什么是 context engineering
所有LLM都受到有限上下文窗口的限制,这迫使模型在“一次可以看到什么”方面做出艰难的权衡。上下文工程就是将这个窗口视为一种稀缺资源,并围绕它设计一切(检索、记忆系统、工具集成、提示等),以确保模型只将其有限的注意力预算花在有价值的token。
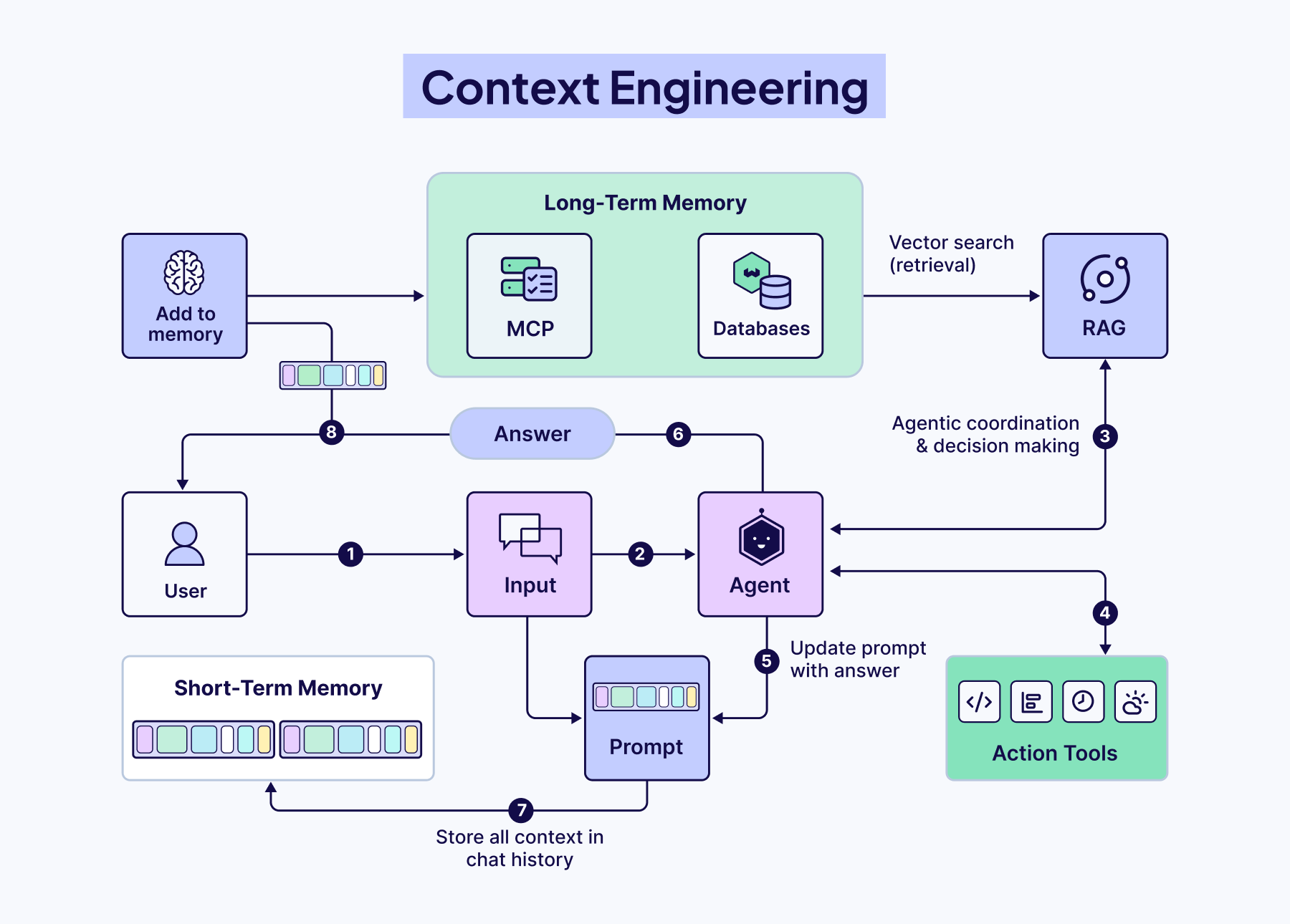
看起来和 Prompt Engineering 差不多,但是侧重点是不一样的。Prompt Engineering 侧重是提示词文本本身,Context Engineering 是模型看到的整个输入上下文系统,也就是prompt 只是 context 的一部分,真正决定模型输出质量的,往往不只是那段 instruction,而是整个上下文构造过程。
在早期使用逻辑逻辑模型(LLM)进行工程设计时,prompt是人工智能工程工作中最重要的组成部分,因为大多数日常聊天交互之外的应用场景都需要针对一次性分类或文本生成任务优化的prompt。顾名思义,prompt工程的主要重点在于如何编写有效的prompt,尤其是系统prompt。然而,随着我们朝着构建功能更强大的智能体方向发展,这些智能体需要在多轮推理和更长的时间跨度内运行,我们需要管理整个上下文状态(系统指令、工具、MCP、外部数据、消息历史记录等)的策略。
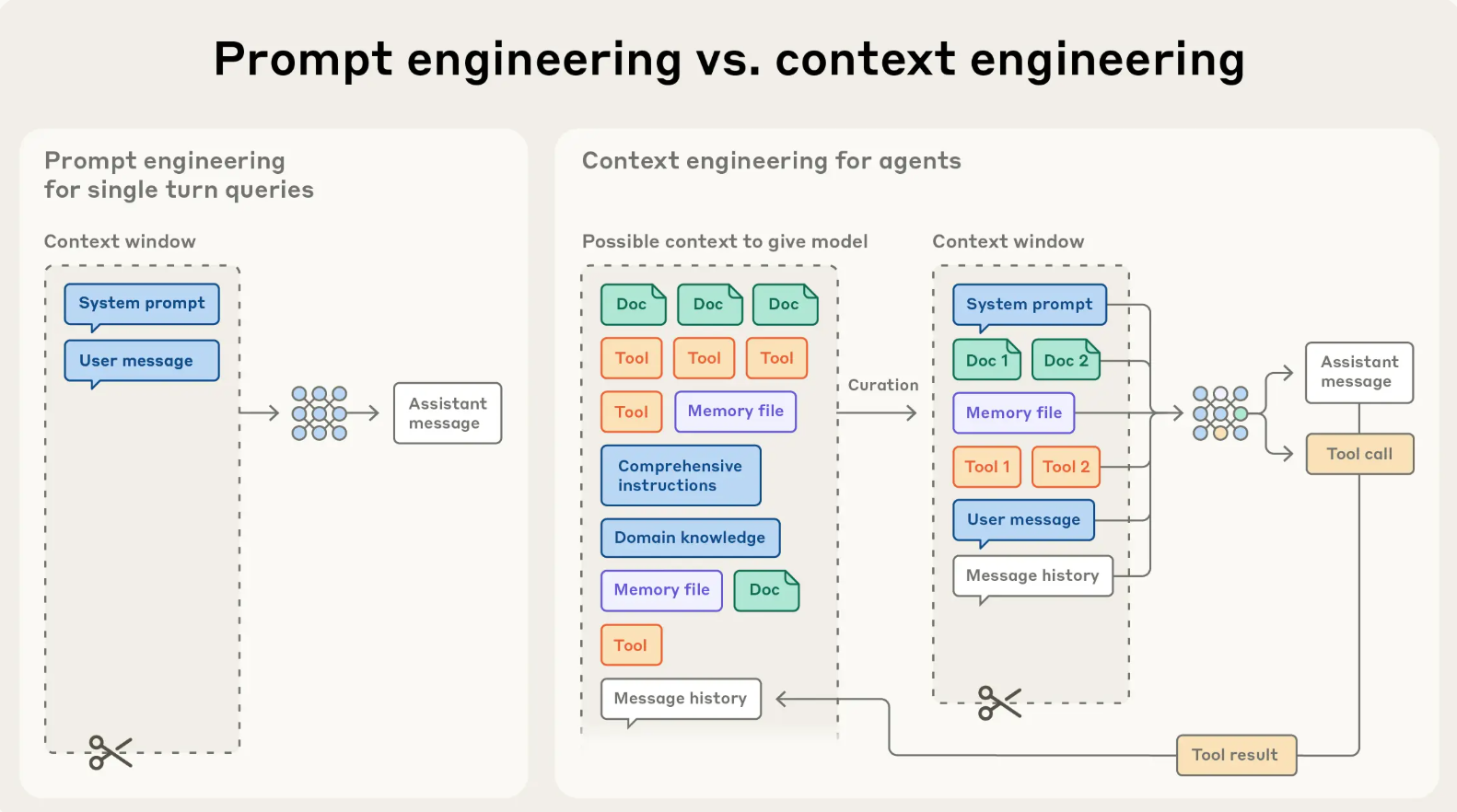
也就是在单轮请求场景中,模型的输入主要只有两块:System prompt、User message,只是做一个简单的输入然后回答。但是对于 agent 场景要复杂的多,因为 agent 不是纯聊天,它的执行流程很长,一般会有:
- 先看上下文
- 决定是否调用工具
- 拿到 Tool result
- 再把结果放回上下文
- 继续下一轮推理
所以 agent 是一个循环式工作流,不是一次性输入输出,那么在多轮工作流中,就需要从这些上下文中输出中“捞出”并“整理”出最正确的素材,而怎么筛选出最正确的内容就是Context Engineering 要做的事情。
为什么 Context Engineering 这么重要?
虽然现在的模型号称拥有百万级甚至千万级的上下文窗口(Context Window),但它们对信息的处理并不是“一视同仁”的。随着上下文变长,模型提取和处理信息的能力会像有机物腐烂一样逐渐变差,这种现象也叫 context rot。
典型的代理循环包含两个主要步骤:模型调用 ->工具执行,这个循环会持续到LLM决定结束,这些返回都会不断的拼接到模型的 context 里面。特别是工具调用后返回的结果会作为Observation拼接到模型里面,这部份内容经常会特别长,这样长的Observation不断地拼接到上下文message中,最后很有可能超过了模型最长能够接受的上下文长度(比如128K~1M)。
如果没有有效的 Context Engineering 来应对,Context Rot 会导致以下几个层面的严重后果:
- 准确性的“雪崩” (Accuracy Collapse):这是最直接的后果。随着上下文变长,模型提取关键事实的能力并非线性下降,而是可能在某个临界点突然跳水。模型可能记得某个“关键词”,但会完全搞错它在句子里的逻辑关系(例如:把“A 公司收购了 B”记成“B 公司收购了 A”)。
- 指令漂移与“性格”崩坏 (Instruction Drift):模型在 Prompt 开头设定的规则、约束和语气,会随着 Context Rot 的加剧而失效。你原本要求“严禁输出代码”,但当对话进行到 50 轮,上下文堆满了之前的讨论时,模型可能会因为抓取不到开头的强约束而开始输出代码。
- Agent 的“逻辑死循环” (Recursive Failure):Agent 忘记了自己已经尝试过某个 API 调用并失败了,由于上下文腐败,它会反复尝试同一个错误动作,直到耗尽预算。
- 调试的“不可预测性” (Non-Deterministic Flakiness):当上下文较短时,模型表现完美;当上下文变长,模型开始报错。这种 Bug 具有随机性,因为 Context Rot 受干扰项的位置、语义相似度等复杂因素影响,导致开发者很难通过简单的测试找到失效边界。
The Best Practice of Context Engineering
Context Engineering 对上下文的管理并不是简单的“复制粘贴”,而是一套精密的信息物流系统。其核心目标是:在不超出 Token 限制的前提下,将最高价值的信息精准送达模型最敏感的“注意力区域”。
Compression 压缩
其本质是:在尽量保留原始语义(Information Integrity)的前提下,通过算法减少传递给模型的 Token 数量。一般有几种做法:
- 级联摘要(Incremental Summarization):将历史对话分成块,让模型(通常用一个更小、更便宜的模型)将每一块总结成几句话;
- Token 级硬裁剪(Selective Context / Pruning): 语言中存在大量冗余(如“the”, “a”, “is” 以及重复的礼貌用语),利用小模型(如 GPT-2 或 Llama-8B)计算概率,删掉那些“即便删了,模型也能猜出来”的低信息量 Token;
- 精炼 Tool Output:Agent 调用工具(如搜索、运行代码)后会有大量噪音,比如原始:
{"status": 200, "data": {"user": {"id": 1, "name": "Alice", "bio": "Extremely long bio text..."}}},可以裁剪成:Found user: Alice (ID: 1); - 语义软压缩:使用专门的算法(如微软的 LLMLingua)重新编排 Prompt,将原本松散的句子重构成极度紧凑的、只有 AI 能读懂的“密文”。
Sub-agent architectures 子代理架构
子代理架构提供了另一种绕过上下文限制的方法。与其让一个代理尝试维护整个项目的状态,不如让专门的子代理在清晰的上下文窗口中处理特定的任务。主代理负责协调高层计划,而子代理则执行深入的技术工作或使用工具查找相关信息。每个子代理可能进行广泛的探索,使用数万个或更多令牌,但最终只返回其工作的精简摘要(通常包含 1000 到 2000 个令牌)。
如果你让一个 Agent 重构整个项目:
- 主代理(Manager): 维护项目全局目标。
- 子代理 A(Linter): 专门扫描语法错误,只向主代理报告错误列表。
- 子代理 B(Researcher): 专门读取文档,只返回 API 调用规范。
- 子代理 C(Coder): 接收 A 和 B 的精炼结论,在干净的窗口里编写代码。
这种方式确保了编写代码的 Agent 不会被上千行的“语法报错日志”或“冗长的库文档”干扰注意力。
Use the File System as Context 使用文件作为上下文的补充
因为在 Agent 的多轮交互当中即使现在 context 可以达到 200M 以上的大小,但是依然可能会不够,因为 Tool result 可能会非常的大,尤其是在 Agent 与网页或 PDF 等非结构化数据交互时,很容易超出上下文限制。并且 Agent 在多轮交互过程中,需要保存各种 reasoning 信息,成功或失败的调用 tool 的结果都需要保存,导致再长的context也不够用。
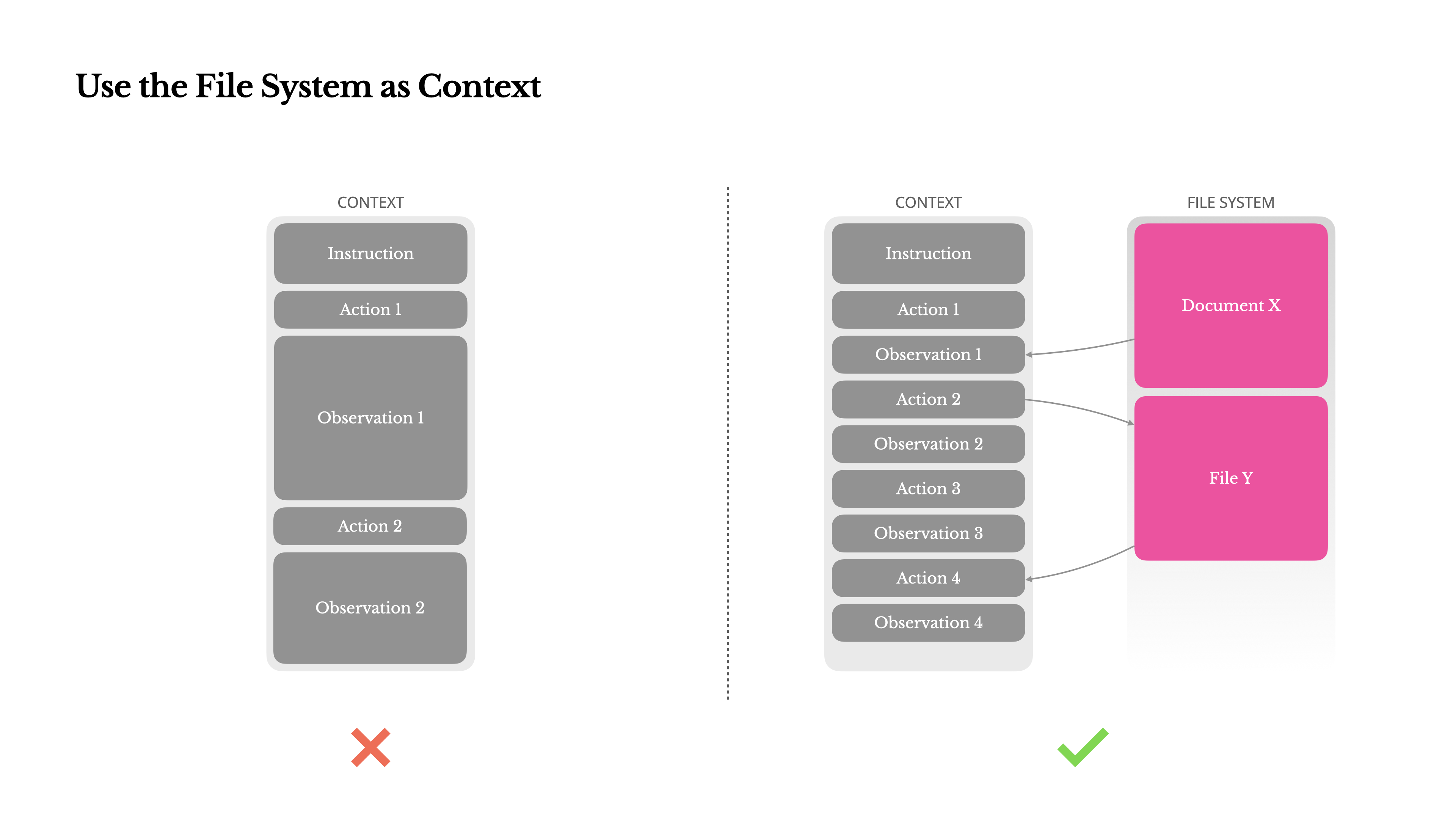
为了解决这个问题,许多 Agent 系统都采用了上下文截断或压缩策略。但过度压缩不可避免地会导致信息丢失。所以不管是 Claude 还是 Manus 都建议将文件作为外部的 context 来使用。可以利用文件系统来存储 Agent 的中间思考状态,解决长时程任务中的 Context Rot 问题。
比如可以让 Agent 在该文件中实时记录:
- 当前已完成的任务步骤。
- 已确认的事实(例如:“
auth.py的报错是因为版本不兼容”)。 - 接下来的行动计划。
然后提供一套能够精准操作文件系统的工具,Agent 后续可以通过head、tail、grep等命令渐进式地查看,或一次性读取整个文件。这种方式既减少了上下文占用,又保留了完整信息。
context中的实战tips
contex 拼接要按顺序
由于模型存在“中间信息丢失(Lost in the Middle)”的倾向,必须将最重要的信息放在 Prompt 的两端。顺序上通常是:
System / Global Instructions
User Profile / Long-term Memory
Relevant Conversation History
Current Task / Current Question
Retrieved Knowledge / Tool Results
Working Summary / Constraints / Output format核心逻辑是:
- 先告诉模型“你是谁、要遵守什么”
- 再告诉它“用户是谁、长期背景是什么”
- 再告诉它“前面聊到了哪里”
- 再明确“这一轮到底要做什么”
- 再给“这轮任务所需的工具调用结果或知识库相关检索”
- 最后提醒“回答时关注什么、输出成什么样”
如果中间数据太长,建议在底部 Query 之前增加一句:请基于上述 <context> 里的信息回答以下问题:。
tool result / retrieval docs 放在当前问题后面
因为模型最容易根据上下文有关联的链路来理解内容例如:
问题 -> 证据 -> 回答而不是下面这样:
证据A -> 旧history -> 证据B -> memory -> question后者很容易让模型搞不清哪些证据是给当前任务用的。
结构化标记 Structured Tagging
使用明确的 XML 标签 或 Markdown 标记 是目前公认最有效的隔离方式,因为它能显著降低模型对“数据”和“指令”的混淆。比如这样:
<system_instructions>
你是一个代码审计专家。请遵循 <security_policy> 进行分析。
</system_instructions>
<security_policy>
1. 严禁泄露 API Key。
2. 优先检查 SQL 注入漏洞。
</security_policy>
<context_data>
[此处存放 RAG 检索到的代码片段或文档]
</context_data>
<tool_outputs>
[此处存放上一步执行 grep 或 linter 的原始输出]
</tool_outputs>
<user_query>
基于以上背景,分析 src/auth.py 的安全性。
</user_query>信息精炼:防止“Context 污染”
在拼接之前,必须对各部分内容进行预处理,提升信号密度:
- 工具结果去噪: 如果 API 返回了 2000 行 JSON,只抽取核心的
data字段,丢弃headers、metadata等噪音。 - 历史消息“关键帧”化: 保留最近几轮完整对话,更早的对话只保留
Summary。 - 去重(Deduplication): RAG 检索时经常会召回重复或高度相似的片段,拼接前需通过语义对比或简单的哈希值过滤。
Token 预算动态分配
在拼接逻辑中,建议为各部分设置权重(Weights),防止某一部分过长导致“爆仓”或挤掉核心指令。
| 模块 | 建议权重/策略 | 溢出处理 |
|---|---|---|
| System Prompt | 100% 保留(最高优先级) | 绝不截断 |
| Current Query | 100% 保留(最高优先级) | 绝不截断 |
| RAG Context | 40% 预算 | 按相似度评分从低到高丢弃 |
| History | 30% 预算 | 采用滑动窗口或摘要化 |
| Tool Results | 20% 预算 | 只保留最新结果,旧结果仅保留结论 |
选择性注入
并非所有上下文都需要同时存在于 context window 中。透过 LLM 驱动的路由逻辑,系统可以根据当前查询的性质和业务领域,动态决定注入哪些知识片段。例如,当使用者询问财务问题时,系统注入财务相关文件与对话历史;当话题转向技术问题时,动态替换为技术文件。
Reference
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
https://docs.langchain.com/oss/python/langchain/context-engineering#the-agent-loop
https://weaviate.io/blog/context-engineering
https://zhuanlan.zhihu.com/p/2012088406826562496