ETH发展史
2013年底: Vitalik Buterin(V神)发布了以太坊白皮书。他的核心理念是:比特币像一个功能单一的计算器(可编程货币),而世界需要一个更通用的平台,像一台“世界计算机”(World Computer)。所以他提出了智能合约的概念,指的是运行在区块链上的、图灵完备的程序。通过使用以太坊虚拟机(EVM)提供的这样的沙盒环境,用于执行智能合约。
2015年7月"Frontier"(前线)版本上线。这是以太坊的第一个“创世区块”,标志着网络的正式启动,这是时候还仅仅是一个测试版本。采用的是工作量证明(PoW)的共识机制。
2016年初"Homestead"(家园)版本发布,这是第一个稳定版本,标志着以太坊不再是“测试版”,开始吸引DApp(去中心化应用)构建者。The DAO这个项目诞生了,它是一个去中心化的风险投资基金,通过智能合约管理,它筹集了当时价值约1.5亿美元的ETH。
同时也意味着危机,2016年6月,The DAO 合约遭到“重入攻击”(Re-entrancy Attack),导致约1/3的资金被盗。
所以这个时候社区面临一个哲学困境,是要接受损失,还是进行通过修改协议规则来回滚交易,追回被盗资金。最后社区投票支持硬分叉,追回了资金,成为了今天的主流链,也就是今天的 ETH。另一派坚持不回滚,保留了原始链,就成了另一个币 ETC。
我们接着跳过几年不这么重要的发展期来到PoS时代。
为什么要从 PoW 转向 PoS 共识证明呢?我们都知道 PoW 用“工作”来换取记账权,工作量越大,越值得信赖,这就有个问题,需要巨大的电力和硬件成本,这是极度不环保的。
而 PoS 的核心理念是用“抵押”来换取记账权,你抵押的(Stake)越多,越值得信赖。参与者不再需要购买昂贵的矿机,而是需要购买并质押(锁定)网络的原生代币,将这些代币作为“保证金”或“押金”锁在网络中。如果一个验证者试图作恶(例如,提议无效区块、双重签名),网络会自动销毁他质押的“保证金,ETH 就是这样降低了约 99.95% 的能耗。
下面说一下ETH是怎么做到的:
2020年12月, 信标链(Beacon Chain)上线,这是一条独立运行的、采用 PoS 共识的全新区块链,它唯一的任务就是让验证者质押 ETH 并就 PoS 共识达成一致。此时,ETH 质押是单向的(只能存入,不能取出)。
2022年9月15日以太坊团队将原有的 PoW 链(现在称为“执行层”)的“引擎”——即 PoW 共识——拔掉。然后,将“执行层”接入到“信标链”(现在称为“共识层”)的 PoS 引擎上。这正式标志着以太坊进入了“PoS 时代”
合并完成后,2023年4月 "Shapella"(上海 + Capella)发布启用了质押提款(EIP-4895)。验证者终于可以取出他们质押的 ETH 和奖励,这次升级引入了 withdrawalsRoot(提款树根)字段到区块头中。
当然 ETH 的迭代远没有结束,我看社区还在继续讨论新的提案出来。比如 Pectra 、The Verge 与 The Purge 等,感兴趣的可以自行取查阅一下。
账户
这里用 BTC 和 ETH 进行对比,首先在 BTC 中,并不存在一个叫做“我的余额”的变量。它是由 UTXO 算出来的,所以假设钱包里有 5 BTC。这 5 BTC 在区块链上可能并不是一个“5”,而是:
- 一笔 2 BTC 的“现金”(UTXO 1)
- 一笔 1.5 BTC 的“现金”(UTXO 2)
- 一笔 1.5 BTC 的“现金”(UTXO 3)
总余额 = UTXO 1 + UTXO 2 + UTXO 3 = 5 BTC。
如果想支付 3 BTC,钱包会选择“消耗”掉 UTXO 1 (2 BTC) 和 UTXO 2 (1.5 BTC),总共 3.5 BTC。然后产生两个新的 UTXO:
- 一个 3 BTC 的 UTXO 发送给您的朋友(支付)。
- 一个 0.5 BTC 的 UTXO 发送回给您自己(找零)。
旧的 UTXO 1 和 UTXO 2 就被标记为“已花费”,不能再用了。
这种模型的优点: 简单、安全、隐私性相对较好(因为找零地址可以是新地址)、易于并行处理交易。 缺点: 难以实现复杂的逻辑(例如智能合约),因为它很难跟踪一个“账户”的复杂状态。
ETH 的设计更像是传统的银行系统。每个地址都是一个独立的“账户”。如果地址有 5 ETH,那么在以太坊的“全局账本”上,地址旁边就明确写着 balance: 5。
如果要支付 3 ETH,发起一笔交易,声明:“从账户A转 3 ETH 到账户B”,网络验证账户余额(5 ETH)是否足够支付 3 ETH(以及手续费 Gas)。验证通过后,以太坊网络会:
- 将账户A的
balance减去 3 ETH。 - 将账户B的
balance加上 3 ETH。
为了防止余额数字被直接篡改,账户里面有 nonce 用来记数,每次交易完毕之后加一,防止重放攻击。
ETH 有两种账户:
外部账户 externally owned account,个人用户钱包,由私钥控制,可以发起交易;
合约账户 smart contract account 由代码(智能合约)控制,没有私钥,它不能主动发起交易,只能在被 EOA 或其他合约“调用”(发送消息)时被动执行其代码。
ETH模型的优点:使得智能合约(复杂的应用程序)成为可能。模型更直观,易于开发 DApps。缺点: 交易必须按顺序处理(因为有 nonce 机制防止重放攻击),这可能导致网络拥堵。
数据结构
Merkel Patricia Trie
账户地址到账户状态的映射 , 账户地址是 160 位。
以太坊 (ETH) 的核心数据结构是 Modified Merkle Patricia Trie, 简称 MPT。我们可以把它拆解成两个关键概念的组合来理解:Merkle Tree (默克尔树) 和 Patricia Trie (帕特里夏·树,或称压缩前缀树)
Merkle Tree (默克尔树):它是一种哈希树。树底部的每个“叶子”是数据块的哈希值。相邻的哈希值两两组合再哈希,层层向上,最终汇聚成一个“根哈希” (Root Hash),如下图:
这种树有一个特点是只要树中的任何一个数据发生(哪怕是 1 bit 的)改变,最终的“根哈希”都会变得完全不同。这使得节点只需比较这一个根哈希,就能快速验证彼此是否拥有完全相同的海量数据。
+-----------------+
| Merkle Root | <- 最终的"指纹" (H_ABCD)
| (H_AB + H_CD) |
+-----------------+
/ \
/ \
+---------------+ +---------------+
| Hash_AB | | Hash_CD | <- 中间节点
| (H(T1)+H(T2)) | | (H(T3)+H(T4)) |
+---------------+ +---------------+
/ \ / \
/ \ / \
+-------+ +-------+ +-------+ +-------+
| H(T1) | | H(T2) | | H(T3) | | H(T4) | <- 叶子节点
+-------+ +-------+ +-------+ +-------+
| | | |
+-------+ +-------+ +-------+ +-------+
| T1 | | T2 | | T3 | | T4 | <- 原始数据
+-------+ +-------+ +-------+ +-------+比如我们上图有四个数据块 T1, T2, T3, T4,然后计算哈希H(T1), H(T2), H(T3), H(T4)构成叶子节点,然后他们的父节点分别由他们拼接起来再哈希获得。如果有人把 T3 改成了 T3*,那么 H(T3) 会变,Hash_CD 也会变,最终 Merkle Root 会变得完全不同。
Patricia Trie (称压缩前缀树)
它其实是 Trie 进化而来的,可以高效地存储和查找键值对 (Key-Value),特别是当“键”(Key) 有相同前缀时,它能极大压缩存储空间。举个例子,比如我们要存储以下几个键值对(以单词为例):
"romane": (值 1)"romanus": (值 2)"romulus": (值 3)"rubens": (值 4)"ruber": (值 5)
(Root)
|
"r"
/ \
/ \
"om" "ub"
/ \ / \
/ \ / \
"an" "ulus" "e" "ens" (值 4)
/ \ | |
/ \ (值 3) "r"
"e" "us" |
| | (值 5)
(值 1) (值 2)我们可以看到这个树基本上和 Trie 类似,唯一的区别就是对路径进行了压缩,对比普通前缀树会是 R -> O -> M -> A -> N -> E。看,R->O 和 O->M 都是“单行道”,只有一个子节点。Patricia 的压缩它会把这些单行道合并。R 后面有两个分叉 ("o", "u"),所以 "r" 节点保留。但 "r" 之后的 "o" 和 "m" 都是单行道,所以它们被压缩成了 "om" 节点。同理,"rub" 被压缩成了 "ub" 节点。
使用 Patricia Trie结构对 ETH 来说主要有几点好处:
-
ETH 需要跟踪数以亿计的账户,每个账户都有自己的状态(余额、nonce、合约代码等)。Patricia Trie 可以方便的用来将这些数据组织成 key value 对,比如 key 存的是账户地址 (
0x...),value存的是该账户的状态信息。 -
并且以太坊的“键”(如账户地址)非常长(160位或更长)。如果使用标准的前缀树,从根节点到每个叶子节点都会有非常多的层级,而Patricia Trie它会把所有“没有分叉的单行道”路径压缩合并成一个节点,从而节省空间。
-
Trie 树的最终形状和根哈希只取决于它所包含的“键值对”数据,而与插入这些数据的顺序无关。以太坊是一个全球分布式的系统。不同的节点在构建区块时,可能会以不同的顺序处理(本地缓存或插入)状态数据,所以这一点也是至关重要的。
-
最后就是 Patricia Trie 允许高效的状态更新,当一笔交易发生时(例如,A 转账给 B),通常只有极少数的“值”被改变了(A的余额减少,B的余额增加),种树形结构允许只更新从被修改的叶子节点到根节点的那条路径上的节点。
在 ETH 结构中,有三棵树都是使用的Patricia Trie结构:交易树 (Transaction Trie)、收据树 (Receipts Trie) 、状态树(State Trie),所以我们来看看 ETH 的 Merkel Patricia Trie 是怎么做的。
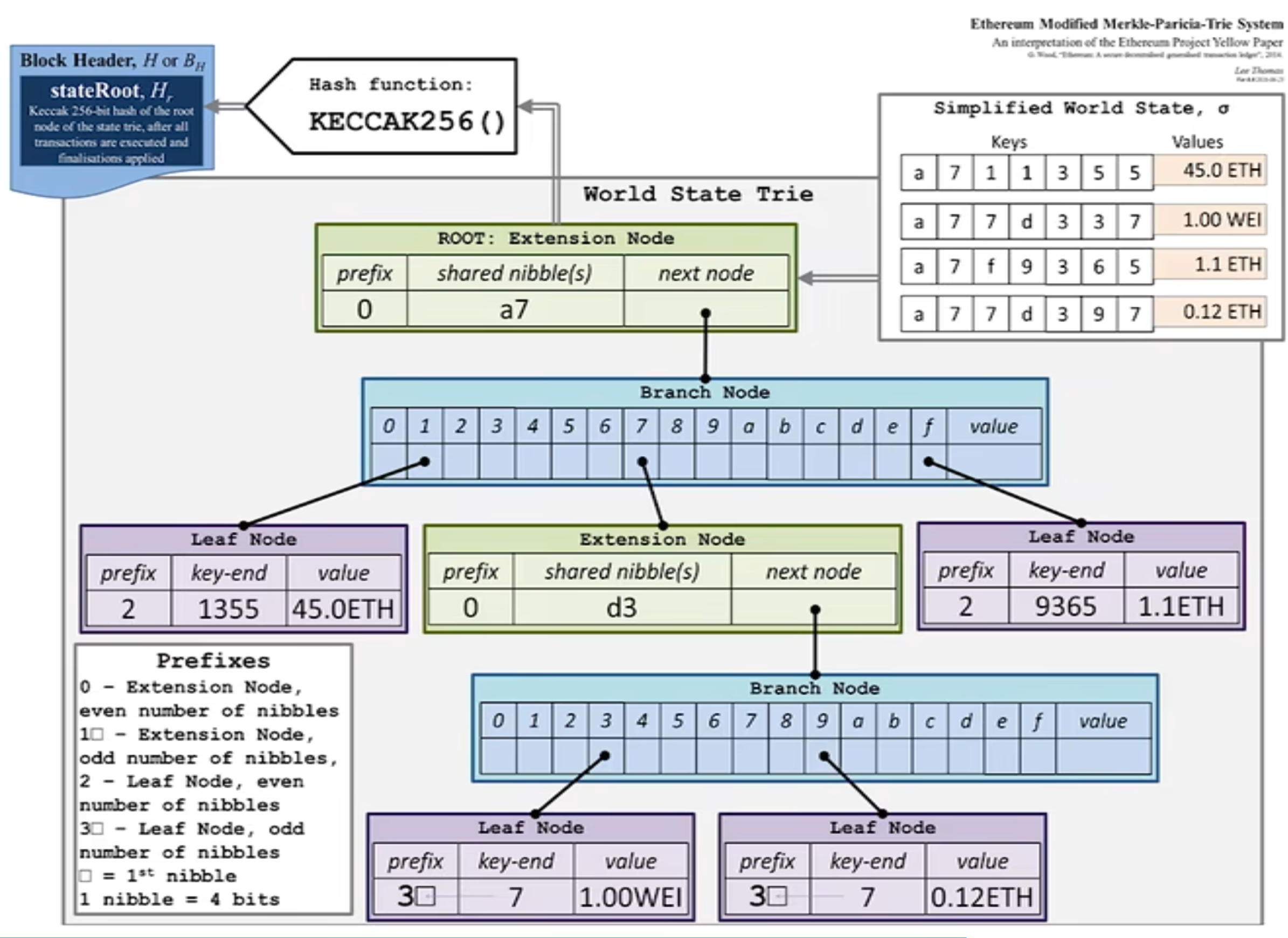
ETH 它把键视为 16 进制的 nibble(半字节)序列,用三种节点(Branch / Extension / Leaf)压缩表示键空间,并对每个节点做序列化后取哈希,最后得到整棵树的根哈希,如上图所示。
nibble (半字节)序列简单说就是将输入的 字节流 (byte stream) 转换为 16 进制字符流。因为一个字节 (Byte) 包含 8-bit,而一个半字节 (Nibble) 包含 4-bit,所以每一个字节都会被精确地拆分成两个半字节 (nibbles)。一个 8-bit 的字节,比如 0x7A,就会被拆分成了两个 nibbles:[7, a]。
下面我们看看三种节点(Branch / Extension / Leaf):
-
Branch 节点(branch) — 有 16 个子指针 + 一个可选值槽(用于恰好在此处结束的键):
BranchNode: +----------------------------+ | v0 | v1 | v2 | ... | v15 | value | +----------------------------+- v0..v15 共 16 个子指针是因为 Key 被拆分成了半字节 (nibbles) ,用十六进制表示,指向下一层节点(分别对应 nibble 0..15),如果没有对应路径则为 null(或空);
value字段用于当某个键恰好在该节点结束(即键完全耗尽)时保存对应值。
-
Extension 节点(extension) — 用于把一段共享前缀聚合成一条边:
ExtensionNode: +----------------------+ 指向下一级节点 | path: [nibble数组] | ---> 子节点 +----------------------+ (Branch/Leaf/Extension)path是一段 nibble(十六进制半字节)序列;extension 不包含值,只是压缩中间相同前缀。
-
Leaf 节点(leaf) — 存储键的剩余部分(从分支到末尾)和对应值:
LeafNode: +---------------------------+ | path: [剩余 nibble数组] | | value: bytes | +---------------------------+- 当一个键在 trie 中一个分支走到底时,用 leaf 存储剩下的 nibble 和最终值。
比如我们把把三个键插入到空的MPT中:
- Key A:
[a, b, c, d]-> 值V1 - Key B:
[a, b, c, e]-> 值V2 - Key C:
[a, b, f]-> 值V3
root = Extension([a,b]) -> Branch
/ | ...
c f
| \
Extension([c]) Leaf([ ] -> V3)
|
Branch
/ \
d e
| |
Leaf Leaf
(V1) (V2)路径 [a,b] 是共有前缀,[c](成为 extension/直接连接到 branch 继续分叉指向 leaf v1 和 leaf V2,子槽 f 指向 leaf 值是 V3。
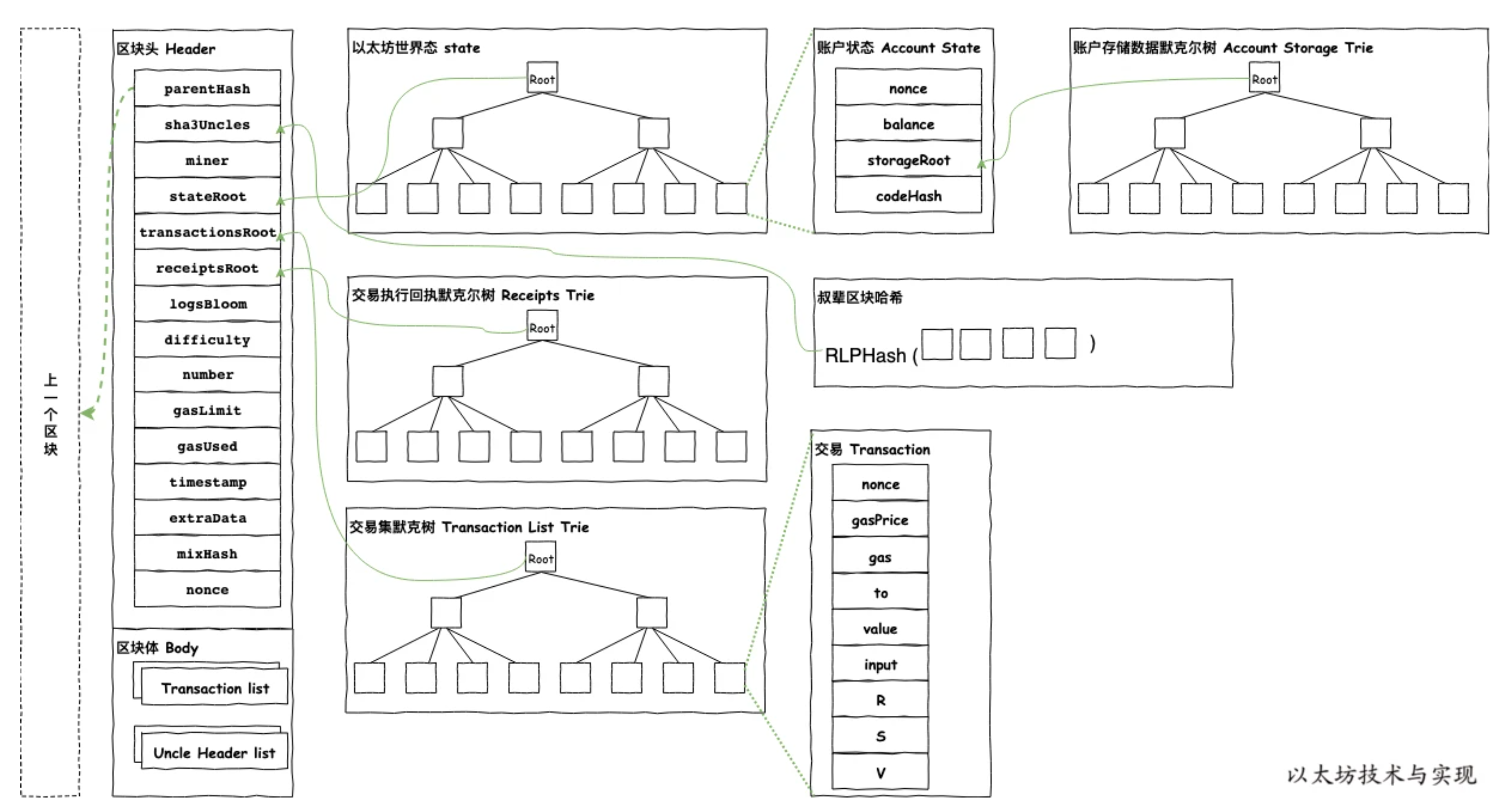
Block Header 四颗状态树
在 Block Header 里面有四棵树,状态树 (State Trie)、交易树 (Transactions Trie)、收据树 (Receipts Trie)、提款树 (Withdrawals Trie) 都是用 MPT 来构建的。
-
状态树 State Trie它记录了所有账户的全局状态(余额、nonce、合约代码、合约存储)。需要注意的是 这是唯一一棵持久化的树。它不只是记录这个区块发生的事,而是记录了在执行完这个区块的所有交易之后,以太坊全世界所有账户(包括智能合约)的最终状态。每个新区块都会在旧状态树的基础上进行“更新”,产生一个新的
stateRoot,其他不变的账号状态还是用原来的节点。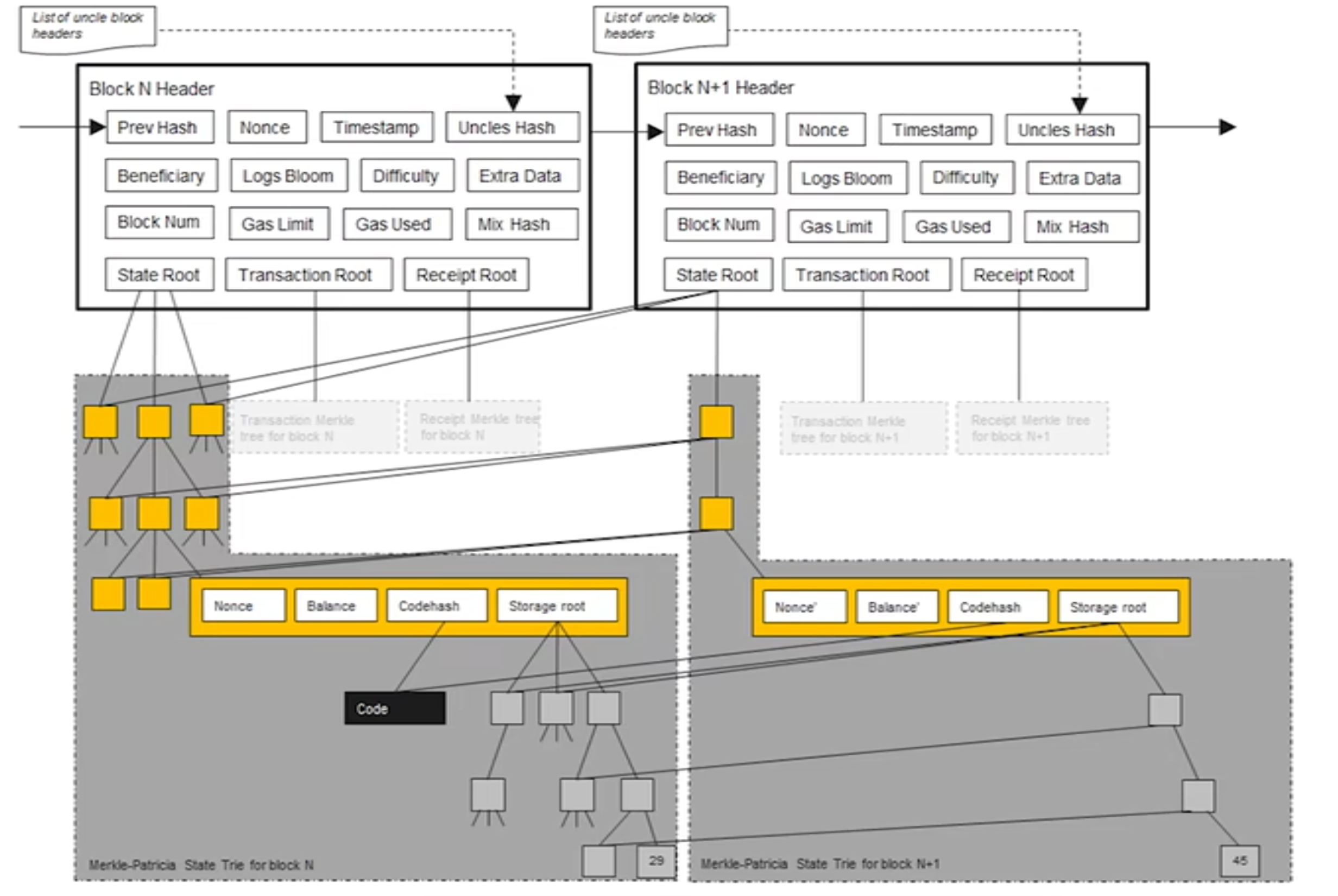
主要包含:
- 每个人的 ETH 余额。
- 每个账户的
nonce(交易计数)。 - 每个智能合约的
codeHash(代码)。 - 每个智能合约的
storageRoot(指向它自己的存储树)。
-
交易树 (Transactions Trie)里面包含当前区块中的所有交易。它的唯一目的就是按顺序存储仅属于这个区块的所有交易。
主要包含:
- 交易 0, 交易 1, 交易 2…
-
收据树 (Receipts Trie)包含当前区块中所有交易的执行回执(Receipts)。 这棵树对于 DApp 和钱包至关重要。当你想知道“我的交易成功了吗?”或者“某个智能合约是否触发了某个事件(Event)?”,你就是在这棵树里查找(或验证)这个“收据”。
主要包含:
-
交易 0 的结果:
status: success,gasUsed: 21000,logs: [...] -
交易 1 的结果:
status: failure,gasUsed: 50000,logs: []
-
-
提款树 (Withdrawals Trie)这是“上海/Shapella”升级后新增的,专门用于处理从信标链(共识层)提款到执行层的操作,它为质押提款提供了可验证的记录。
主要包含:
-
提款 0:验证者 A 提取 X ETH 到地址 B。
-
提款 1:验证者 C 提取 Y ETH 到地址 D。
-
logsBloom 日志布隆过滤器
在 ETH 的区块头还有一个logsBloom 字段,它使用布隆过滤器(Bloom Filter)来实现的,目的是为了做“快速索引”或“摘要”。
在以太坊上,智能合约通过触发“事件”(Events/Logs)来与外界(DApp 前端、钱包)通信。例如,一个 ERC-20 代币合约在转账时会触发一个 Transfer 事件。假设你的钱包想显示你所有的 ERC-20 代币转账记录。它该如何找到这些记录?
如果没有 logsBloom ,那么钱包必须下载整条链(几 TB 的数据),然后遍历每一个区块里的每一笔交易的每一条收据(Receipt),逐一检查其 logs 字段,看看是不是你想要的 Transfer 事件。这对于轻客户端(如手机钱包)或 DApp 前端来说是绝对不可能的。
logsBloom 巧妙的使用布隆过滤器(Bloom Filter)来构建区块中的交易触发的所有事件索引 log,当一个合约触发一个事件时,例如 Transfer(address indexed from, address indexed to, uint256 value),以太坊会把触发事件的合约地址和所有被 indexed (索引) 标记的参数(比如 from 和 to 的地址)“添加”到这个布隆过滤器中。
布隆过滤器(Bloom Filter)是一种概率型数据结构,它非常节省空间,专门用来回答一个问题:“某个东西可能 在这个集合里吗?”
它的回答只有两种:
- “绝对没有” (False): 如果它说“没有”,那这个东西 100% 不在集合里。
- “可能有” (True): 如果它说“有”,那这个东西有很大概率在集合里。(注意:它有很低的概率是“假阳性”,即它以为有,但其实没有)。
对 布隆过滤器(Bloom Filter)感兴趣的,可以去看我这篇文章:Go语言实现布谷鸟过滤器
那么有了这个 Log 我们就可以:
- 你的钱包想查找所有“发送到你地址
0xABC...”的Transfer事件。 - 它不需要下载整个区块。它只需要下载区块头(非常小)。
- 它检查区块头里的
logsBloom字段。 - 它向这个
logsBloom提问:“你这里面可能包含0xABC...这个地址吗?”
logsBloom 回答 “绝对没有”那么钱包100% 确定这个区块里没有任何一笔交易触发了与 0xABC... 相关的事件。logsBloom 回答 “可能有”钱包才会去下载这个区块的完整数据,来精确找到它要的 Transfer 事件。
工作量证明 & 权益证明
为什么要有共识机制
我们先来说一下为什么要有PoW (工作量证明) 和 PoS (权益证明) 这种共识机制,它们都是为了解决一个在计算机科学中极其古老且棘手的问题,尤其是在一个“去中心化”和“无需信任”的环境中,用来确保即使网络中充满了互不信任的陌生人(甚至有坏人),整个系统也能安全、一致地运行。
它们具体解决了以下三个关键问题:
-
防止"女巫攻击" (Sybil Attack) —— 谁有资格记账?
在一个开放的网络中,一个坏人几乎可以零成本地创建一百万个“假身份”(节点)。如果“记账权”是靠“一人一票”来决定的,那么这个坏人就能轻易地用他的“百万大军”投票控制整个网络。
因为在 web2 中,是有一个去中心化的节点来控制的,所以一般是通过认证与授权 (Authentication & Authorization)来实现的,但是 web3 中,是去中心化的,所以需要设计这样的共识机制,用它增加记账的门槛,防止坏人可以低成本的记账,对网络产生影响。
-
防止"双花" (Double-Spending) —— 如何确保账本不可篡改?
"双花"是数字货币的“原罪”。坏人张三有 10 ETH,他先发一笔交易给李四,同时(或之后)又发一笔交易把同样的 10 ETH 发给王五。网络必须决定哪一笔交易是“唯一真实”的。
在 web2 中,是通过 一个中心化的数据库 (Single Source of Truth) 来实现的,在web3中是一个分布式的账本,我如何确保所有人都同意“张三的 10 ETH 是先给了李四,而不是先给了王五”?
那么web3中就可以共识机制就可以设计一些有成本的操作,让“作恶成本”提高,来确保账本的唯一性和不可篡改性。
-
激励机制 (Incentives) —— 为什么有人愿意来记账?
既然保护网络这么昂贵(要买矿机或锁定 ETH),为什么会有人愿意做这件事?
在 Web2 中,不需要通过激励“陌生人”来进行记账,银行只需要商业模式 (Business Model) 和 雇佣 (Salary)机制来保障,不需要别人来记账。
但在web3中需要奖励机制来鼓励诚实者来进行记账,诚实节点地遵循规则、打包区块、验证交易,系统就会奖励你新发行的代币(例如 ETH)和用户支付的交易费。这样ETH 越有价值,你作为奖励收到的 ETH 就越值钱,你也就越有动力去保护它。
所以这也是为什么在 web3 中需要PoW (工作量证明) 和 PoS (权益证明) 这种共识机制。下面我们来看看这两种共识机制有什么区别。
PoW (工作量证明)其实就是需要矿工投入巨额的硬件成本和电费(物理工作)来解题。第一个解出题的就拥有的记账权。但是 PoW 有个极大的问题就是它不环保,浪费了大量的电来做这个事情。
那么就有人提议,其实PoW为了能去挖矿是需要投入巨量的硬件成本和电费,最后就是谁投入的钱多,谁就拥有这个记账权,既然如此,可以不可以直接点,直接用金钱来做抵押,那么这就是PoS (权益证明)基本理念,在 PoS 机制下,网络的安全不再依赖于消耗能源,而是依赖于经济激励和惩罚。
我们下面来详细看看 PoS 是怎么做的。
PoS (权益证明)
在 PoS 中验证者取代了 PoW 中的“矿工”。他们是运行特定软件的节点,负责处理数据、执行交易,并将它们打包成新的区块添加到链上。要成为一个验证者,你需要向一个特殊的智能合约中质押 32 个 ETH。
质押就是将 32 ETH 锁定,这部分的资金会在惩罚的时候用到,一旦发现作恶,作恶者的一部分质押金(最多 32 ETH)将被销毁(永久消失),并且该验证者将被强制踢出网络。比如在同一个时隙提议两个不同的区块(试图分叉),抑或是提交自相矛盾的投票(例如试图支持两条不同的链),这些都是作恶的行为。
在 ETH 中,是按时间来组织打包区块的,每个 固定的 12 秒时间段被称为 Slot,理论上每个 Slot 都会产生一个新区块。
每个 Slot,系统会随机选择一个验证者作为“区块提议者”(Proposer), 32 个Slot 组成一个Epoch(约 6.4 分钟)。
ETH 的 PoS 架构分为两层:
- 共识层 (Consensus Layer, CL):这是 PoS 的“大脑”。它不处理交易,只负责协调所有验证者、随机抽签、分发选票、统计投票,并就区块的顺序和有效性达成共识。
- 执行层 (Execution Layer, EL):这是“引擎”。它负责执行智能合约、处理交易、更新我们之前讨论的“状态树”(State Trie) 和其他三棵树。
具体步骤:
-
在每个 12 秒的 Slot 开始时,共识层会从所有验证者中随机抽选一个验证者,作为这个 Slot 的“提议者”(Proposer)。
-
提议者打包区块,被选中的 proposer:
- 从“执行层”的交易池 (Mempool) 中抓取一批交易。
- 打包这些交易,创建一个新的区块。
- 对这个新区块签名,并将其广播到整个网络。
-
共识层会为同一个 Slot 随机抽选一组(一个“委员会”/Committee),大约 100~几百个验证者组成的 Attestation 委员会(Committee)
委员会的工作:
- 它们会收到“提议者”广播的新区块。
- 它们验证这个区块的有效性(签名是否正确?交易是否合法?)。
- 如果有效,它们会投出“赞成票”(Attestation)。
- 广播 attestation 给全网
这些“赞成票”会汇集到共识层。
上面的讲述中,为了防止节点作恶,PoS 设计了一套安全机制。
如果诚实地参与提议和投票,验证者会获得两种奖励:
- 共识层奖励: 少量新发行的 ETH,作为维护网络安全的“工资”。
- 执行层奖励: 用户支付的“小费”(Priority Fees)。
如果节点作恶,那么就会执行相应的惩罚,这里的惩罚分为几种:
- 轻微惩罚 (Inactivity Leak):节点掉线了(例如停电、断网),没能及时投票,这样会损失掉本应获得的小额奖励;
- 严厉惩罚(Slashing):比如双重提议 (Double Proposing),在同一个 Slot 提议了两个不同的区块;双重投票 (Double Voting),同一个 Epoch 里投票给了两个竞争的区块(试图制造分叉)。这样做会将质押的 ETH 进行一定的销毁,并强制踢出验证者队列,永久失去参与共识的资格。
LMD-GHOST机制
还有就是真的就是有作恶者进行了分叉选择 (Fork-Choice),提议了两个不同的区块,或者网络延迟导致出现了两个竞争的区块(分叉),怎么办?
在 ETH 中是通过 LMD-GHOST 机制来保障。节点根据“所有验证者最近一次投票(attestation)”来决定哪条分支最“重”,从而选出链头(head)。
当你的以太坊节点需要确定“主链的头部是哪个区块”时,它会执行以下操作:
- 从一个已“最终确定” (Finalized) 的区块开始作为 root,Finalized 的区块一般是上个 Epoch 锁定的。
- 查看它“观测到”的、来自所有验证者的“最新”投票。
- 使用“贪婪”算法,从 root 出发,在每一个分叉路口,都选择那条其子树累计获得了最多“质押权重”投票的路径。
- 一直走到这条“最重”路径的末端(叶子区块),这个叶子区块就是当前的主链头部(Head)。
Casper FFG机制(FFG)
Casper FFG 就是 ETH 的最终性 Finality 的机制,用来决定哪些区块被不可逆地锁定。
因为LMD-GHOST 选出的“头部”是可以改变的。如果网络延迟很严重,或者有攻击者在故意制造分叉,LMD-GHOST 选出的“最重链”可能会在 A 链和 B 链之间“摇摆不定”。这样用户没法确定这笔存款是不是100%到账了。
在 BTC 中我们知道它是通过“6 个区块确认”来确保交易的理论安全,而 FFG 是通过 Epoch 来确定。
ETH 在每个 Epoch 的第一个区块设立了Checkpoint (检查点),FFG 会通常跨越两个 Epoch(约 13 分钟)来实现最终确定。
举个例子,假设我们现在处于 Epoch 100:
第一步:标记Justification (合理化)
- 所有验证者(委员会)会一起投票,连接“上一个检查点”和“当前检查点”,即投票支持
C(99) -> C(100)这条链; - 如果超过 2/3 的总质押 ETH 都投票给了这个连接;
C(100)这个检查点区块被标记为 "Justified" (合理化),但是 Justified只是意味着“这个区块看起来非常棒,全网大部分人都同意它在主链上”,但它还不是最终的。
第二部:Finalization (最终确定)
- 时间进入到了下一个 Epoch,Epoch 101;
- 验证者们再次投票,支持
C(100) -> C(101); - 如果
C(101)也获得了超过 2/3 的投票,它自己也变成了 "Justified"; - 此时,协议会回头看
C(101)的“来源”——C(100),因为C(100)本身是 "Justified" 的,所以协议在这一刻将C(100)的状态升级为 "Finalized" (最终确定);
小结
所以我们可以从上面看的出来 ETH 的 PoS 机制依靠验证者(质押 32 ETH)而非矿工来保护网络。其安全不靠算力,靠押金:诚实有奖,作恶(如双重签名)则被罚没 (Slashing)。
这套系统由两个协同工作的机制驱动:
- LMD-GHOST (选头部): 一个快速、灵活的规则,根据验证者的最新投票来选择“当前”的主链。
- Casper FFG (定最终): 一个缓慢、严谨的规则,通过“两步确认”将历史区块永久锁定(Finalized),使其不可逆转。
智能合约
简单来说:智能合约就是运行在以太坊区块链上的一段“自动执行的代码”。我们可以把它比喻成一台全自动贩卖机。
- 输入:你投币(转账 ETH)并选择商品(调用函数)。
- 逻辑:机器内部验证金额是否足够(代码逻辑判断)。
- 输出:吐出饮料(分发 Token 或 NFT)并找零。
- 特点:无需店员(去中心化),一旦设定无法随意更改价格(不可篡改)。
智能合约有这几个特点:
- 自动执行:一旦条件触发,就一定会执行,没人能阻止(连开发者本人也不行)。
- 不可篡改:部署到以太坊后,代码永远不能改(除非你一开始就写好升级机制)。
- 完全透明:全世界都能看到代码是什么(在Etherscan上点开任何合约都能看源码)。
- 去中心化:不靠任何公司或服务器,运行在全球几万台节点上,只要以太坊活着,它就活着。
- 用Gas付费:每次调用智能合约都要花一点ETH作为“燃料费”(Gas),防止有人写无限循环攻击网络。
一个最简单的“银行”合约
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract SimpleBank {
// 1. 状态变量 (State Variable)
// 这些数据会永久写入区块链,类似于数据库中的表
mapping(address => uint256) public balances;
// 2. 事件 (Event)
// 类似于日志系统,用于前端监听
event Deposit(address indexed user, uint256 amount);
// 3. 函数:存款
// payable 关键字表示该函数可以接收 ETH
function deposit() public payable {
require(msg.value > 0, "Deposit amount must be greater than 0");
// msg.sender 是调用者的地址
balances[msg.sender] += msg.value;
emit Deposit(msg.sender, msg.value);
}
// 4. 函数:提款
function withdraw(uint256 amount) public {
require(balances[msg.sender] >= amount, "Insufficient balance");
balances[msg.sender] -= amount;
// 将 ETH 转回给用户
payable(msg.sender).transfer(amount);
}
}-
mapping就是 Key-Value 存储(类似于 Redis),address是 Key,uint256是 Value。 -
msg.sender和msg.value是全局注入的上下文变量(Context),无法伪造。 -
require类似于 Assert 或中间件校验,如果不通过,整个事务回滚。
原子性
需要注意的是,智能合约的每次执行具有原子性,比如像上面这个银行的例子,如果失败了,就整个操作进行回滚,不存在中间状态;如果所有步骤都成功,所有的状态变更(State Changes)会被一起写入区块,永久生效。其实这就有点像数据库的事务。
熟悉数据库的朋友我可以这么解释:
在 EVM(以太坊虚拟机)中,每一笔交易天然就是一个隐式的 START TRANSACTION ... COMMIT 块。你不需要显式地写 Commit,但任何未捕获的错误都会触发自动 Rollback。
跨合约组合(Composability)
原子性不单单局限于单个合约内部,而是可以跨越多个合约的调用链。
假设一笔交易的调用链是这样的:
用户 -> 合约 A -> 合约 B -> 合约 C
如果在 合约 C 的执行中出错了:
- 合约 C 的状态回滚。
- 合约 B 的状态回滚。
- 合约 A 的状态回滚。
- 用户发起的这笔交易被标记为“失败”
这里就有一个问题,执行失败会收 Gas 费吗?我们先看看什么是 Gas 费
Gas 费
Gas 费本质上等于:工作量(Gas Units)X 单价(Gas Price)。
Gas Units(工作量/计量单位)
EVM(以太坊虚拟机)执行的每一个操作码(Opcode)都有一个固定的 Gas 消耗值,操作越复杂,消耗越高。
比如下面这些操作:
计算操作(便宜):
ADD(加法): 3 GasMUL(乘法): 5 GasKECCAK256(哈希计算): 30 Gas + 动态数据费用
存储操作(极贵):
SSTORE(写入/修改状态变量): 20,000 Gas (这是最贵的操作之一)SLOAD(读取状态变量): 2,100 GasLOG(生成日志): 375 Gas
基础费用:
- 发起一笔最简单的转账交易(不调用合约):固定 21,000 Gas。
Gas Price(单价/市场汇率)
这是由市场供需决定的变量。Gas Units 是“你需要多少升油”,Gas Price 就是“今天加油站一升油卖多少钱”。
Gas 的单位是 Gwei:
- 1 ETH = 10^18 Wei
- 1 Gwei = 10 ^9 Wei (即 0.000000001 ETH)
动态定价:
- 网络拥堵时:大家都在排队提交交易,为了插队,你必须出高价(比如 100 Gwei)。这就像滴滴打车的“高峰溢价”。
- 网络空闲时:价格下降(比如 10 Gwei)。
最终计算公式
现在的以太坊(EIP-1559 升级后)计费变得稍微复杂了一点点,分为两部分:
Tx Fee = Gas Used X (Base Fee + Priority Fee)- Base Fee (基础费):
- 系统自动定。根据上一个区块满了没,自动调整。
- 这部分钱会被“销毁”(Burned),也就是说这部分 ETH 直接从流通总量中消失了(通缩机制)。
- Priority Fee (小费/优先费):
- 你给矿工/验证者的红包。
- 如果你想让交易快点确认,就多给点小费,验证者会优先打包小费高的交易。
举个具体的例子:
假设你要在这个拥堵的周五晚上,调用一个合约函数 buyItem()。
A. 代码层面(Gas Units) EVM 跑完你的代码,发现你做了一次加法,写了一次数据库,总共消耗了 50,000 Gas。
B. 市场层面(Gas Price) 当前的 Base Fee 是 50 Gwei,为了快点成交,你给了 2 Gwei 的小费。 总单价 = 52 Gwei。
C. 你的账单
花费 = 50000(Units)X 52(Gwei) = 2,600,000 Gwei换算成 ETH 就是 0.0026 ETH。 假设 ETH 现价 $3000,这笔操作就要花你 $7.8 美金。
操作失败会收 gas 费吗?
两种失败场景的区别:
在 EVM 中,交易失败主要分两种情况,扣费逻辑略有不同:
-
场景 A:Gas 耗尽(Out of Gas)
Gas Limit 是预算上限,假如设置了100,000Gas ,意思是“我这笔交易最多允许烧掉 100,000 Gas,再多我就不付了”。
如果代码跑到 100,000 还没跑完(Out of Gas),EVM 强制停机,这 100,000 的钱全部扣掉不退,且交易回滚。
-
场景 B:逻辑错误(Revert / Require 失败)
比如转账余额不足、权限不够。比如代码运行到第 10 行,触发
require(false)。这样只扣除前 10 行代码消耗的 Gas。剩余未使用的 Gas(即Gas Limit - Gas Used)会退回到你的钱包。
为什么要这么设计?
对于去中心化网络,这是为了防止 DDoS 攻击(拒绝服务攻击)。 如果失败不收费,黑客可以写一个无限循环的恶意合约:
while(true) { i++; }然后向网络发送几百万笔交易来调用它。如果不收费,全网节点的 CPU 就会被免费占用,导致网络瘫痪。
小结
我们可以看出ETH的智能合约,把区块链从“账本”升级为了“通用计算平台”。没有智能合约,区块链就只能炒币(Store of Value);有了智能合约,区块链才有了应用层(Application Layer),多了更多的活力和玩法。
比如:
- Uniswap(去中心化交易所 – AMM),它没有传统股票交易所的“订单薄”(Order Book),没有挂单和吃单的概念;
- Aave / Compound (去中心化借贷),资金池模式。存款人把钱扔进池子拿利息,借款人抵押资产从池子借钱付利息;
- MakerDAO (去中心化稳定币 – DAI),相当于是以太坊上的“美联储”,通过合约抵押的方式,生成一个永远锚定 1 美元的币(DAI);
还有很多有意思的玩法,我这里就不一一列举了,如果要深入学习智能合约的话,可以看这几个教程:
https://cryptozombies.io/ 通过建一个“僵尸养成”区块链游戏,一步步教你写Solidity智能合约。
https://docs.soliditylang.org/ Solidity官方英文文档
https://www.wtf.academy/zh/course/solidity101 WTF Solidity极简教程
如何在ETH链上发币?
ETH 社区定义了 ERC-20 标准的 API 接口规范,任何一个智能合约,只要实现了这套规定的 API(方法和事件),它就是一个 ERC-20 代币。
我们可以把代币想象成存储在一个巨大的 Map 里面,比如这样的一个结构:
// 这是一个简化的核心存储结构
contract ERC20 {
// 1. 账本:记录 "地址 -> 余额"
mapping(address => uint256) private _balances;
// 2. 授权表:记录 "我 -> 授权给谁 -> 多少钱"
mapping(address => mapping(address => uint256)) private _allowances;
// 3. 代币总供应量
uint256 private _totalSupply;
}当你发起一笔转账(例如 A 转给 B 100个币)时,EVM(以太坊虚拟机)到底做了什么?
- 交易发起:用户 A 向该代币合约地址发起一笔调用
transfer(B, 100)的交易。 - 余额检查:EVM 检查
_balances[A]是否大于等于 100。 - 数据重写:
_balances[A] = _balances[A] - 100_balances[B] = _balances[B] + 100
- 持久化:这些修改后的数据被写入以太坊的状态树(Merkle Patricia Trie),并打包进新的区块中,永久不可篡改。
数据结构
我这边再引用一下上面的图,合约其实在 ETH 里面也是一个账户对象,当你通过地址找到这个账户(比如那个 ERC-20 代币合约地址)时,你会得到一个包含四个字段的结构体:
Nonce: 交易计数器。
Balance: 这里存的是 ETH 的余额(比如 0.5 ETH),不是代币余额。
CodeHash: 智能合约的代码哈希(如果是普通账户则为空)。
StorageRoot (存储根): 这是一个哈希值,它指向了另一棵 MPT 树的根节点。这棵树专门属于这个合约,用来存储它所有的变量数据。
StorageRoot (存储根)
这棵树本质上是一个巨大的、持久化的 Key-Value 映射,其实也是一颗 MPT 树。
- Key: 32 字节(256位)的存储槽位置 (Slot Index)。
- Value: 32 字节(256位)的数据内容。
比如这样一个代币合约:
contract MyToken {
// Slot 0: 假如这里有个 owner 变量
address owner;
// Slot 1: 假如这里是总供应量
uint256 totalSupply;
// Slot 2: 这里就是代币余额的 Mapping
mapping(address => uint256) private _balances;
}当 EVM 运行到 _balances 时,它并不会把整个 Mapping 存在 Slot 2 里面(因为 Mapping 大小是不确定的)。 它是通过哈希算法计算出具体的存储位置。
如果你想查 0xUserA 这个人的余额,数据存储在 Storage Trie 中的 Key 是这样算出来的:

- 0xUserA: 用户的钱包地址(补齐到 32 字节)。
- SlotIndexOfMapping:
_balances变量在代码中声明的位置(假设是 Slot 2)。 - keccak256: 对这两个拼接后的数据进行哈希运算。
运算得出的结果(一个乱码一样的哈希值),就是该用户余额在底层的物理存储地址。 而这个位置对应的 Value,就是 uint256 类型的余额数值。
所以如果要查询代币的值,整个查找链条是这样的:
-
Block Header -> 拿到
StateRoot。 -
World State Trie -> 用
TokenContractAddress查找 -> 拿到 Account Object。 -
Account Object -> 拿到
StorageRoot(进入该合约的私有数据库)。 -
Storage Trie -> 计算
keccak256(UserAddress + SlotIndex)作为 Key -> 拿到余额数据。