我们在上一篇文章中讲解了 Go HTTP 标准库的实现原理,这一次我找到了一个号称比net/http快十倍的Go框架 fasthttp,这次我们再来看看它有哪些优秀的设计值得我们去挖掘。
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/574
一个典型的 HTTP 服务应该如图所示:
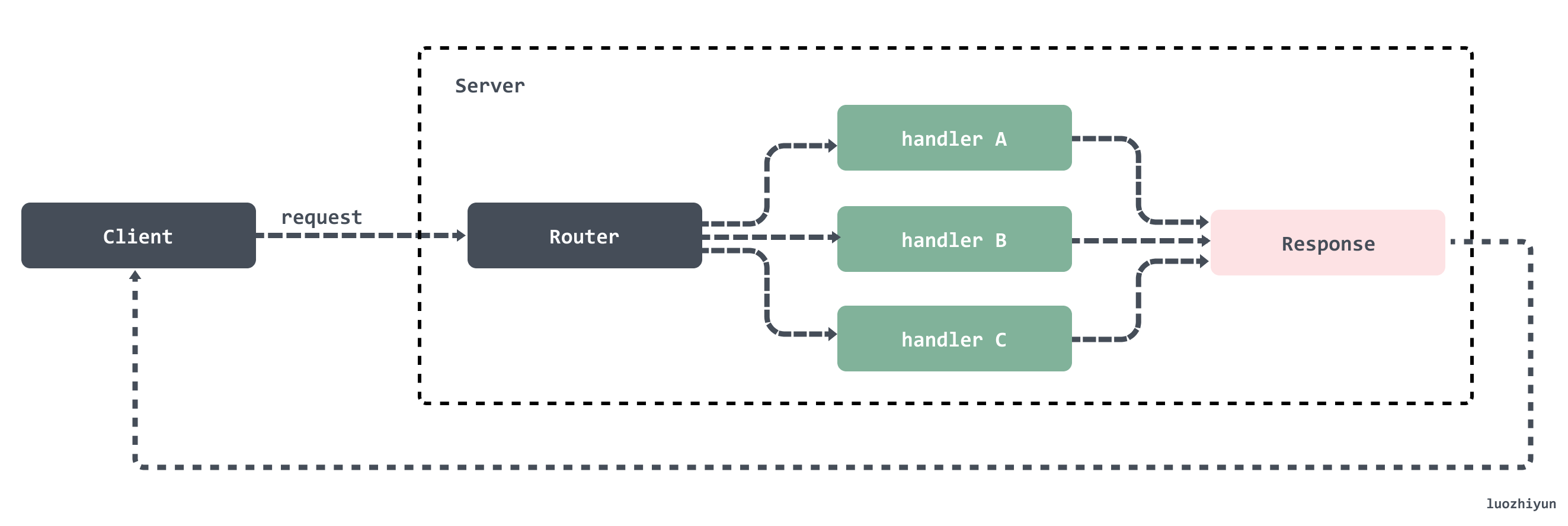
基于HTTP构建的服务标准模型包括两个端,客户端(Client)和服务端(Server)。HTTP 请求从客户端发出,服务端接受到请求后进行处理然后将响应返回给客户端。所以http服务器的工作就在于如何接受来自客户端的请求,并向客户端返回响应。
这篇我们来讲讲 Server 端的实现。
实现原理
net/http 与 fasthttp 实现对比
我们在讲 net/http 的时候讲过,它的处理流程大概是这样的:
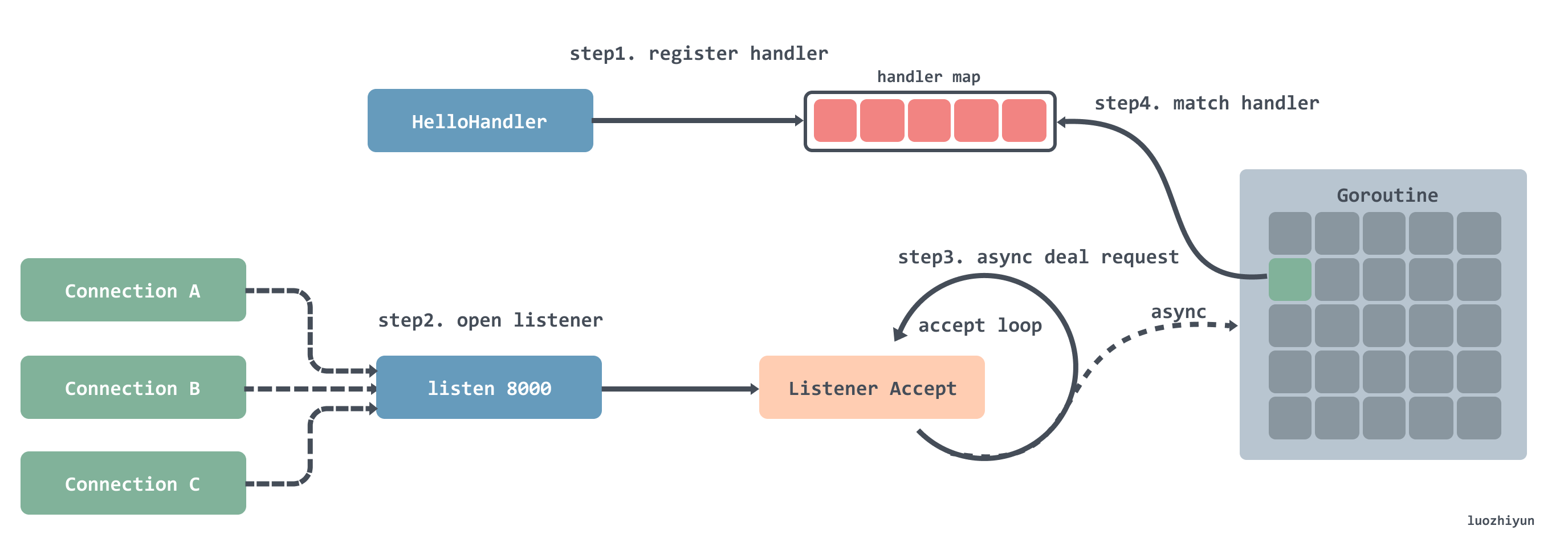
- 注册处理器到一个 hash 表中,可以通过键值路由匹配;
- 注册完之后就是开启循环监听,每监听到一个连接就会创建一个 Goroutine;
- 在创建好的 Goroutine 里面会循环的等待接收请求数据,然后根据请求的地址去处理器路由表中匹配对应的处理器,然后将请求交给处理器处理;
这样做在连接数比较少的时候是没什么问题的,但是在连接数非常多的时候,每个连接都会创建一个 Goroutine 就会给系统带来一定的压力。这也就造成了 net/http在处理高并发时的瓶颈。
下面我们再看看 fasthttp 是如何做的:
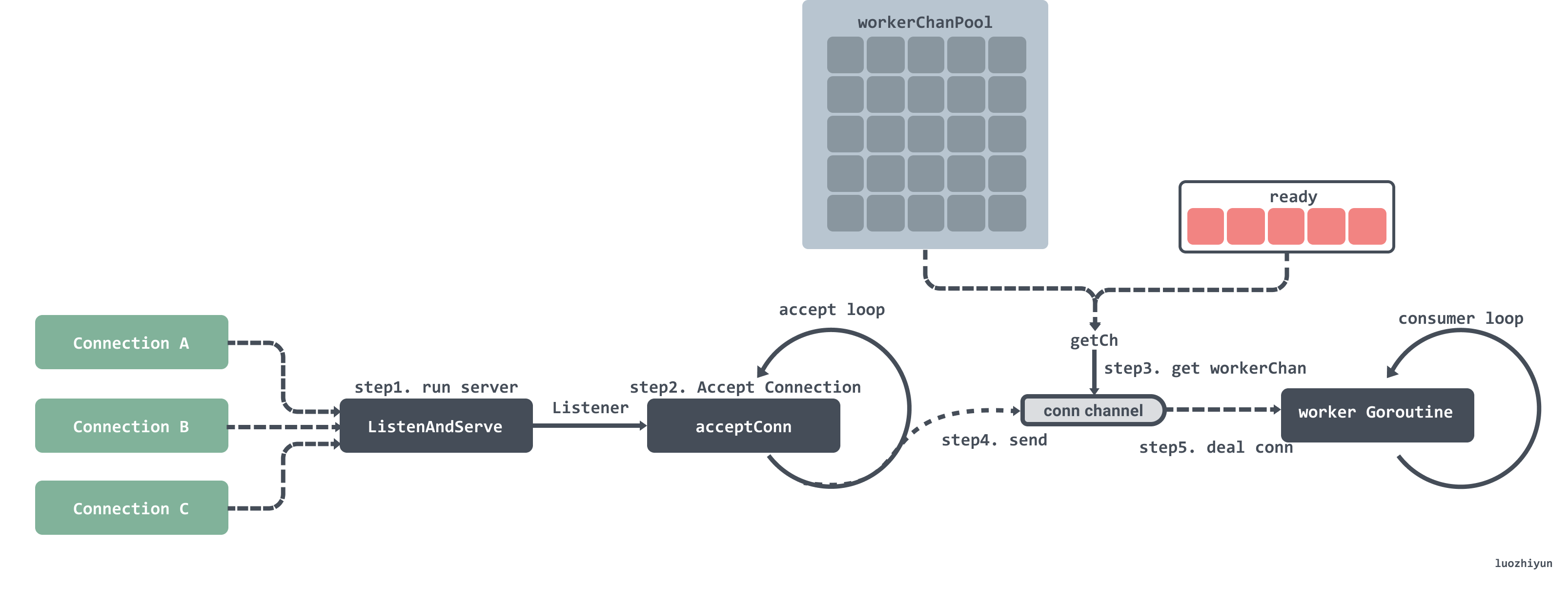
- 启动监听;
- 循环监听端口获取连接;
- 获取到连接之后首先会去 ready 队列里获取 workerChan,获取不到就会去对象池获取;
- 将监听的连接传入到 workerChan 的 channel 中;
- workerChan 有一个 Goroutine 一直循环获取 channel 中的数据,获取到之后就会对请求进行处理然后返回。
上面有提到 workerChan 其实就是一个连接处理对象,这个对象里面有一个 channel 用来传递连接;每个 workerChan 在后台都会有一个 Goroutine 循环获取 channel 中的连接,然后进行处理。如果没有设置最大同时连接处理数的话,默认是 256 * 1024个。这样可以在并发很高的时候还可以同时保证对外提供服务。
除此之外,在实现上还通过 sync.Pool 来大量的复用对象,减少内存分配,如:
workerChanPool 、ctxPool 、readerPool、writerPool 等等多大30多个 sync.Pool 。
除了复用对象,fasthttp 还会切片,通过 s = s[:0]和 s = append(s[:0], b…)来减少切片的再次创建。
fasthttp 由于需要和 string 打交道的地方很多,所以还从很多地方尽量的避免[]byte到string转换时带来的内存分配和拷贝带来的消耗 。
小结
综上我们大致介绍了一下 fasthttp 提升性能的点:
- 控制异步 Goroutine 的同时处理数量,最大默认是
256 * 1024个; - 使用 sync.Pool 来大量的复用对象和切片,减少内存分配;
- 尽量的避免
[]byte到string转换时带来的内存分配和拷贝带来的消耗 ;
源码解析
我们以一个简单的例子作为开始:
func main() {
if err := fasthttp.ListenAndServe(":8088", requestHandler); err != nil {
log.Fatalf("Error in ListenAndServe: %s", err)
}
}
func requestHandler(ctx *fasthttp.RequestCtx) {
fmt.Fprintf(ctx, "Hello, world!\n\n")
}我们调用 ListenAndServe 函数会启动服务监听,等待任务进行处理。ListenAndServe 函数实际上会调用到 Server 的 ListenAndServe 方法,这里我们看一下 Server 结构体的字段:

上图简单的列举了一些 Server 结构体的常见字段,包括:请求处理器、服务名、请求读取超时时间、请求写入超时时间、每个连接最大请求数等。除此之外还有很多其他参数,可以在各个维度上控制服务端的一些参数。
Server 的 ListenAndServe 方法会获取 TCP 监听,然后调用 Serve 方法执行服务端的逻辑处理。
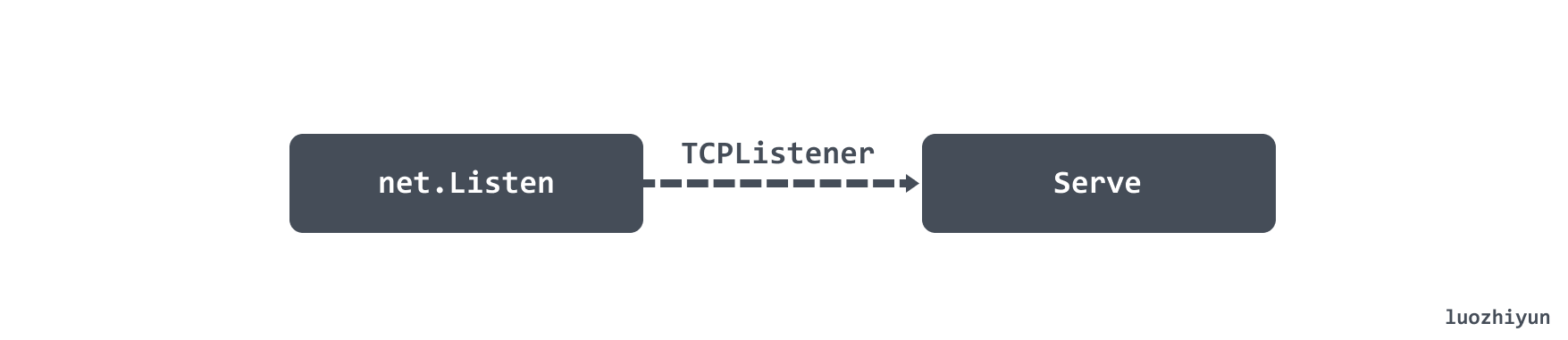
Server 方法主要做了以下几件事:
- 初始化并启动 worker Pool;
- 接收请求 Connection;
- 将 Connection 交给 worker Pool 处理;
func (s *Server) Serve(ln net.Listener) error {
...
s.mu.Unlock()
// 初始化 worker Pool
wp := &workerPool{
WorkerFunc: s.serveConn,
MaxWorkersCount: maxWorkersCount,
LogAllErrors: s.LogAllErrors,
Logger: s.logger(),
connState: s.setState,
}
// 启动 worker Pool
wp.Start()
// 循环处理 connection
for {
// 获取 connection
if c, err = acceptConn(s, ln, &lastPerIPErrorTime); err != nil {
wp.Stop()
if err == io.EOF {
return nil
}
return err
}
s.setState(c, StateNew)
atomic.AddInt32(&s.open, 1)
// 处理 connection
if !wp.Serve(c) {
// 进入if 说明已到并发极限
...
}
c = nil
}
}worker Pool
worker Pool 是用来处理所有请求 Connection 的,这里稍微看看 workerPool 结构体的字段:

- WorkerFunc: 用来匹配请求对应的 handler 并执行;
- MaxWorkersCount:最大同时处理的请求数;
- ready:空闲的 workerChan;
- workerChanPool:workerChan 的对象池,是一个 sync.Pool 类型的;
- workersCount:目前正在处理的请求数;
下面我们看一下 workerPool 的 Start 方法:
func (wp *workerPool) Start() {
if wp.stopCh != nil {
panic("BUG: workerPool already started")
}
wp.stopCh = make(chan struct{})
stopCh := wp.stopCh
// 设置 worker Pool 的创建函数
wp.workerChanPool.New = func() interface{} {
return &workerChan{
ch: make(chan net.Conn, workerChanCap),
}
}
go func() {
var scratch []*workerChan
for {
// 没隔一段时间会清理空闲超时的 workerChan
wp.clean(&scratch)
select {
case <-stopCh:
return
default:
// 默认是 10 s
time.Sleep(wp.getMaxIdleWorkerDuration())
}
}
}()
}Start 方法里面主要是:
- 设置 workerChanPool 的创建函数;
- 启动一个 Goroutine 定时清理 workerPool 中的 ready 中保存的空闲 workerChan,默认每 10s 启动一次。
获取连接
func acceptConn(s *Server, ln net.Listener, lastPerIPErrorTime *time.Time) (net.Conn, error) {
for {
c, err := ln.Accept()
if err != nil {
if c != nil {
panic("BUG: net.Listener returned non-nil conn and non-nil error")
}
...
return nil, io.EOF
}
if c == nil {
panic("BUG: net.Listener returned (nil, nil)")
}
// 校验每个ip对应的连接数
if s.MaxConnsPerIP > 0 {
pic := wrapPerIPConn(s, c)
if pic == nil {
if time.Since(*lastPerIPErrorTime) > time.Minute {
s.logger().Printf("The number of connections from %s exceeds MaxConnsPerIP=%d",
getConnIP4(c), s.MaxConnsPerIP)
*lastPerIPErrorTime = time.Now()
}
continue
}
c = pic
}
return c, nil
}
}获取连接其实没什么好说的,和 net/http 库一样调用的 TCPListener 的 accept 方法获取 TCP Connection。
处理连接
处理连接部分首先会获取 workerChan ,workerChan 结构体里面包含了两个字段:lastUseTime、channel:
type workerChan struct {
lastUseTime time.Time
ch chan net.Conn
}-
lastUseTime 标识最后一次被使用的时间;
-
ch 是用来传递 Connection 用的。
获取到 Connection 之后会传入到 workerChan 的 channel 中,每个对应的 workerChan 都有一个异步 Goroutine 在处理 channel 里面的 Connection。
获取 workerChan
func (wp *workerPool) Serve(c net.Conn) bool {
// 获取 workerChan
ch := wp.getCh()
if ch == nil {
return false
}
// 将 Connection 放入到 channel 中
ch.ch <- c
return true
}Serve 方法主要是通过 getCh 方法获取 workerChan ,然后将当前的 Connection 传入到 workerChan 的 channel 中。
func (wp *workerPool) getCh() *workerChan {
var ch *workerChan
createWorker := false
wp.lock.Lock()
// 尝试从空闲队列里获取 workerChan
ready := wp.ready
n := len(ready) - 1
if n < 0 {
if wp.workersCount < wp.MaxWorkersCount {
createWorker = true
wp.workersCount++
}
} else {
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
// 获取不到则从对象池中获取
if ch == nil {
if !createWorker {
return nil
}
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
// 为新的 workerChan 开启 goroutine
go func() {
// 处理 channel 中的数据
wp.workerFunc(ch)
// 处理完之后重新放回到对象池中
wp.workerChanPool.Put(vch)
}()
}
return ch
}getCh 方法首先会去 ready 空闲队列中获取 workerChan,如果获取不到则从对象池中获取,从对象池中获取的新的 workerChan 会启动 Goroutine 用来处理 channel 中的数据。
处理连接
func (wp *workerPool) workerFunc(ch *workerChan) {
var c net.Conn
var err error
// 消费 channel 中的数据
for c = range ch.ch {
if c == nil {
break
}
// 读取请求数据并响应返回
if err = wp.WorkerFunc(c); err != nil && err != errHijacked {
...
}
c = nil
// 将当前的 workerChan 放入的 ready 队列中
if !wp.release(ch) {
break
}
}
wp.lock.Lock()
wp.workersCount--
wp.lock.Unlock()
}这里会遍历获取 workerChan 的 channel 中的 Connection 然后执行 WorkerFunc 函数处理请求,处理完毕之后会将当前的 workerChan 重新放入到 ready 队列中复用。
需要注意的是,这个循环会在获取 Connection 为 nil 的时候跳出循环,这个 nil 是 workerPool 在异步调用 clean 方法检查该 workerChan 空闲时间超长了就会往 channel 中传入一个 nil。
这里设置的 WorkerFunc 函数是 Server 的 serveConn 方法,里面会获取到请求的参数,然后根据请求调用到对应的 handler 进行请求处理,然后返回 response,由于 serveConn 方法比较长这里就不解析了,感兴趣的同学自己看看。
总结
我们这里分析了 fasthttp 的实现原理,通过原理我们可以知道 fasthttp 和 net/http 在实现上面有什么差异,从而大致得出 fasthttp 快的原因,然后再从它的实现细节知道它在实现上是如何做到减少内存分配从而提高性能的。
