随着 AI Agent 技术演进,从目前来看 AI Agent 架构大概被划分越来越清晰,我们参考《The Rise and Potential of Large Language Model Based Agents: A Survey》这篇论文里面的 Agent 架构定义,大概划分为以下几个部分:
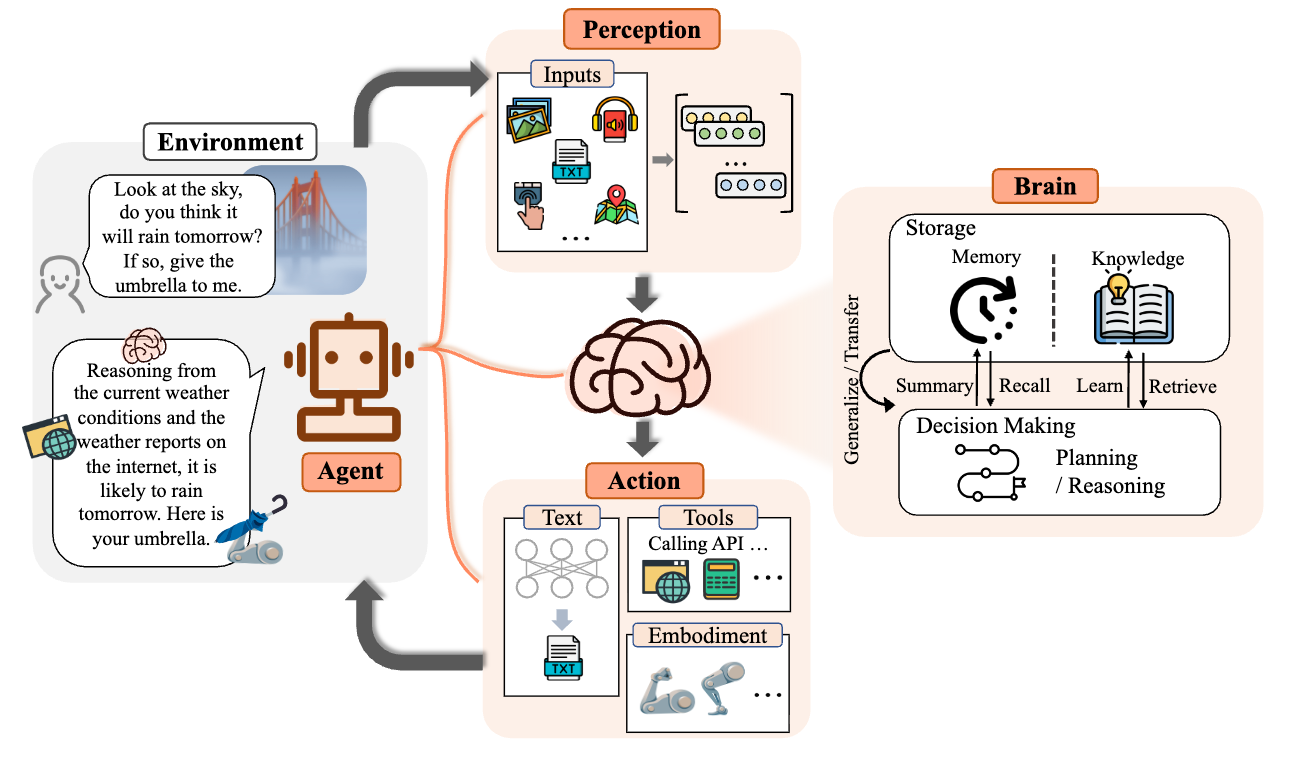
- 感知区(Perception):负责将现实世界的原始数据转化为 Agent 能理解的语言,包括图像、文本、音频、触觉、位置信息等特征提取;
- 决策区(Brain-Decision Making):让 Agent 具备逻辑链条的推演,能够将复杂目标拆解从而得到答案;
- 存储区(Brain-Memory & Knowledge):让 Agent 具备记忆能力,记忆内部存储了 Agent 的知识和技能,并且可以通过类似于 RAG(检索增强生成),去查说明书或数据库将新知识内化;
- 行动区(Action):让 Agent 具备与外界交互的能力,可以调用外部 API,甚至通过物理实体感知环境做出行动;
那么我们本篇文章讨论的“记忆”其实是更广泛的存储区这块功能。对于 AI Agent 记忆来说,记忆其实就有点像脑容量,其核心必要性体现在以下三点:
-
上下文一致性 (Contextual Consistency):
Agent 需要记住之前的对话内容,才能理解当前的指令。例如,如果你先说“帮我订一张去上海的机票”,接着说“改到明天”,Agent 必须记得“去上海的机票”这个前提。
-
长期偏好学习 (Personalization):
通过记忆,Agent 可以学习用户的习惯(如:你偏好 Python 而不是 Java,或者你习惯在周五下午复盘)。
-
复杂任务拆解 (Task Decomposition & Planning):
在执行多步任务(如:写代码 -> 测试 -> 找 Bug -> 修复)时,Agent 需要记录每一步的状态,确保不会陷入循环或丢失进度。
记忆分类
在 AI Agent 领域记忆通常效仿人类的认知结构,分为以下层次:
-
短期记忆 (Short-term Memory):利用大模型的 Context Window(上下文窗口),将最近的几轮对话记录直接放入 Prompt 中发送给模型,抑或是工具调用结果、中间推理状态、任务临时变量,但是受限于模型能够处理的最大 Token 数量,一旦对话过长,旧的信息就会被“挤出”。
这部份数据我们可以存储在内存中,配合TTL(Time To Live)机制进行自动清理。这种设计的优势在于访问速度极快,但也意味着工作记忆的内容在系统重启后会丢失。这种特性正好符合工作记忆的定位,存储临时的、易变的信息。
-
长期记忆 (Long-term Memory):这相当于人类的“经验仓库”,可以存储海量信息并在需要时检索,可以通过各种数据库进行存储,一般来说可以做如下分类:
- 情境记忆 (Episodic Memory):记录 Agent 过去的经历和日志,它存储了之前决策周期的序列。例如:“上次我尝试解决这个问题时发生了什么?”这有助于 Agent 从过去的成功或失败中学习。
- 语义记忆 (Semantic Memory):存储关于世界和 Agent 自身的事实性知识,它不依赖于具体的经历。例如,“北京是中国的首都”或者用户的基本偏好。在技术实现上,这通常对应于 RAG(检索增强生成)所调用的外部知识库。
- 程序性记忆 (Procedural Memory):存储“如何做”的技能和规则。写在 Agent 代码中的逻辑,例如 Prompt 模板、工具调用说明或决策流程。
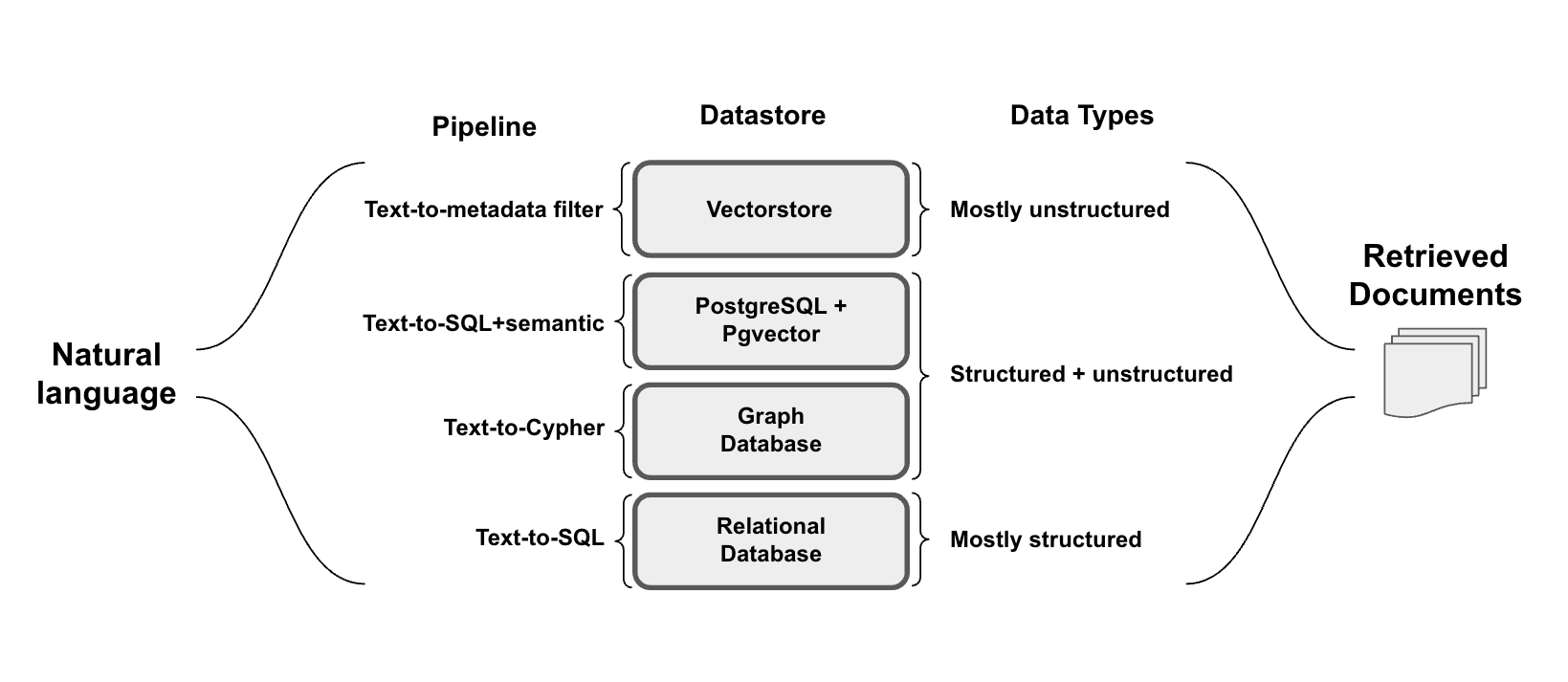
所以我这里借用一下 langchain 官方的一张图,agent memory 的存储其实就是选用合适存储的过程,针对不同数据类型将自然语言查询转化为特定数据库查询的方法。
记忆操作
记忆的核心操作其实就两个:
- 存储(Storage):在短期记忆或长期记忆中保留编码信息的过程;
- 提取(Retrival):也可称为回忆,即在需要时访问并使存储的信息重新进入意识的过程;
存储
对于存储关于世界和 Agent 自身的事实性知识,我们通过 RAG(检索增强生成)所调用的外部知识库来实现,这部份我们单独拿出来说。这里我们先说说记录 Agent 过去的经历和日志的情境记忆 (Episodic Memory)。
我们将这种Episodic Memory分为三部份来进行存储:
- 向量库保存当前记忆正文和 metadata(主存)
- 关系数据库保存每次变更历史,方便查询(审计日志)
- 将记忆进行关系提取以“实体-关系”图(Knowledge Graph)的形式存储;
存储的核心主要包含两个关键阶段:
-
提取阶段(Extraction Phase):
系统从当前的对话消息和历史背景中,动态地提取出“显著信息”(Salient Information)。它不是简单地存储对话记录,而是将其转化为简练、事实性的“记忆片断”。
-
更新与整合阶段(Update Phase):
当新的记忆提取出来后,将其与现有的相似记忆进行对比:
- 添加(Add): 存储全新的事实。
- 更新(Update): 如果用户信息发生了变化(例如:用户以前说喜欢咖啡,现在改说喜欢茶),系统会自动覆盖或修正旧记忆。
- 冲突解决: 自动处理矛盾信息,确保记忆库的一致性。
提取阶段(Extraction Phase)
做提取核心原因是把“原始对话”压缩成“可检索、可更新、可复用”的结构化记忆。
- 降噪
原始聊天里有大量寒暄和上下文噪声,facts 只保留真正值得记住的信息(偏好、身份、计划等)。 - 提升检索命中
向量库里存短而清晰的事实,比存整段对话更容易在 search 时命中相关内容。 - 支持记忆演化
提取出 facts 后,系统才能做 ADD / UPDATE / DELETE / NONE,处理“用户改口/信息过期/冲突事实”。 - 降低 token 和成本
后续回答时注入的是少量关键 facts,不是整段历史,响应更稳、成本更低。 - 个性化更可靠
facts 是“可解释”的记忆单元,能更稳定地驱动个性化回答,而不是靠模型在长上下文里猜。
我们这里使用 LLM 抽取,让模型按固定格式输出{"facts":[...]},灵活、效果好,是现在最常见方案。主要是分成这么几步来实现:
- 首先要对消息做 parse_messages,拼成
user:/assistant:/system; - 然后就是选取 prompt ,提取阶段我们需要根据 user message 和 agent message 来做抽取,两者的 prompt 是不同的;
- LLM 要求返回 JSON:
{"facts":[...]} - 对每条 fact 做向量检索找旧记忆,再进入到下一个更新与整合阶段;
我们来看个例子具体怎么提取的:
对话输入:
- user: 我叫小王,在北京做后端开发。我乳糖不耐受,平时喜欢跑步。
- assistant: 收到,小王。我擅长 Python 和系统设计,回答会尽量简洁。我个人偏好用表格总结。
user 会提取出:
{
"facts": [
"名字是小王",
"在北京做后端开发",
"乳糖不耐受",
"平时喜欢跑步"
]
}assistant 会提取出:
{
"facts": [
"擅长 Python 和系统设计",
"回答风格尽量简洁",
"偏好用表格总结"
]
}再看一个“无可提取信息”的例子,对话输入:
- user: 今天天气不错。
- assistant: 是的。
{"facts": []}更新与整合阶段(Update Phase)
这一阶段会用第一阶段提取出来的 facts 来进行记忆的更新与整合。主要是分成这么几步来实现:
- 每条 fact 先做 embedding,再查相似旧记忆;
- 对数据进行合并和去重,整理去新旧记忆;
- 然后让 LLM 做更新决策,把“旧记忆+新 facts+输出 JSON 约束”拼成 prompt,再让 LLM 返回:ADD / UPDATE / DELETE / NONE
我们在让 LLM 做更新决策的时候需要根据 4 个明确模块,降低 LLM 自由发挥空间:
-
放入“操作规则与判定标准”
在我们给定的 UPDATE_MEMORY_PROMPT 里面需要定义了 ADD/UPDATE/DELETE/NONE 的语义和多个 few-shot 示例,让 LLM 具体了解到更新规则;
-
放入“当前记忆状态”
如果有旧记忆,就把旧记忆数组包在代码块里;否则明确写 Current memory is empty。这样 LLM 是在“当前状态机”上做增删改,而不是凭空生成。比如这样拼接 prompt:
if retrieved_old_memory_dict: current_memory_part = f""" Below is the current content of my memory which I have collected till now. You have to update it in the following format only: {retrieved_old_memory_dict} else: current_memory_part = """Current memory is empty. """ -
放入“新 facts 输入”
把新抽取的 facts 明确告诉模型:你只需要判断这些新事实对当前记忆该怎么处理。比如这样:
The new retrieved facts are mentioned in the triple backticks. You have to analyze the new retrieved facts and determine whether these facts should be added, updated, or deleted in the memory. -
最后强约束输出格式
函数把目标输出 schema 写死为:
{"memory":[{"id","text","event","old_memory"}]},并加“Do not return anything except JSON format”这能显著提高可解析性,方便后续程序按 event 执行。
我们举个完整例子:
假设旧记忆是:
[
{"id": "0", "text": "喜欢奶酪披萨"},
{"id": "1", "text": "是后端工程师"}
]新 facts 是:
["喜欢鸡肉披萨", "在准备转管理岗"]然后 LLM 可能返回:
{
"memory": [
{
"id": "0",
"text": "喜欢奶酪和鸡肉披萨",
"event": "UPDATE",
"old_memory": "喜欢奶酪披萨"
},
{
"id": "1",
"text": "是后端工程师",
"event": "NONE"
},
{
"id": "2",
"text": "在准备转管理岗",
"event": "ADD"
}
]
}后续程序按 event 执行真正落库(新增/更新/删除)。
Graph 存储
再来将一下Graph存储怎么做。Graph核心优势在于它不再是零散的“事实点”,而是形成了“知识网”。在处理复杂逻辑、跨时空关联和深度偏好挖掘时,这种方式比简单的纯文本记忆要强大得多,并且不像向量数据库只能进行相似度进行检索,而是可以沿着已知的节点和边,像找地图一样寻找关联。
我们来举例几个场景:
-
复杂的人际关系网(社交/CRM 场景)
如果一个 AI 助理只记录纯文本,它可能记得“王总喜欢红酒”和“李女士是王总的太太”。但当你要策划一场晚宴时,基于图的记忆能迅速通过“配偶”关系推导出两者的关联,AI 就可以根据提问信息进行实体和关系的抽取:
- 实体:
王总、李女士、红酒 - 关系:
[王总] --(配偶)--> [李女士],[王总] --(偏好)--> [红酒]
- 实体:
-
跨 session 的逻辑排产与项目追踪
在长期的项目管理中,任务之间存在前置、后置和依赖关系。比如根据我们的文档 AI 可以抽离出下面实体和关系:
- 实体:
模块 A 设计、前端开发、后端 API、张工 - 关系:
[前端开发] --(依赖于)--> [后端 API],[张工] --(负责)--> [后端 API]
如果张工今天请假了,基于图的记忆能立刻感知到:这不仅会耽误“后端 API”,还会连锁反应导致“前端开发”停滞。
- 实体:
-
个性化推荐中的“归因”与“反转”
传统的向量检索(Vector Search)有时会因为语义接近而产生误导,但图结构可以做到精准的时间戳与状态管理。比如用户在 2023 年说“我最讨厌吃香菜”,但在 2024 年说“我尝试了香菜拌牛肉,竟然觉得不错”,那么可以抽取出:
- 实体:
时间、态度、物品 - 关系:
[用户] --(2023 态度: 厌恶)--> [香菜],[用户] --(2024 态度: 接受)--> [香菜]
图结构可以带标签(如时间、强度)。当 AI 决定今天点餐建议时,它能通过有向边的“时间戳”属性,识别出最新的态度已经覆盖了旧的态度,从而避免因为检索到旧文本而一直提醒你“别放香菜”。
- 实体:
同样的我们也需要分几步通过约束和关系的抽取让我们产生的结果更加可控:
-
LLM 抽实体+类型
这一步主要是做主体的提取相应实体和类型,规范输出结果,主要用于后续入库时给节点打 label/type(以及默认类型回退),比如输入文本:
我叫小王,在字节跳动做后端开发,住在北京。得到结果大致会变成:
{ "name": "extract_entities", "arguments": { "entities": [ {"entity": "小王", "entity_type": "person"}, {"entity": "字节跳动", "entity_type": "organization"}, {"entity": "后端开发", "entity_type": "profession"}, {"entity": "北京", "entity_type": "location"} ] } } -
LLM 抽关系三元组
这一步是为了把上一步抽取的实体和类型让 LLM输出 source/relationship/destination,比如上面的例子这里会生成:
{ "name": "establish_relationships", "arguments": { "entities": [ {"source": "小王", "relationship": "works_at", "destination": "字节跳动"}, {"source": "小王", "relationship": "has_profession", "destination": "后端开发"}, {"source": "小王", "relationship": "lives_in", "destination": "北京"} ] } } -
用实体 embedding 在图里查相近旧节点/关系,再用 LLM 判定要删哪些旧关系,再执行 ADD / UPDATE / DELETE
这里我举例说明一下,比如用户先后两次输入:
-
我在字节跳动做后端,住在北京。(首次输入)
抽到关系后入图:
- (小王, works_at, 字节跳动)
- (小王, lives_in, 北京)
-
我现在在字节工作,搬到北京市朝阳区了。(过了一段时间后)
新实体可能是:小王 / 字节 / 北京市朝阳区
接下来就会检索和新旧关系的判定
-
查 字节 最相近旧节点
- 与图中 字节跳动 相似度很高(假设 0.93,阈值 0.7)
- 复用旧节点 字节跳动,不新建 字节
-
查 北京市朝阳区 最相近旧节点
- 与 北京 也许中等相似(如 0.76)
- 是否复用取决于阈值和语义;常见会保留成新节点(更具体地名)
-
拿这些相近节点的旧关系给 LLM 看
- 旧关系里有 (小王, lives_in, 北京)
- 新信息是“搬到北京市朝阳区”
- 删除判定阶段可能删掉旧 lives_in -> 北京,新增 lives_in -> 北京市朝阳区
最终图可能变成:
- (小王, works_at, 字节跳动)(保留)
- (小王, lives_in, 北京市朝阳区)(新增)
- (小王, lives_in, 北京)(删除或保留,取决于模型判定)
-
提取(Retrival)
对记忆的提取也是分两块进行提取:
- 向量库检索,先把 query 做 embedding,然后调用具体向量库进行召回;
- 图检索,先抽实体,再用图数据库里的向量相似度查关系;
- 最后把结果分别返回;
这里就是常规逻辑。
RAG 知识检索增强
上面我们有提到过,当需要关于世界和 Agent 自身的事实性知识,它不依赖于具体的Agent经历。例如,“北京是中国的首都”或者用户的基本偏好,在技术实现上,这通常对应于 RAG(检索增强生成)所调用的外部知识库。
RAG 核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
一个完整的 RAG (Retrieval-Augmented Generation,检索增强生成) 应用流程可以分为两个核心阶段:离线数据处理 (Ingestion) 和 在线检索生成 (Inference)。
-
离线阶段:数据准备与索引 (Data Ingestion)
这是 RAG 的“地基”,目的是将非结构化的知识变成 AI 能够理解和检索的格式。
-
文档加载 (Loading): 从 PDF、Word、Markdown 或数据库中提取文本。
-
文本分割 (Chunking): 将长文章切分为较小的、语义完整的段落(Chunks)。
为什么? 因为 LLM 有上下文窗口限制,且过长的信息会稀释检索精度。
-
向量化 (Embedding): 调用 Embedding 模型(如 OpenAI
text-embedding-3或本地的BGE),将文本转换为高维向量。 -
向量存储 (Vector Storage): 将这些向量连同原始文本存储在向量数据库中(如 Pinecone, Milvus, Chroma)。
-
-
在线阶段:检索 (Retrieval)
当用户提出问题时,系统开始“翻书”。
- 查询向量化: 将用户的提问(Query)转换成同一维度的向量。
- 向量检索: 在数据库中寻找与提问向量相似度最高(通常用余弦相似度计算)的前 k 个文档片段。
数据的写入
通过我们上面的简单介绍,应该可以知道写入流程是这样:
任意格式文档 → MarkItDown转换 → Markdown文本 → 智能分块 → 向量化 → 存储检索下面我们简单的讨论一些细节。
MarkItDown转换
MarkItDown 是微软(Microsoft)开源的一款非常实用的工具。它主要的目的是用来处理多模态的数据,无论是 PDF, Word (docx), PowerPoint (pptx), Excel (xlsx) 还是图片、音频内容,将各种格式的非结构化数据,一键转换为干净、标准的 Markdown 格式。
对于图片数据,它会调用多模态模型通常配置指向一个多模态大模型(如 GPT-4o 或 Claude 3.5 Sonnet),模型会分析图片中的场景、物体、文字(OCR)以及图表趋势,将生成的描述文字。比如 PDF 里面有一张图片,那么会抽取成:
对于音频内容,MarkItDown 一般会结合 OpenAI Whisper 等语音识别模型将音频中的对话或旁白完整转录为文本,转录后的文本会作为该音频文件的“代表内容”存入 Markdown 结果中,使其可以被向量化并检索。
智能分块
在 RAG 应用中,分块(Chunking) 是决定检索质量的生死线。如果分块太小,会丢失上下文;如果分块太大,会引入过多噪音并导致 LLM 无法处理。
目前市面上主流的几种分块策略有:
- 基于句法结构的语义分块:利用文档自身的层级结构(如
#标题、##子标题)进行切分。 识别 Markdown 或 HTML 的标题标签,将属于同一标题的内容聚合成一个块; - 递归字符分块:按“优先级顺序”寻找分隔符进行拆分,比如可以预设一个分隔符列表(如
["\n\n", "\n", " ", ""]),首先尝试按段落(\n\n)切,如果某一段还是太长,再按句子(\n)切,依然太长,就按空格切; - 语义相似度分块:这种是根据文字的意思进行拆分,它会将文档拆成单个句子,然后计算相邻两个句子的 Embedding(向量),计算它们的余弦相似度。如果两个句子之间的“语义断层”很大(相似度低于阈值),就说明这里是主题转换点,在此处切断;
- 代理分块:利用大模型(LLM)来决定哪里该切。让 LLM 阅读文本,然后询问 LLM:“这段话里有几个独立的主题?请在主题转换处插入切分符。”
其实上面智能程度和计算成本是成反比的,越只能的策略通常来说也越贵。
| 策略 | 智能程度 | 计算成本 | 适用场景 |
|---|---|---|---|
| 固定字符 | 低 | 极低 | 性能要求极高的基准测试 |
| 递归结构 | 中 | 低 | 通用场景(推荐首选) |
| 语义相似度 | 高 | 中 | 缺乏明显格式的非结构化论文/报告 |
| Agentic/LLM | 极高 | 高 | 高价值、高准确度要求的核心文档 |
数据的检索
RAG系统将数据存好之后,核心的竞争力还是在检索。RAG 的基本思路是根据用户输入检索出最相关的内容,但是用户输入是不可控的,可能存在冗余、模糊或歧义等情况,如果直接拿着用户输入去检索,效果可能不理想。所以我们可以通过一些策略来优化查询效果。
查询扩展策略 (Query Expansion Techniques)
查询扩展(Query Expansion) 就是把用户的原始提问“整容”或“分身”,变成更多、更丰富的表达方式。它的存在是为了解决 RAG 系统中的一个顽疾:词项不匹配(Term Mismatch)。比如用户搜“番茄”,但文档里写的是“西红柿”,基础检索可能就会完美错过。
查询扩展有多种不同的实现,比如:
多查询(Multi-Query)
这是最常见的扩展方式。让 LLM 站在不同角度,把你的问题重写成 3-5 个意思相近的问题。比如提问:“如何让猫爱上喝水?”,可以被扩展成:
-
“猫咪饮水习惯的诱导方法有哪些?”
-
“增加宠物猫饮水量的实用技巧。”
-
“哪些因素会影响猫对水源的偏好?”
后退提示 (Step-back Prompting)
它是 Google DeepMind 团队在论文 Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models 中提出的一种新的提示技术。
基本原理简单来说就是,如果你的问题太细节,检索效果往往不好。查询扩展会先退一步,问一个更宏观的原理。比如提问:“为什么我的 2023 款 MacBook Pro 跑 Python 特别烫?”,后退一步可能是:
- “笔记本电脑在高负载运行代码时的散热机制和性能限制因素是什么?”
帮助系统先检索到大框架知识,辅助回答具体细分问题。
假设文档 (HyDE)
HyDE 是 Luyu Gao 在 Precise Zero-Shot Dense Retrieval without Relevance Labels ,它的核心思想是"用答案找答案"。传统的检索方法是用问题去匹配文档,但问题和答案在语义空间中的分布往往存在差异——问题通常是疑问句,而文档内容是陈述句。HyDE 与其用一个“问题”去搜“答案”,不如先编一个“假答案”,然后用“假答案”去搜“真答案”
比如提问:“那个两个粒子互相感应的物理现象叫什么?”,检索效果差往往是因为 Query(问题) 和 Document(文档) 处于不同的语义空间,因为文档通常很长且是陈述句: “当两个或多个粒子以特定的方式结合在一起时,它们的状态就变得不可分割。即使你把这两个粒子分别放在宇宙的两端,它们依然保持着这种奇……”。
所以,我们可以让LLM 生成假答案: “这种现象通常指量子纠缠,即两个粒子在空间上分离但状态紧密关联……”,带着这段话去搜。因为假答案里包含了“量子纠缠”、“空间分离”、“状态关联”等学术词汇,它能精准地在论文中找到对应的章节。
RAG Fusion
最后还需要提一下 RAG Fusion,这是它的论文地址 https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf 。比如当你用查询扩展生出了 5 个问题,去检索得到了 5 份不同的答案排名,这时候就会出现矛盾:文档 A 在问题 1 里排第一,在问题 2 里排第十。RAG Fusion 就是那个负责“打分合并”的裁判。它利用 RRF(倒数排名融合) 算法进行打分。
比如现在有个原始问题: “如何在北京申请居住证?”,然后我们扩展成:
-
分身 1: 北京居住证办理流程是什么?
-
分身 2: 北京居住证申请需要什么材料?
-
分身 3: 外地人在北京办居住证的条件。
然后我们得到检索结果,文档 A(《北京人口管理条例》):在分身 1 搜到排第 3,分身 2 搜到排第 2,分身 3 搜到排第 5。文档 B(一篇非官方博客):在分身 1 搜到排第 1,但在其他两个搜索里都没出现。
经过 RRF 计算,文档 A 虽然没有拿过第一,但因为它在三个维度都被认定为高度相关,最终总分会反超文档 B。这样就过滤掉了偶然性极高的干扰信息。
查询重写(Query Rewriting)
Xinbei Ma 等人在论文Query Rewriting for Retrieval-Augmented Large Language Models提出了一种 Rewrite-Retrieve-Read 的方法,对用户的输入进行改写,以改善检索效果。在传统的 RAG(检索 -> 阅读)流程中,用户的原始输入往往不是“搜索引擎友好”的,比如包含大量的冗余、代词或模糊表达等。
查询重写主要思想就是使用一个专门的“重写器”(Rewriter)将原始查询转化为一个或多个更适合搜索引擎的检索词(Search Queries),然后使用这些优化后的词去数据库中捞取知识。
总结
总而言之,AI Agent 的记忆系统是其迈向高度智能的核心支柱,通过构建包含短期工作记忆与长期经验库的多层架构,结合基于大模型的事实提取、动态更新机制及知识图谱技术,并配合深度优化的 RAG 检索流程,Agent 能够实现精准的上下文维持与知识内化,从而在复杂场景中提供更具一致性、个性化且可靠的智能支持。
Reference
https://github.com/mem0ai/mem0
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents https://blog.langchain.com/how-we-built-agent-builders-memory-system/
https://arxiv.org/abs/2309.02427
https://arxiv.org/abs/2504.19413
https://www.youtube.com/watch?v=cHQyugatz6M
https://www.aneasystone.com/archives/2024/06/advanced-rag-notes.html