
class State(TypedDict):
messages: Annotated[list, add_messages]
# --- 3. 大脑:定义思考逻辑 ---
model = ChatOpenAI(
temperature=0.6,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
).bind_tools(tools)
def call_model(state: State):
# 大脑看一眼目前的对话,决定是直接说话还是去用手拿工具
return {"messages": [model.invoke(state["messages"])]}
# --- 4. 路由:判断下一步是干活还是结束 ---
def should_continue(state: State):
last_message = state["messages"][-1]
# 如果大脑发出的指令包含“调用工具”,就去 tools 节点
if last_message.tool_calls:
return "tools"
# 如果大脑直接说话了,就结束
return END
# --- 5. 编排图(把脑和手连起来) ---
workflow = StateGraph(State)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
# 条件边:agent 运行完,判断是去 tools 还是结束
workflow.add_conditional_edges("agent", should_continue)
# 普通边:tools 运行完(干完活了),必须把结果拿回给 agent 看
workflow.add_edge("tools", "agent")
app = workflow.compile()
# --- 6. 执行测试 ---
for chunk in app.stream({"messages": [("user", "北京今天天气怎么样?")]}):
print(chunk)Plan-and-Solve
Plan-and-Solve 顾名思义,这种范式将任务处理明确地分为两个阶段:先规划 (Plan),后执行 (Solve)。Plan-and-Solve Prompting 由 Lei Wang 在2023年提出。其核心动机是为了解决思维链在处理多步骤、复杂问题时容易“偏离轨道”的问题。
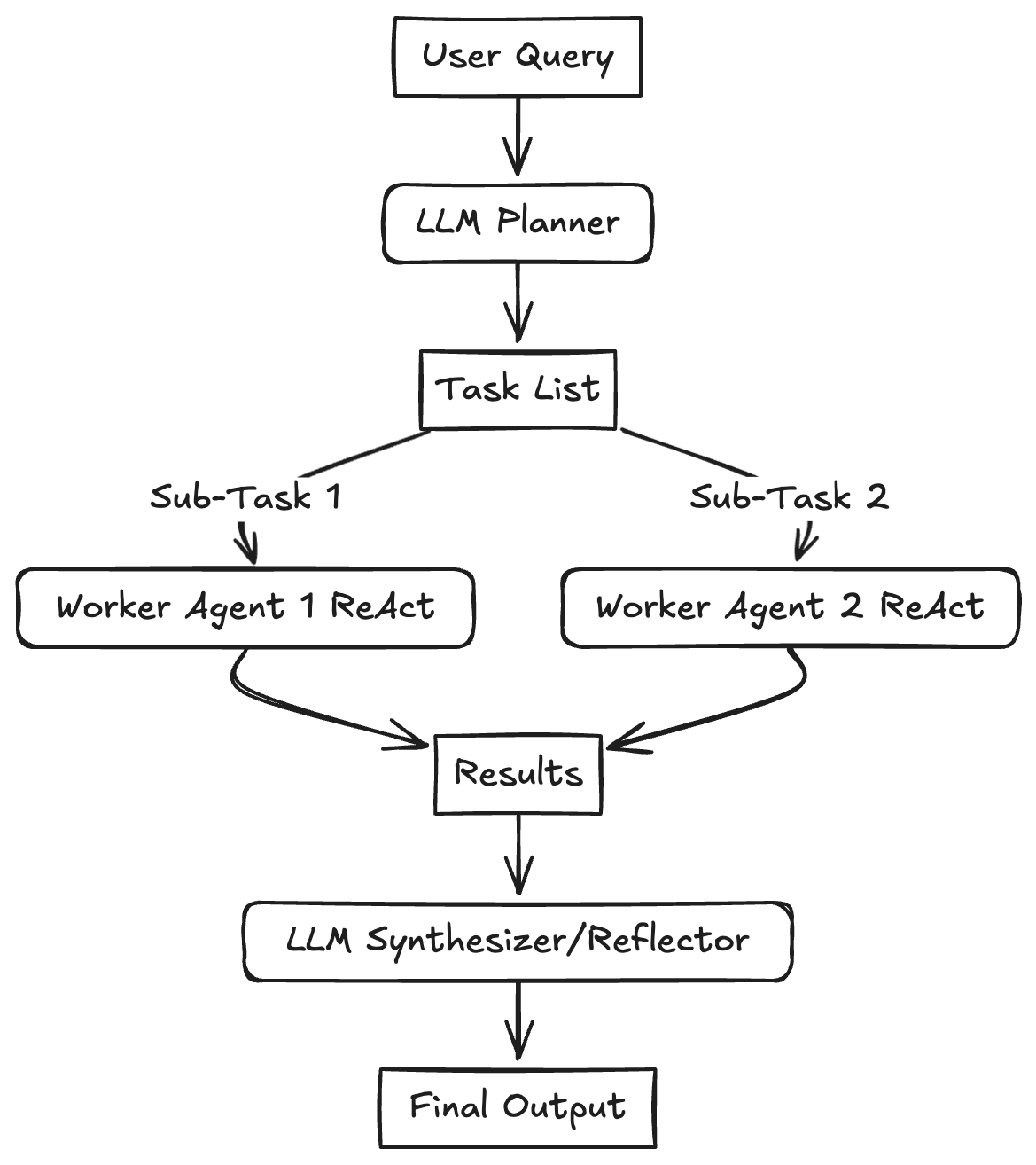
Plan-and-Solve 将整个流程解耦为两个核心阶段:
- 规划阶段 (Planning Phase): 首先,智能体会接收用户的完整问题。它的第一个任务不是直接去解决问题或调用工具,而是将问题分解,并制定出一个清晰、分步骤的行动计划。
- 执行阶段 (Solving Phase): 在获得完整的计划后,智能体进入执行阶段。它会严格按照计划中的步骤,逐一执行。每一步的执行都可能是一次独立的 LLM 调用,或者是对上一步结果的加工处理,直到计划中的所有步骤都完成,最终得出答案。
import operator
from typing import Annotated, List, Tuple, Union
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
# 1. 定义状态 (State)
class PlanExecuteState(TypedDict):
input: str # 原始问题
plan: List[str] # 当前待办清单
past_steps: Annotated[List[Tuple], operator.add] # 已完成的步骤和结果
response: str # 最终答案
# 2. 定义结构化输出模型 (用于 Planner)
class Plan(BaseModel):
"""步骤清单"""
steps: List[str] = Field(description="为了回答问题需要执行的步骤")
# 3. 定义节点逻辑
model = ChatOpenAI(
temperature=0.6,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
planner_model = model.with_structured_output(Plan, method="function_calling")
# --- 节点 A: 规划者 ---
def planner_node(state: PlanExecuteState):
plan = planner_model.invoke(f"针对以下问题制定计划: {state['input']}")
return {"plan": plan.steps}
# --- 节点 B: 执行者 (这里简化了工具调用) ---
def executor_node(state: PlanExecuteState):
step = state["plan"][0] # 取当前第一步
print(f"--- 正在执行: {step} ---")
# 模拟工具执行结果
result = f"已完成 {step} 的查询,结果为: [模拟数据]"
return {"past_steps": [(step, result)], "plan": state["plan"][1:]}
# --- 节点 C: 重规划者 (决定是继续还是结束) ---
def replanner_node(state: PlanExecuteState):
if not state["plan"]: # 如果清单空了,让 AI 生成最终总结
summary = model.invoke(
f"请基于已完成的步骤和结果给出最终答案:{state['past_steps']}"
)
return {"response": summary.content}
return {"response": None}
# 4. 路由逻辑
def should_continue(state: PlanExecuteState):
if state["response"]:
return END
return "executor"
# 5. 编排图
workflow = StateGraph(PlanExecuteState)
workflow.add_node("planner", planner_node)
workflow.add_node("executor", executor_node)
workflow.add_node("re-planner", replanner_node)
workflow.set_entry_point("planner")
workflow.add_edge("planner", "executor")
workflow.add_edge("executor", "re-planner")
# 循环逻辑:根据 re-planner 的判断决定是否回 executor
workflow.add_conditional_edges("re-planner", should_continue)
app = workflow.compile()
# 6. 测试
input_query = {"input": "对比北京和上海的天气,哪个更热?"}
for event in app.stream(input_query):
print(event)
Reflection
Reflection 机制的核心思想,正是为智能体引入一种事后(post-hoc)的自我校正循环,使其能够像人类一样,审视自己的工作,发现不足,并进行迭代优化。 Reflection 框架是Shinn, Noah 在2023年提出,其核心工作流程可以概括为一个简洁的三步循环:执行 -> 反思 -> 优化。
- 执行 (Execution):首先,智能体使用我们熟悉的方法(如 ReAct 或 Plan-and-Solve)尝试完成任务,生成一个初步的解决方案或行动轨迹。这可以看作是“初稿”。
- 反思 (Reflection):接着,智能体进入反思阶段。它会调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个“评审员”的角色。这个“评审员”会审视第一步生成的“初稿”,并从多个维度进行评估,例如:
- 事实性错误:是否存在与常识或已知事实相悖的内容?
- 逻辑漏洞:推理过程是否存在不连贯或矛盾之处?
- 效率问题:是否有更直接、更简洁的路径来完成任务?
- 遗漏信息:是否忽略了问题的某些关键约束或方面? 根据评估,它会生成一段结构化的反馈 (Feedback),指出具体的问题所在和改进建议。
- 优化 (Refinement):最后,智能体将“初稿”和“反馈”作为新的上下文,再次调用大语言模型,要求它根据反馈内容对初稿进行修正,生成一个更完善的“修订稿”。

from typing import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
class ReflectionState(TypedDict):
prompt: str
draft: str
critique: str
final: str
iteration: int
llm = ChatOpenAI(
temperature=0.6,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/",
)
MAX_ITERS = 2
def generate_draft(state: ReflectionState):
msg = llm.invoke(f"请写一段简短答案:{state['prompt']}")
return {"draft": msg.content, "iteration": 0}
def reflect_on_draft(state: ReflectionState):
prompt = (
"你是严格的审稿人。请指出这段答案的问题并给出改进建议。"
"如果没有明显问题,请只输出 NO_ISSUES。\n\n"
f"答案:\n{state['draft']}"
)
critique = llm.invoke(prompt)
print(f"--- 正在执行: reflect,critique:\n {critique.content} ---")
return {"critique": critique.content}
def revise_draft(state: ReflectionState):
prompt = (
"请根据以下反馈重写答案,保持简短清晰:\n\n"
f"反馈:\n{state['critique']}\n\n"
f"原答案:\n{state['draft']}"
)
revision = llm.invoke(prompt)
print(f"--- 正在执行: revise,原答案:\n{state['draft']},改进后:\n{revision.content} ---")
return {"draft": revision.content, "iteration": state["iteration"] + 1}
def finalize(state: ReflectionState):
return {"final": state["draft"]}
def should_reflect(state: ReflectionState):
if state["critique"].strip() == "NO_ISSUES":
return "finalize"
if state["iteration"] >= MAX_ITERS:
return "finalize"
return "revise"
workflow = StateGraph(ReflectionState)
workflow.add_node("generate", generate_draft)
workflow.add_node("reflect", reflect_on_draft)
workflow.add_node("revise", revise_draft)
workflow.add_node("finalize", finalize)
workflow.add_edge(START, "generate")
workflow.add_edge("generate", "reflect")
workflow.add_conditional_edges("reflect", should_reflect)
workflow.add_edge("revise", "reflect")
workflow.add_edge("finalize", END)
app = workflow.compile()
if __name__ == "__main__":
input_data = {"prompt": "用三句话解释什么是 LangGraph。"}
result = app.invoke(input_data)
print("最终答案:")
print(result["final"])
大致流程就是,首先里面需要有两个角色:写稿人和审稿人,然后用 should_reflect 来判断是否需要重写,然后用 MAX_ITERS 来限制一下最大撰写次数。
[START]
|
v
(generate_draft)
|
v
(reflect_on_draft) -- NO_ISSUES --> (finalize) --> [END]
|
| iteration >= MAX_ITERS
+-----------------------> (finalize) --> [END]
|
+-- else --> (revise_draft) --+
|
v
(reflect_on_draft)Multi-Agent Pattern
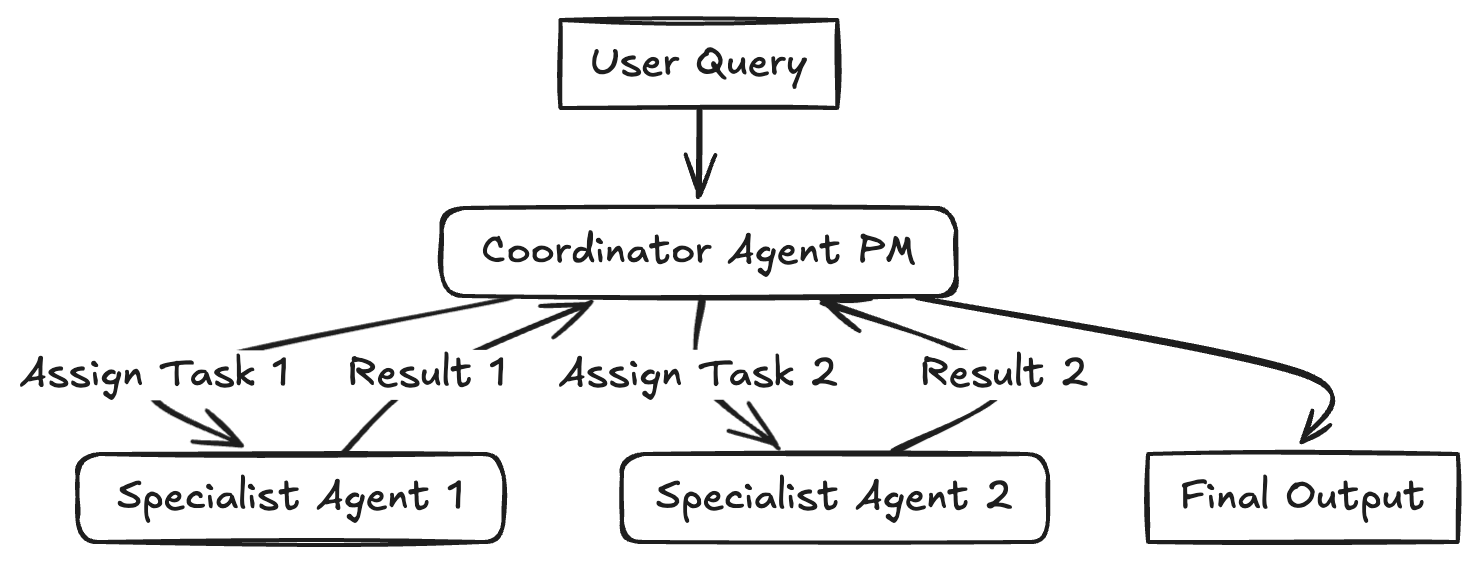
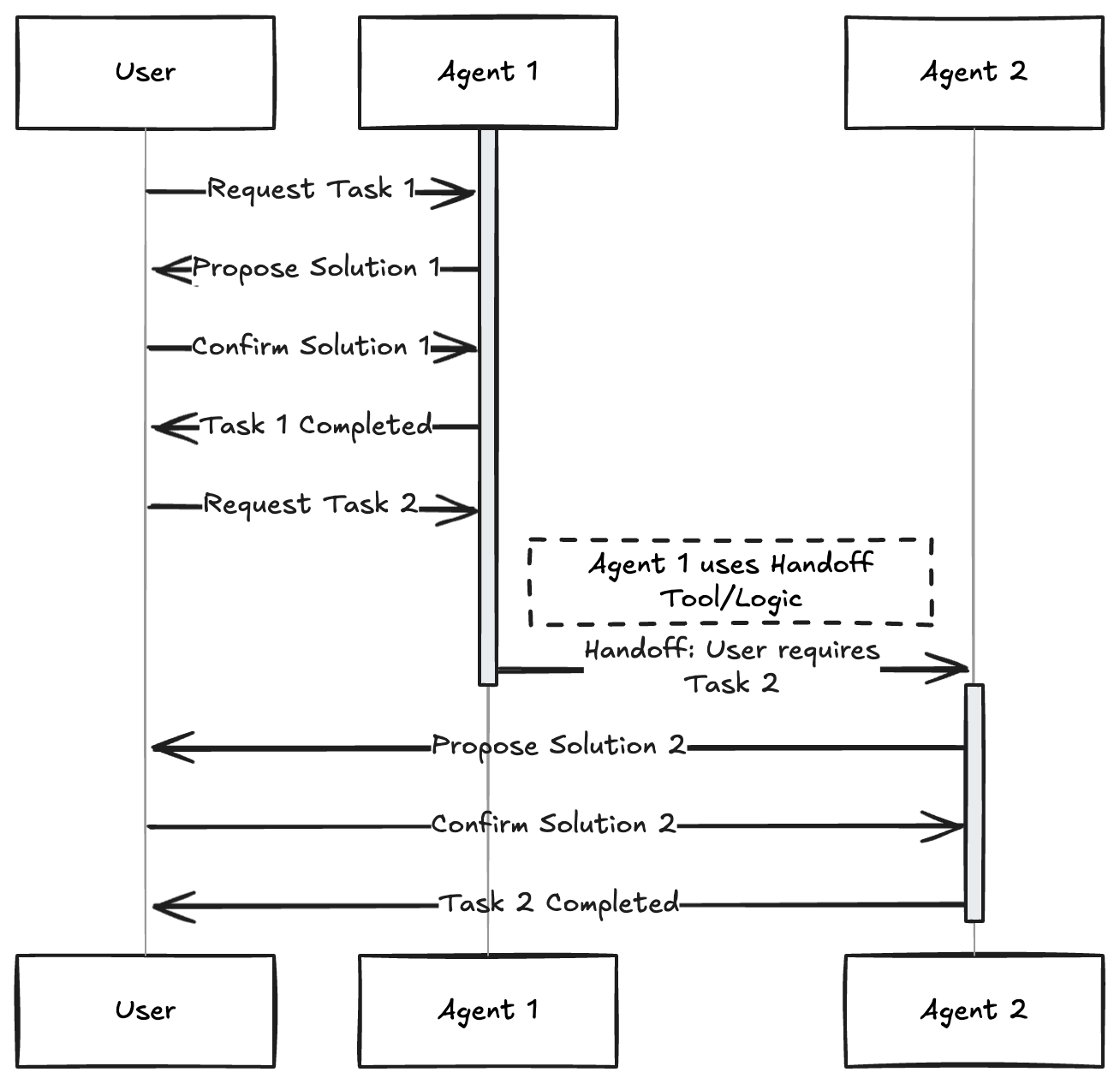
Multi-Agent 模式是将复杂的任务拆解为多个专门化、独立且可协同的微服务,每个服务(Agent)只负责一个特定的领域。
因为单个 Prompt 包含太多工具和指令会导致 LLM “迷失”,模型表现下降。所以通过使用doge Agent 进行职责分离,不同的 Agent 可以使用不同的 Prompt、不同的模型(如 GPT-4o 负责决策,Llama-3 负责写代码),甚至不同的工具集。
比如下面的例子中:一个“PM” Agent 负责拆解任务,并将子任务分发给不同的“员工(Workers)”。
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# Multi-agent pattern: a supervisor routes work between specialist agents.
llm = ChatOpenAI(
temperature=0.4,
model="glm-4.6v",
openai_api_key="",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/",
)
class State(TypedDict):
messages: Annotated[list, add_messages]
next: str
turn: int
MAX_TURNS = 6
def _call_agent(system_prompt: str, messages: list, name: str):
response = llm.invoke([{"role": "system", "content": system_prompt}] + messages)
return {
"messages": [
{"role": "assistant", "name": name, "content": response.content}
],
"turn": 1,
}
def supervisor(state: State):
if state["turn"] >= MAX_TURNS:
return {"next": "finish"}
system = (
"You are a supervisor managing a team: researcher, writer, critic. "
"Choose who should act next or finish. "
"Respond with exactly one word: researcher, writer, critic, finish."
)
response = llm.invoke([{"role": "system", "content": system}] + state["messages"])
decision = response.content.strip().lower()
for option in ("researcher", "writer", "critic", "finish"):
if option in decision:
return {"next": option}
return {"next": "finish"}
def researcher(state: State):
system = (
"You are a researcher. Gather key facts and constraints for the task. "
"Be concise and list only essential points."
)
return _call_agent(system, state["messages"], "researcher")
def writer(state: State):
system = (
"You are a writer. Produce a clear, structured response using the context. "
"If facts are missing, note assumptions."
)
return _call_agent(system, state["messages"], "writer")
def critic(state: State):
system = (
"You are a critic. Identify gaps, risks, or unclear parts in the draft, "
"then suggest improvements."
)
return _call_agent(system, state["messages"], "critic")
def route_next(state: State) -> Literal["researcher", "writer", "critic", "finish"]:
return state["next"]
builder = StateGraph(State)
builder.add_node("supervisor", supervisor)
builder.add_node("researcher", researcher)
builder.add_node("writer", writer)
builder.add_node("critic", critic)
builder.add_edge(START, "supervisor")
builder.add_conditional_edges(
"supervisor",
route_next,
{
"researcher": "researcher",
"writer": "writer",
"critic": "critic",
"finish": END,
},
)
builder.add_edge("researcher", "supervisor")
builder.add_edge("writer", "supervisor")
builder.add_edge("critic", "supervisor")
app = builder.compile()
if __name__ == "__main__":
user_input = "创建一款广告招商的帖子"
initial_state = {
"messages": [{"role": "user", "content": user_input}],
"next": "supervisor",
"turn": 0,
}
for event in app.stream(initial_state):
for value in event.values():
if "messages" in value:
msg = value["messages"][-1]
name = msg.get("name", "assistant")
print(f"[{name}] {msg['content']}")
Reference
https://datawhalechina.github.io/
https://www.philschmid.de/agentic-pattern
https://blog.dailydoseofds.com/p/5-agentic-ai-design-patterns
https://zhuanlan.zhihu.com/p/1972437682400519404