本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本
这篇文章首先会回顾一下整个 SQL 的执行过程,用来说明为什么要范围计算,最后从源码的角度讲解一下 析取范式 DNF (disjunctive normal form) 和 合取范式 CNF (conjunctive normal form) 是如何转化为范围区间。
优化过程解析
TiDB 在进行表扫描前会对查询条件,也就是 Selection 算子的过滤条件化简, 转为区间扫描。可以尽早的将无关的数据过滤掉,提升整个 SQL 的执行效率。
例如:
CREATE TABLE test1 (a int primary key, b int, c int,index (b));
explain select * from test1 where b=5 or ( b>5 and (b>6 or b <8) and b<12) ;在上面的查询中,会对查询条件进行优化,将索引搜索的返回缩小。对于上面的 where 条件中的表达式区间,最终会优化为:
b=5 or ( b>5 and (b>6 or b <8) and b<12)=> [5,12)
我们从 explain 中也可以看到优化结果:
+-------------------------+-------+---------+-----------------------+--------------------------------------------+
|id |estRows|task |access object |operator info |
+-------------------------+-------+---------+-----------------------+--------------------------------------------+
|IndexLookUp_10 |250.00 |root | | |
|├─IndexRangeScan_8(Build)|250.00 |cop[tikv]|table:test1, index:b(b)|range:[5,12), keep order:false, stats:pseudo|
|└─TableRowIDScan_9(Probe)|250.00 |cop[tikv]|table:test1 |keep order:false, stats:pseudo |
+-------------------------+-------+---------+-----------------------+--------------------------------------------+在正式进入探究之前,我们先来看看 TiDB 的几个优化步骤,让不了的同学也能很好的掌握整个 SQL 优化过程。
对于上面我们的 SQL:
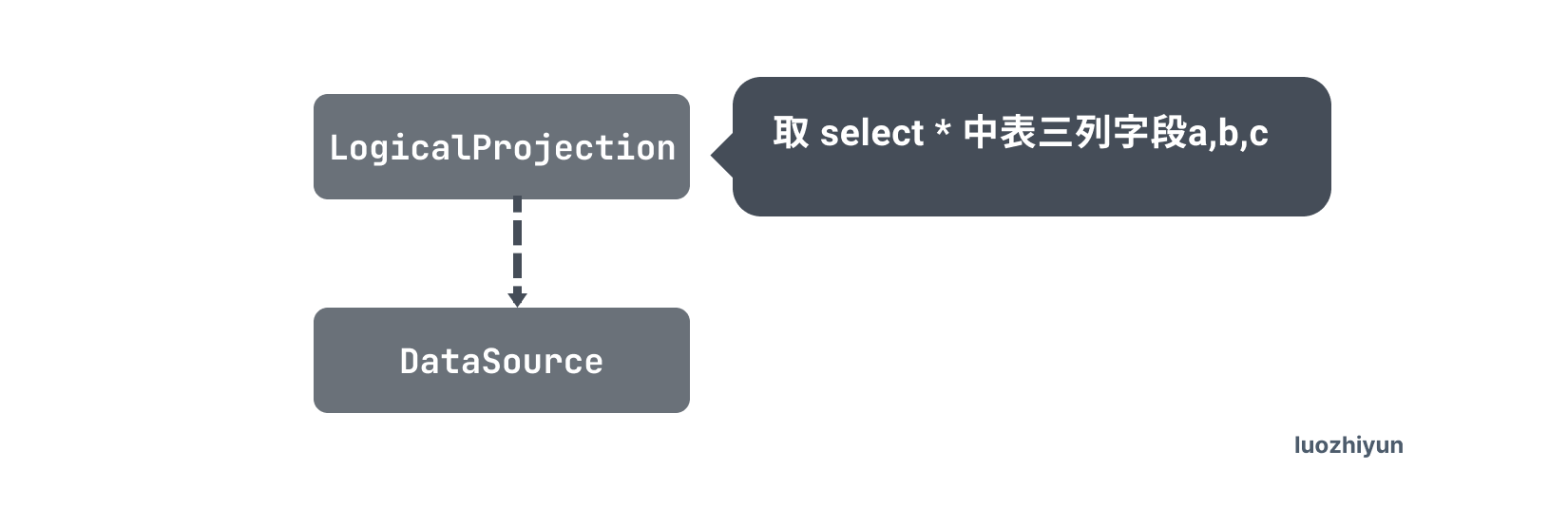
select * from test1 where b=5 or ( b>5 and (b>6 or b <8) and b<12) ;首先会生成执行计划:
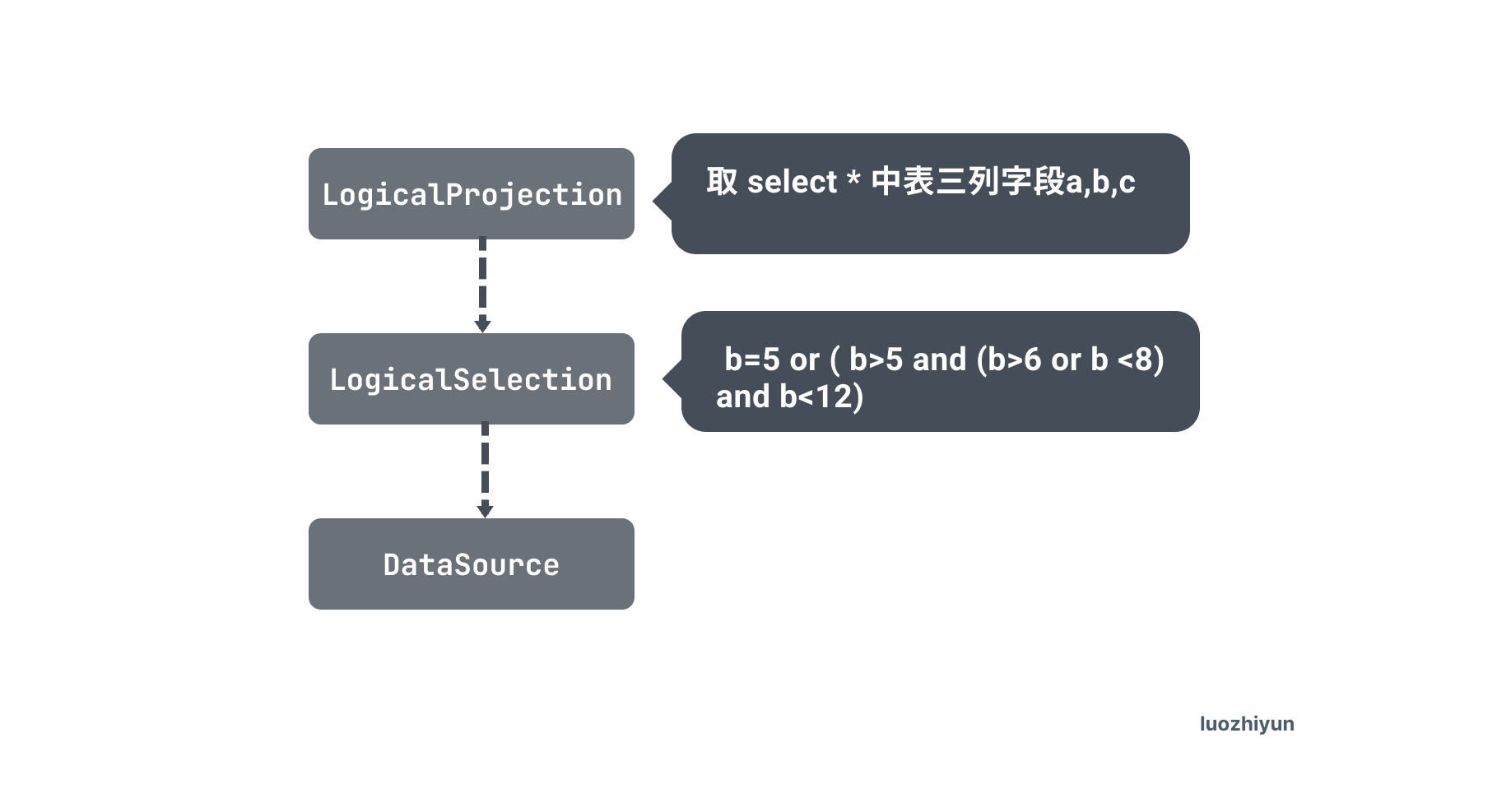
在执行完 logicalOptimize 逻辑优化之后,执行计划变为下面这样:
Selection算子被下推到了 DataSource 算子中,在 DataSource 的 pushedDownConds 中保存着下推的过滤算子:

对于我们的 pushedDownConds 展开来是一个二叉树结构:

因为索引底层是顺序排列的,所以要将这颗树转为扫描区间。
然后在执行 physicalOptimize 然后进行物理优化的时候会遍历 DataSource 算子的 possibleAccessPaths
...
for _, path := range ds.possibleAccessPaths {
if path.IsTablePath() {
continue
}
err := ds.fillIndexPath(path, ds.pushedDownConds)
if err != nil {
return nil, err
}
}
...fillIndexPath 会调用 DetachCondAndBuildRangeForIndex 来生成扫描区间,这个函数会递归的调用如下 2 个函数:
detachDNFCondAndBuildRangeForIndex:展开 OR 条件连接也叫析取范式 DNF (disjunctive normal form),生成扫描区间或合并扫描区间;
detachCNFCondAndBuildRangeForIndex:展开 AND 条件连接也叫合取范式 CNF (conjunctive normal form),生成扫描区间或合并扫描区间;
整个执行过程如下:
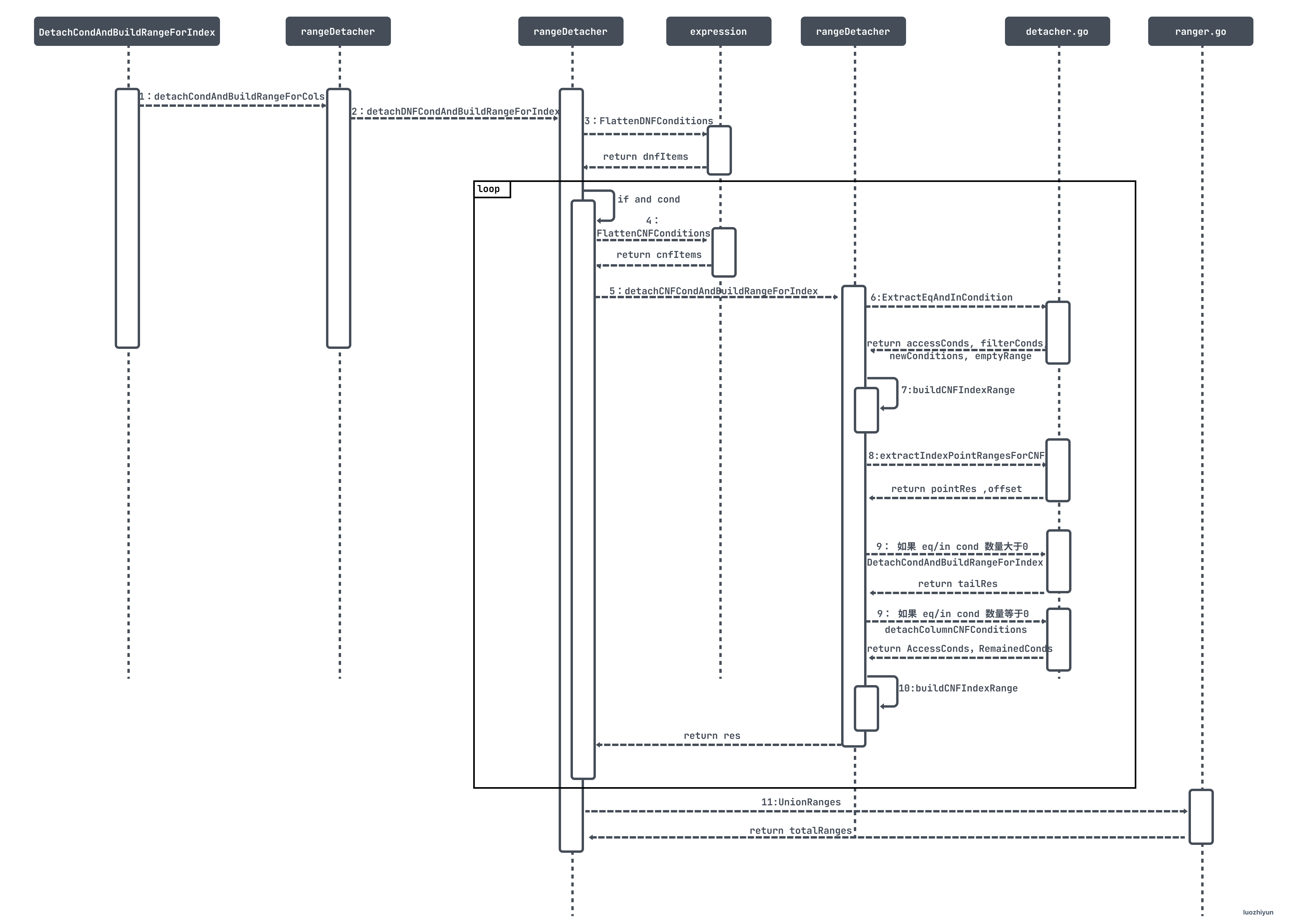
上面的表达式树最终生成了这样的区间: [5,12)。
然后 physicalOptimize 会递归所有的算子调用 findBestTask 函数,最后调用到 DataSoure 算子使用 Skyline-Pruning 索引裁剪,它会从 possibleAccessPaths 获取最优的执行计划:
func (ds *DataSource) skylinePruning(prop *property.PhysicalProperty) []*candidatePath {
candidates := make([]*candidatePath, 0, 4)
for _, path := range ds.possibleAccessPaths {
var currentCandidate *candidatePath
...
pruned := false
for i := len(candidates) - 1; i >= 0; i-- {
// 比较索引代价,判断是否进行裁剪
result := compareCandidates(candidates[i], currentCandidate)
if result == 1 {
pruned = true
break
} else if result == -1 {
candidates = append(candidates[:i], candidates[i+1:]...)
}
}
if !pruned {
candidates = append(candidates, currentCandidate)
}
}
...
return candidates
}compareCandidates 函数会从下面三个方面进行判断一个索引的优劣:
-
索引的列涵盖了多少访问条件。“访问条件”指的是可以转化为某列范围的
where条件,如果某个索引的列集合涵盖的访问条件越多,那么它在这个维度上更优。 -
选择该索引读表时,是否需要回表(即该索引生成的计划是 IndexReader 还是 IndexLookupReader)。不用回表的索引在这个维度上优于需要回表的索引。如果均需要回表,则比较索引的列涵盖了多少过滤条件。过滤条件指的是可以根据索引判断的
where条件。如果某个索引的列集合涵盖的访问条件越多,则回表数量越少,那么它在这个维度上越优。 -
选择该索引是否能满足一定的顺序。因为索引的读取可以保证某些列集合的顺序,所以满足查询要求顺序的索引在这个维度上优于不满足的索引。
例如:如果索引 idx_a 在这三个维度上都不比 idx_b 差,且有一个维度比 idx_b 好,那么 TiDB 会优先选择 idx_a。
排除了不合适的索引之后,会根据下面的规则来选择一个代价最低的索引进行读表:
- 索引的每行数据在存储层的平均长度。
- 索引生成的查询范围的行数量。
- 索引的回表代价。
- 索引查询时的范围数量。
最后生成的执行计划为:PhysicalIndexLookUpReader。
范围计算源码分析
在上面中我也说到了 DetachCondAndBuildRangeForIndex 会根据 where 条件来生成扫描区间。

detachDNFCondAndBuildRangeForIndex 析取范式
func (d *rangeDetacher) detachDNFCondAndBuildRangeForIndex(condition *expression.ScalarFunction, newTpSlice []*types.FieldType) ([]*Range, []expression.Expression, bool, error) {
sc := d.sctx.GetSessionVars().StmtCtx
firstColumnChecker := &conditionChecker{
colUniqueID: d.cols[0].UniqueID,
shouldReserve: d.lengths[0] != types.UnspecifiedLength,
length: d.lengths[0],
}
rb := builder{sc: sc}
// 递归拉平 or 子项 Expression
dnfItems := expression.FlattenDNFConditions(condition)
newAccessItems := make([]expression.Expression, 0, len(dnfItems))
var totalRanges []*Range
hasResidual := false
for _, item := range dnfItems {
// 如果该子项 Expression 包含了 AND
if sf, ok := item.(*expression.ScalarFunction); ok && sf.FuncName.L == ast.LogicAnd {
// 递归拉平 and 子项 Expression
cnfItems := expression.FlattenCNFConditions(sf)
var accesses, filters []expression.Expression
res, err := d.detachCNFCondAndBuildRangeForIndex(cnfItems, newTpSlice, true)
if err != nil {
return nil, nil, false, nil
}
ranges := res.Ranges
accesses = res.AccessConds
filters = res.RemainedConds
if len(accesses) == 0 {
return FullRange(), nil, true, nil
}
if len(filters) > 0 {
hasResidual = true
}
totalRanges = append(totalRanges, ranges...)
newAccessItems = append(newAccessItems, expression.ComposeCNFCondition(d.sctx, accesses...))
} else if firstColumnChecker.check(item) {
if firstColumnChecker.shouldReserve {
hasResidual = true
firstColumnChecker.shouldReserve = d.lengths[0] != types.UnspecifiedLength
}
// 计算逻辑区间
points := rb.build(item)
// 将区间转化为外暴露的 range 结构
ranges, err := points2Ranges(sc, points, newTpSlice[0])
if err != nil {
return nil, nil, false, errors.Trace(err)
}
totalRanges = append(totalRanges, ranges...)
newAccessItems = append(newAccessItems, item)
} else {
//生成 [null, +∞) 区间
return FullRange(), nil, true, nil
}
}
// 区间并
// 例如区间:[a, b], [c, d],表示的是a <= c. If b >= c
// 那么这两个区间可以合并为:[a, max(b, d)].
totalRanges, err := UnionRanges(sc, totalRanges, d.mergeConsecutive)
if err != nil {
return nil, nil, false, errors.Trace(err)
}
return totalRanges, []expression.Expression{expression.ComposeDNFCondition(d.sctx, newAccessItems...)}, hasResidual, nil
}detachDNFCondAndBuildRangeForIndex 方法中会拉平 or 子项,然后进行遍历,因为子项中可能嵌套子项,例如:where b=5 or ( b>5 and (b>6 or b <8) and b<12) 经过 FlattenDNFConditions 拉平之后会变成两个子项:EQ 和 AND
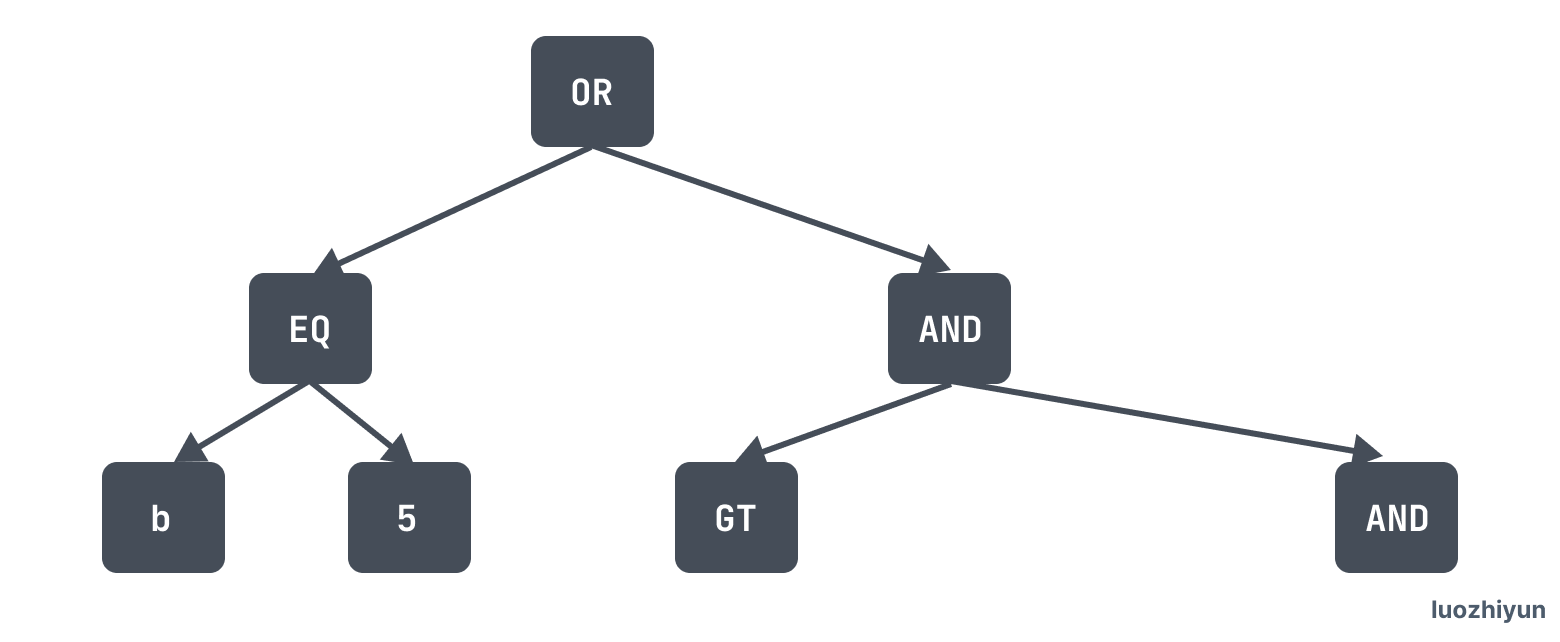
那么,对于 AND 子项来说会继续调用 FlattenCNFConditions 拉平,之后进入到 detachCNFCondAndBuildRangeForIndex 进行范围区间的提取,这个我们后面再说。先看看 EQ 这个子项的处理。
EQ 子项会进入到 build 方法中,根据类型判断构建 point :
func (r *builder) buildFromScalarFunc(expr *expression.ScalarFunction) []*point {
switch op := expr.FuncName.L; op {
case ast.GE, ast.GT, ast.LT, ast.LE, ast.EQ, ast.NE, ast.NullEQ:
return r.buildFormBinOp(expr)
...
case ast.In:
retPoints, _ := r.buildFromIn(expr)
return retPoints
case ast.Like:
return r.newBuildFromPatternLike(expr)
case ast.IsNull:
startPoint := &point{start: true}
endPoint := &point{}
return []*point{startPoint, endPoint}
case ast.UnaryNot:
return r.buildFromNot(expr.GetArgs()[0].(*expression.ScalarFunction))
}
return nil
}buildFromScalarFunc 中包含了很多 buildFromXXX 方法,它们是计算一个具体函数的 range 的方法。比如 buildFromIn 便是处理 in 函数的方法。
每个 point 代表区间的一个端点:
type point struct {
value types.Datum
excl bool // exclude
start bool
}value 表示端点的值, excl 表示端点为开区间的端点还是闭区间的端点,start 表示这个端点是左端点还是右端点。
我们这里的 EQ 子项会进入到 buildFormBinOp 方法中。
func (r *builder) buildFormBinOp(expr *expression.ScalarFunction) []*point {
...
var col *expression.Column
var ok bool
// 因为有的人喜欢这样写表达式:where 5=b,所以这里需要获取表达式中的列名和值
// 判断第一个参数是否是列字段
if col, ok = expr.GetArgs()[0].(*expression.Column); ok {
ft = col.RetType
// 获取值
value, err = expr.GetArgs()[1].Eval(chunk.Row{})
if err != nil {
return nil
}
op = expr.FuncName.L
} else {
// 参数的第二个是列
col, ok = expr.GetArgs()[1].(*expression.Column)
if !ok {
return nil
}
ft = col.RetType
value, err = expr.GetArgs()[0].Eval(chunk.Row{})
if err != nil {
return nil
}
// 因为表达式是这样写的:where 5=b 所以需要将表达式中的符号做一下反转
switch expr.FuncName.L {
case ast.GE:
op = ast.LE
case ast.GT:
op = ast.LT
case ast.LT:
op = ast.GT
case ast.LE:
op = ast.GE
default:
op = expr.FuncName.L
}
}
if op != ast.NullEQ && value.IsNull() {
return nil
}
...
//处理unsigned列
value, op, isValidRange := handleUnsignedCol(ft, value, op)
if !isValidRange {
return nil
}
// 处理越界情况
value, op, isValidRange = handleBoundCol(ft, value, op)
if !isValidRange {
return nil
}
// 构建区间端点
switch op {
case ast.NullEQ:
if value.IsNull() {
return []*point{{start: true}, {}} // [null, null]
}
fallthrough
case ast.EQ:
startPoint := &point{value: value, start: true}
endPoint := &point{value: value}
return []*point{startPoint, endPoint}
case ast.NE:
startPoint1 := &point{value: types.MinNotNullDatum(), start: true}
endPoint1 := &point{value: value, excl: true}
startPoint2 := &point{value: value, start: true, excl: true}
endPoint2 := &point{value: types.MaxValueDatum()}
return []*point{startPoint1, endPoint1, startPoint2, endPoint2}
...
}
return nil
}buildFormBinOp 主要是对一些异常情况进行处理,如:unsigned列、越界、特殊列的值,然后构建区间端点 Point 数组。
然后就是调用 points2Ranges 将 Point 数组转为 range:
func points2Ranges(sc *stmtctx.StatementContext, rangePoints []*point, tp *types.FieldType) ([]*Range, error) {
ranges := make([]*Range, 0, len(rangePoints)/2)
for i := 0; i < len(rangePoints); i += 2 {
startPoint := rangePoints[i]
...
endPoint := rangePoints[i+1]
...
ran := &Range{
LowVal: []types.Datum{startPoint.value},
LowExclude: startPoint.excl,
HighVal: []types.Datum{endPoint.value},
HighExclude: endPoint.excl,
}
ranges = append(ranges, ran)
}
return ranges, nil
}上面的代码形态我做了一些处理方面理解这段代码的意思,主要就是获取端点的开闭区间构建 Range。
detachCNFCondAndBuildRangeForIndex 合取范式
func (d *rangeDetacher) detachCNFCondAndBuildRangeForIndex(conditions []expression.Expression, tpSlice []*types.FieldType, considerDNF bool) (*DetachRangeResult, error) {
var (
eqCount int
ranges []*Range
err error
)
...
res := &DetachRangeResult{}
// accessConds 用于抽出 eq/in 可以用于点查的条件构建范围查询
// newConditions 用来简化同字段出现多次的 eq 或 in 条件的情况,如:a in (1, 2, 3) and a in (2, 3, 4) 被简化为 a in (2, 3)
accessConds, filterConds, newConditions, emptyRange := ExtractEqAndInCondition(d.sctx, conditions, d.cols, d.lengths)
eqOrInCount := len(accessConds)
// 根据access构建范围区间
ranges, err = d.buildCNFIndexRange(tpSlice, eqOrInCount, accessConds)
if err != nil {
return res, err
}
res.Ranges = ranges
res.AccessConds = accessConds
checker := &conditionChecker{
colUniqueID: d.cols[eqOrInCount].UniqueID,
length: d.lengths[eqOrInCount],
shouldReserve: d.lengths[eqOrInCount] != types.UnspecifiedLength,
}
if considerDNF {
...
if eqOrInCount > 0 {
newCols := d.cols[eqOrInCount:]
newLengths := d.lengths[eqOrInCount:]
tailRes, err := DetachCondAndBuildRangeForIndex(d.sctx, newConditions, newCols, newLengths)
if len(tailRes.AccessConds) > 0 {
res.Ranges = appendRanges2PointRanges(res.Ranges, tailRes.Ranges)
res.AccessConds = append(res.AccessConds, tailRes.AccessConds...)
}
res.RemainedConds = append(res.RemainedConds, tailRes.RemainedConds...)
...
return res, nil
}
// 到这里,说明eqOrInCount = 0
// 遍历所有 conditions ,如果该condition是LogicOr Scalar Function类型的,则调用 DNF 相关函数进行处理
res.AccessConds, res.RemainedConds = detachColumnCNFConditions(d.sctx, newConditions, checker)
// 获取 AccessConds 的范围 range
ranges, err = d.buildCNFIndexRange(tpSlice, 0, res.AccessConds)
if err != nil {
return nil, err
}
res.Ranges = ranges
return res, nil
}
...
return res, nil
}AND 表达式中,只有当之前的列均为点查的情况下,才会考虑下一个列。
例如:对于索引 (a, b, c),有条件 a > 1 and b = 1,那么会被选中的只有 a > 1。对于条件 a in (1, 2, 3) and b > 1,两个条件均会被选到用来计算 range。
所以在这个方法中,首先会调用 ExtractEqAndInCondition 函数抽离出 eq/in 可以用于点查的条件构建范围查询赋值到 accessConds 中,剩余的条件被抽离到 newConditions 中。
然后对于联合索引中,如果第一个字段是 eq/in 点查询,那么 eqOrInCount 不为0,就可以继续向后获取其他字段的范围。所以接下来会调用 DetachCondAndBuildRangeForIndex 获取其他字段的范围。
对于 eqOrInCount 等于0的条件,说明字段中不存在 eq/in 点查询,或者联合索引中左边的字段查询不为点查询,那么会调用 detachColumnCNFConditions 对单列索引进行处理。
Reference
https://pingcap.com/zh/blog/tidb-source-code-reading-13
https://github.com/xieyu/blog/blob/master/src/tidb/range.md
https://www.youtube.com/watch?v=OFqkfJTVIc8
https://www.cnblogs.com/lijingshanxi/p/12077587.html
https://zh.wikipedia.org/wiki/%E9%80%BB%E8%BE%91%E8%BF%90%E7%AE%97%E7%AC%A6
https://docs.pingcap.com/zh/tidb/stable/choose-index
