这次我们来看看 Go 语言雪花算法。
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/527
每次放长假的在家里的时候,总想找点简单的例子来看看实现原理,这次我们来看看 Go 语言雪花算法。
介绍
有时候在业务中,需要使用一些唯一的ID,来记录我们某个数据的标识。最常用的无非以下几种:UUID、数据库自增主键、Redis的Incr命令等方法来获取一个唯一的值。下面我们分别说一下它们的优劣,以便引出我们的分布式雪花算法。
UUID
首先是 UUID ,它是由128位二进制组成,一般转换成十六进制,然后用String表示。为了保证 UUID 的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成 UUID 的算法。
UUID 有五个版本:
- 版本1:基于时间戳和mac地址
- 版本2:基于时间戳,mac地址和
POSIX UID/GID - 版本3:基于MD5哈希算法
- 版本4:基于随机数
- 版本5:基于SHA-1哈希算法
UUID 的优缺点:
优点是代码简单,性能比较好。缺点是没有排序,无法保证按序递增;其次是太长了,存储数据库占用空间比较大,不利于检索和排序。
数据库自增主键
如果是使用 mysql 数据库,那么通过设置主键为 auto_increment 是最容易实现单调递增的唯一ID 的方法,并且它也方便排序和索引。
但是缺点也很明显,由于过度依赖数据库,那么受限于数据库的性能会导致并发性并不高;再来就是如果数据量太大那么会给分库分表会带来问题;并且如果数据库宕机了,那么这个功能是无法使用的。
Redis
Redis 目前已在很多项目中是一个不可或缺的存在,在 Redis 中有两个命令 Incr、IncrBy ,因为Redis是单线程的所以通过这两个指令可以能保证原子性从而达到生成唯一值的目标,并且性能也很好。
但是在 Redis 中,即使有 AOF 和 RDB ,但是依然会存在数据丢失,有可能会造成ID重复;再来就是需要依赖 Redis ,如果它不稳定,那么会影响 ID 生成。
Snowflake
通过上面的一个个分析,终于引出了我们的分布式雪花算法 Snowflake ,它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。开源的版本由scala编写,大家可以再找个地址找到这版本。
https://github.com/twitter-archive/snowflake/tags
它有以下几个特点:
- 能满足高并发分布式系统环境下ID不重复;
- 基于时间戳,可以保证基本有序递增;
- 不依赖于第三方的库或者中间件;
实现原理
Snowflake 结构是一个 64bit 的 int64 类型的数据。如下:
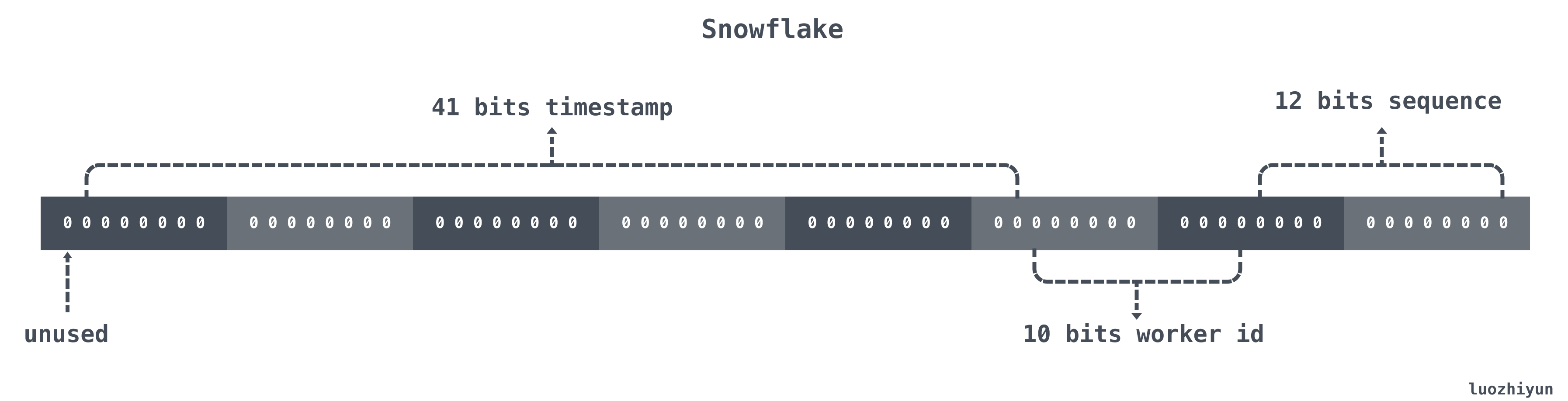
| 位置 | 大小 | 作用 |
|---|---|---|
| 0~11bit | 12bits | 序列号,用来对同一个毫秒之内产生不同的ID,可记录4095个 |
| 12~21bit | 10bits | 10bit用来记录机器ID,总共可以记录1024台机器 |
| 22~62bit | 41bits | 用来记录时间戳,这里可以记录69年 |
| 63bit | 1bit | 符号位,不做处理 |
上面只是一个将 64bit 划分的通用标准,一般的情况可以根据自己的业务情况进行调整。例如目前业务只有机器10台左右预计未来会增加到三位数,并且需要进行多机房部署,QPS 几年之内会发展到百万。
那么对于百万 QPS 平分到 10 台机器上就是每台机器承担十万的请求即可,12 bit 的序列号完全够用。对于未来会增加到三位数机器,并且需要多机房部署的需求我们仅需要将 10 bits 的 work id 进行拆分,分割 3 bits 来代表机房数共代表可以部署8个机房,其他 7bits 代表机器数代表每个机房可以部署128台机器。那么数据格式就会如下所示:

代码实现
实现步骤
其实看懂了上面的数据结构之后,需要自己实现一个雪花算法是非常简单,步骤大致如下:
- 获取当前的毫秒时间戳;
- 用当前的毫秒时间戳和上次保存的时间戳进行比较;
- 如果和上次保存的时间戳相等,那么对序列号 sequence 加一;
- 如果不相等,那么直接设置 sequence 为 0 即可;
- 然后通过或运算拼接雪花算法需要返回的 int64 返回值。
代码实现
首先我们需要定义一个 Snowflake 结构体:
type Snowflake struct {
sync.Mutex // 锁
timestamp int64 // 时间戳 ,毫秒
workerid int64 // 工作节点
datacenterid int64 // 数据中心机房id
sequence int64 // 序列号
}然后我们需要定义一些常量,方便我们在使用雪花算法的时候进行位运算取值:
const (
epoch = int64(1577808000000) // 设置起始时间(时间戳/毫秒):2020-01-01 00:00:00,有效期69年
timestampBits = uint(41) // 时间戳占用位数
datacenteridBits = uint(2) // 数据中心id所占位数
workeridBits = uint(7) // 机器id所占位数
sequenceBits = uint(12) // 序列所占的位数
timestampMax = int64(-1 ^ (-1 << timestampBits)) // 时间戳最大值
datacenteridMax = int64(-1 ^ (-1 << datacenteridBits)) // 支持的最大数据中心id数量
workeridMax = int64(-1 ^ (-1 << workeridBits)) // 支持的最大机器id数量
sequenceMask = int64(-1 ^ (-1 << sequenceBits)) // 支持的最大序列id数量
workeridShift = sequenceBits // 机器id左移位数
datacenteridShift = sequenceBits + workeridBits // 数据中心id左移位数
timestampShift = sequenceBits + workeridBits + datacenteridBits // 时间戳左移位数
)需要注意的是由于 -1 在二进制上表示是:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111
所以想要求得 41bits 的 timestamp 最大值可以将 -1 向左位移 41 位,得到:
11111111 11111111 11111110 00000000 00000000 00000000 00000000 00000000
那么再和 -1 进行 ^异或运算:
00000000 00000000 00000001 11111111 11111111 11111111 11111111 11111111
这就可以表示 41bits 的 timestamp 最大值。datacenteridMax、workeridMax也同理。
接着我们就可以设置一个 NextVal 函数来获取 Snowflake 返回的 ID 了:
func (s *Snowflake) NextVal() int64 {
s.Lock()
now := time.Now().UnixNano() / 1000000 // 转毫秒
if s.timestamp == now {
// 当同一时间戳(精度:毫秒)下多次生成id会增加序列号
s.sequence = (s.sequence + 1) & sequenceMask
if s.sequence == 0 {
// 如果当前序列超出12bit长度,则需要等待下一毫秒
// 下一毫秒将使用sequence:0
for now <= s.timestamp {
now = time.Now().UnixNano() / 1000000
}
}
} else {
// 不同时间戳(精度:毫秒)下直接使用序列号:0
s.sequence = 0
}
t := now - epoch
if t > timestampMax {
s.Unlock()
glog.Errorf("epoch must be between 0 and %d", timestampMax-1)
return 0
}
s.timestamp = now
r := int64((t)<<timestampShift | (s.datacenterid << datacenteridShift) | (s.workerid << workeridShift) | (s.sequence))
s.Unlock()
return r
}上面的代码也是非常的简单,看看注释应该也能懂,我这里说说最后返回的 r 系列的位运算表示什么意思。
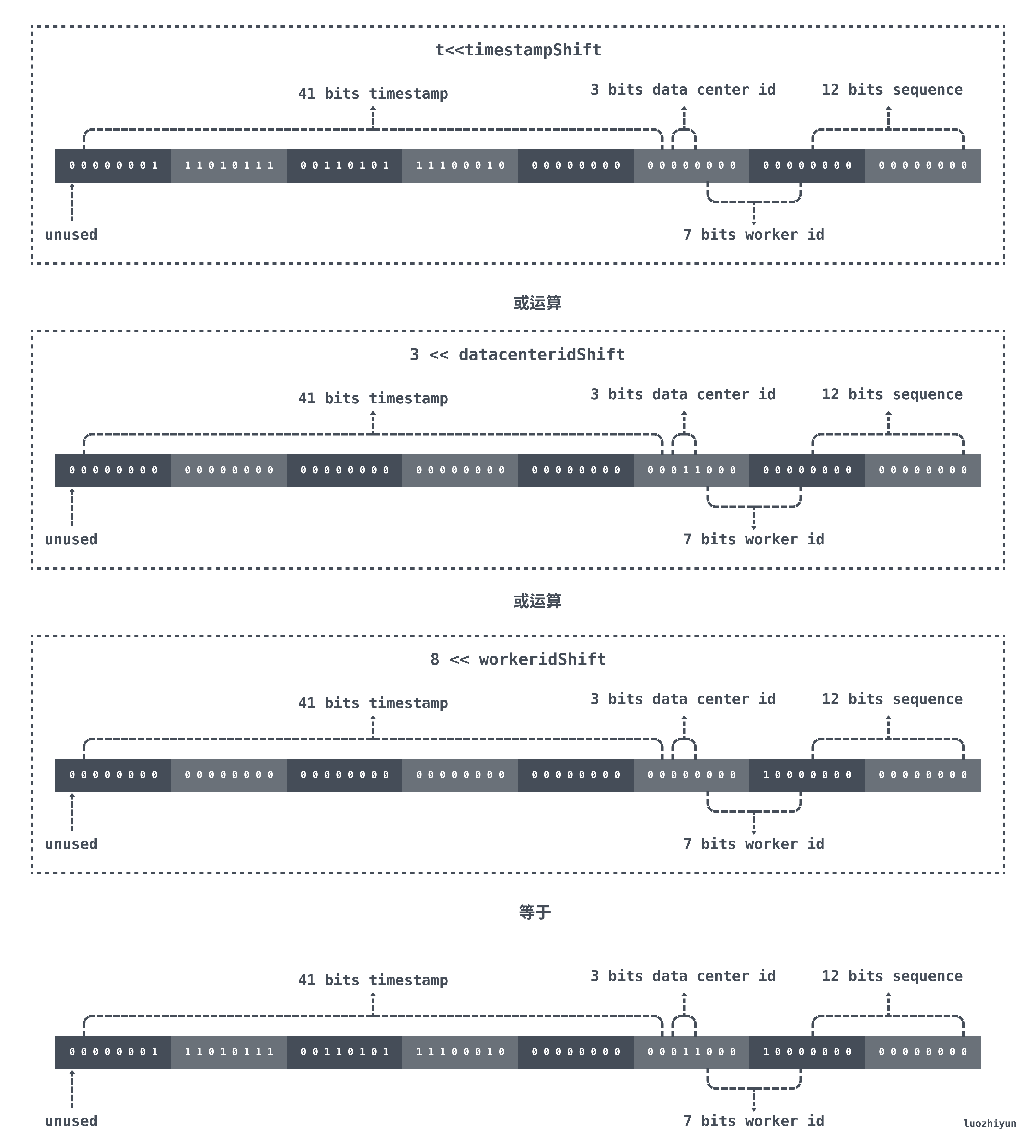
首先 t 表示的是现在距离 epoch 的时间差,我们 epoch 在初始化的时候设置的是 2020-01-01 00:00:00,那么对于 41bit 的 timestamp 来说会在 69 年之后才溢出。对 t 进行向左位移之后,低于 timestampShift 位置上全是0 ,由 datacenterid、workerid、sequence 进行取或填充。
在当前的例子中,如果当前时间是 2021/01/01 00:00:00,那么位运算结果如下图所示:
(觉得图片太小了,可以到这里看:https://img.luozhiyun.com/20210502181513.png)