转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/721
以前也没深入研究链接这个过程做了什么,趁着最近在整理计算机系统相关知识的功夫,整理了一下链接过程做了什么,感兴趣的不妨看看。
概述
一般来讲将 C 语言的源代码文件变成一个可执行文件需要经过编译生成目标文件,然后再将多个目标文件链接生成最后的可执行文件。
编写源代码->编译生成目标文件->链接生成可执行文件因为我们项目中往往代码都分散在不同的文件中,所以需要将多个目标文件合成一个执行文件,至于怎么合成,这就是链接要做的事情。就像下面这张图所示,链接器将两个目标文件合成一个可执行文件:
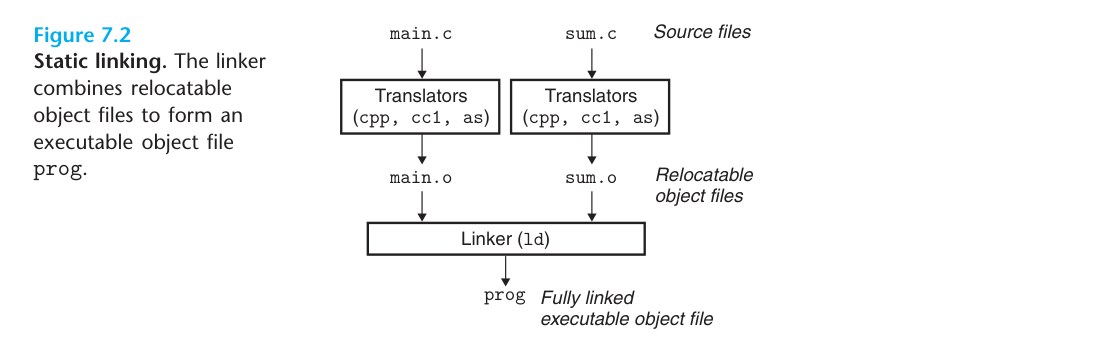
在 Linux 平台上目标文件和可执行文件内容和结构都很相似,所以一般目标文件跟可执行文件都采用 ELF(Executable Linkable Format)进行存储。
ELF 是一种对象文件的格式,用于定义不同类型的对象文件(Object files)中都放了什么东西、以及都以什么样的格式去放这些东西。我们把 ELF 文件归为以下几类:
- 可重定位的对象文件(Relocatable file),由汇编器汇编生成的 .o 文件,可被用来链接成可执行文件或共享目标文件;
- 可执行的对象文件(Executable file),它代表的就是 ELF 可执行文件,一般没有扩展名;
- 可被共享的对象文件(Shared object file),动态库文件,也即 .so 文件;
所以下面我们先从文件结构看起,ELF 文件中包含了哪些东西,再来将链接器怎么合并目标文件。
ELF 文件结构
/usr/include/elf.h
typedef uint16_t Elf64_Half;
typedef uint32_t Elf64_Word;
typedef uint64_t Elf64_Addr;
typedef uint64_t Elf64_Off;
#define EI_NIDENT (16)
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
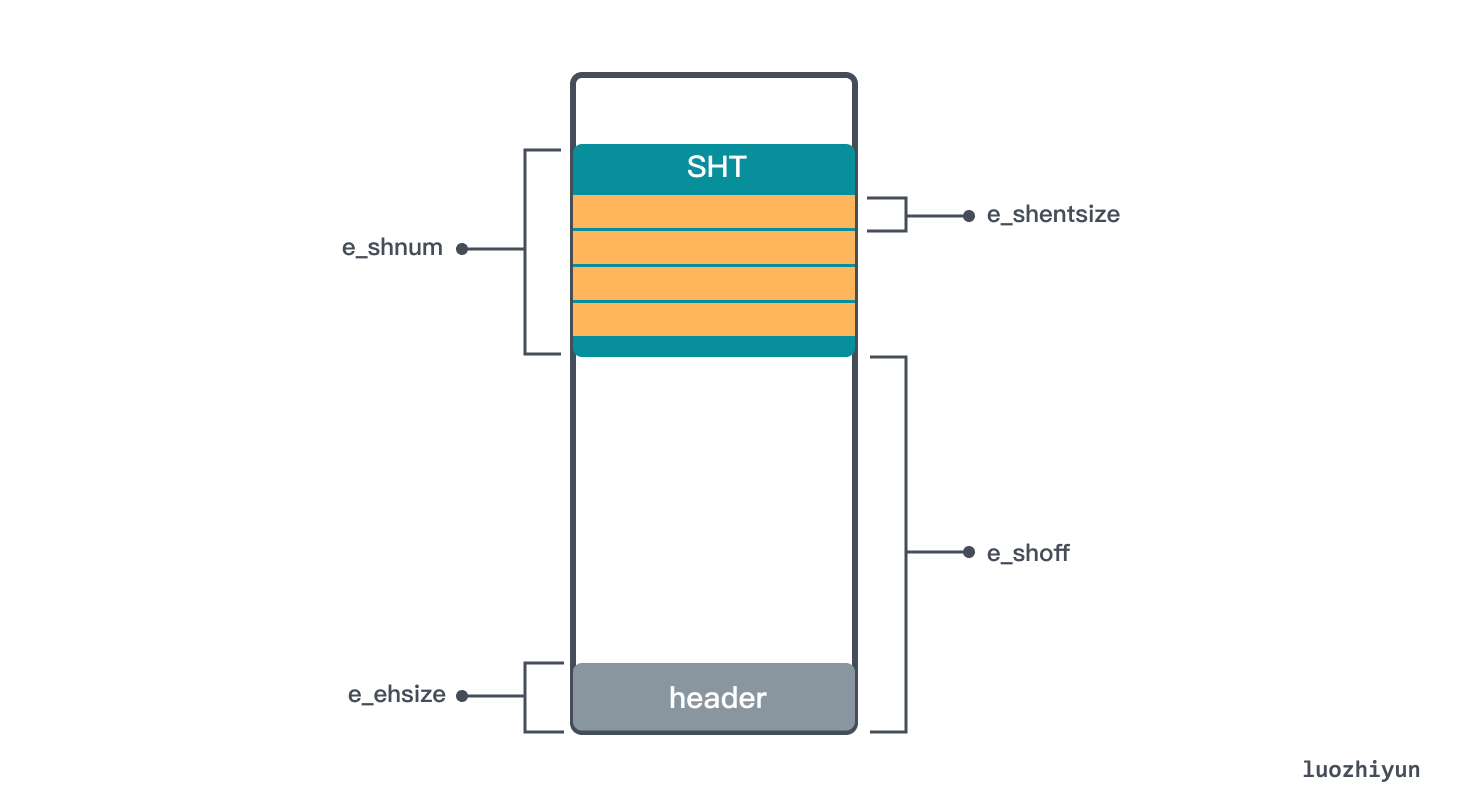
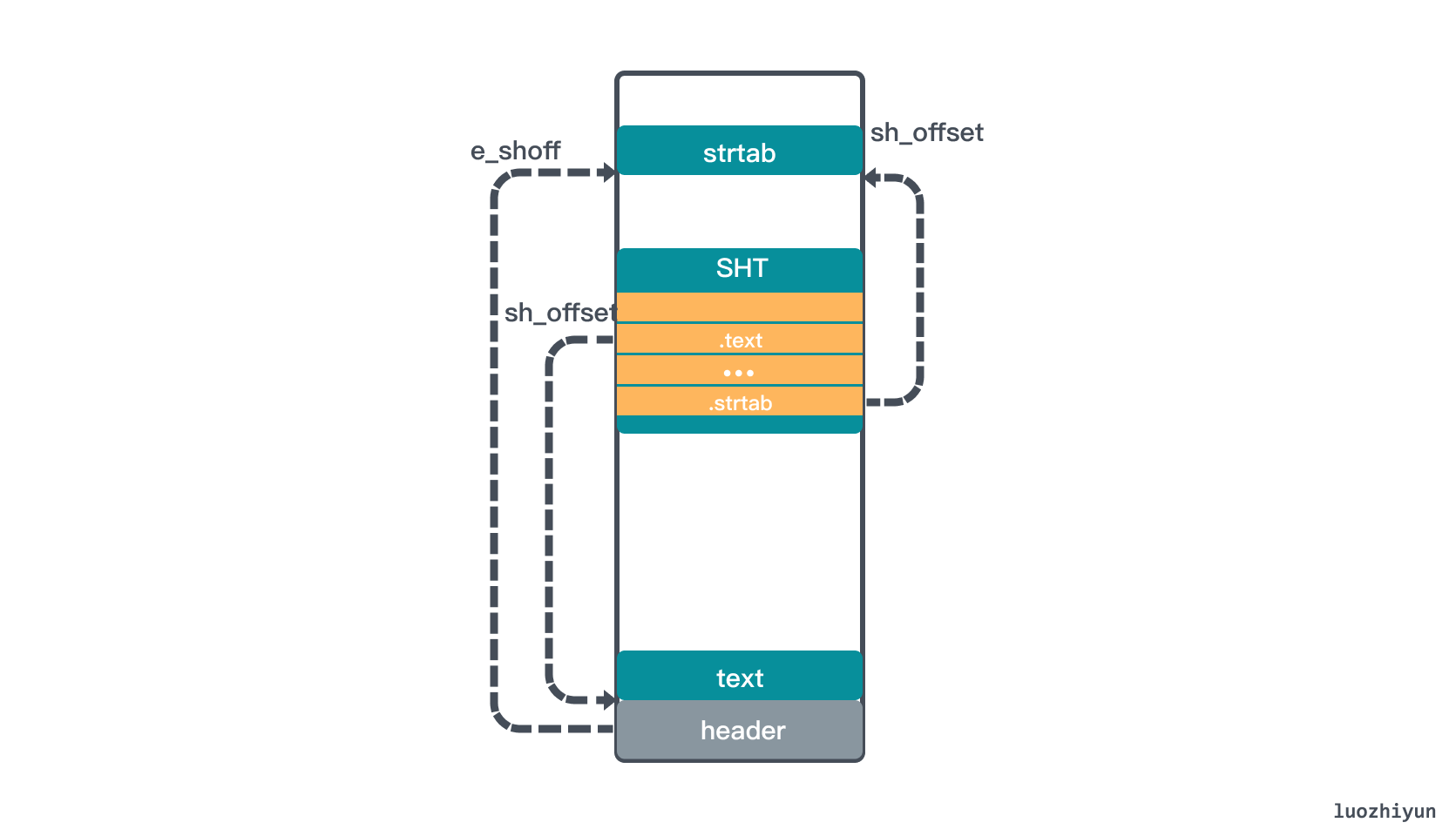
} Elf64_Ehdr; 我们首先看看如何用 header 信息定位到 Section Header Table(SHT)。SHT 里面存放了一组 Section,常见的有.text,.bss,.data、.bss 等。那么要定位到 SHT 就需要知道起始位置、Table 里面 Section 的大小,Table 的 Section 数量。
上面这个 header 数据结构中 e_shoff 就是SHT 在 ELF 起始地址的偏移位置,通过它可以算出 SHT 起始位置;e_shentsize 就是 SHT 中 Section 的大小;e_shnum 是 SHT 中 entry 数量。
header 数据结构中还有一个值得注意的是 e_shstrndx 字段,它是字符串表的索引,可以帮助定位到字符串表。
下面我会通过手动解析 16 进制 ELF 文件结构的方式来带大家更加清晰的了解 ELF 文件结构,感兴趣的朋友可以跟着一起来验证一下。
我们先举一个例子来说明:
testelf.c
unsigned long long data1 = 1234455;
unsigned long long data2 = 66778899;
void func1() {};
void func2() {};将上面的文件用gcc -c testelf.c -o testelf.o命令编译出来,然后通过 hexdump testelf.o 查看编译出来的 testelf.o 内容,按照 Elf64_Ehdr 的结构格式,我们可以解读 ELF 的 Header信息:

按照上图的标记可以找到 e_shoff 表示 SHT 偏移是 0x0140(320 bytes), e_ehsize 表示 ELF 头大小是 0x0040(64 bytes), e_shentsize 表示 SHT 中 Section 的大小是 0x0040(64 bytes),e_shnum 表示 SHT Section 数量 0x000b(11 bytes),e_shstrndx 字符串表偏移 0x0008(8 bytes)。
Section 表
所以根据 e_shoff 我们可以找到对应个 SHT 的偏移位置,由 e_shentsize 可以知道每个 Section 大小是 64 bytes,共11项,那么可以找到对应的 SHT 对应的数据。其中 SHT 里面的 Section 是通过 Elf64_Shdr 这个结构来进行描述:
/usr/include/elf.h
typedef uint32_t Elf64_Word;
typedef uint64_t Elf64_Addr;
typedef uint64_t Elf64_Off;
typedef uint64_t Elf64_Xword;
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;那么我们继续可以根据上面这个结构题和hexdump testelf.o输出的字符信息进行解析:
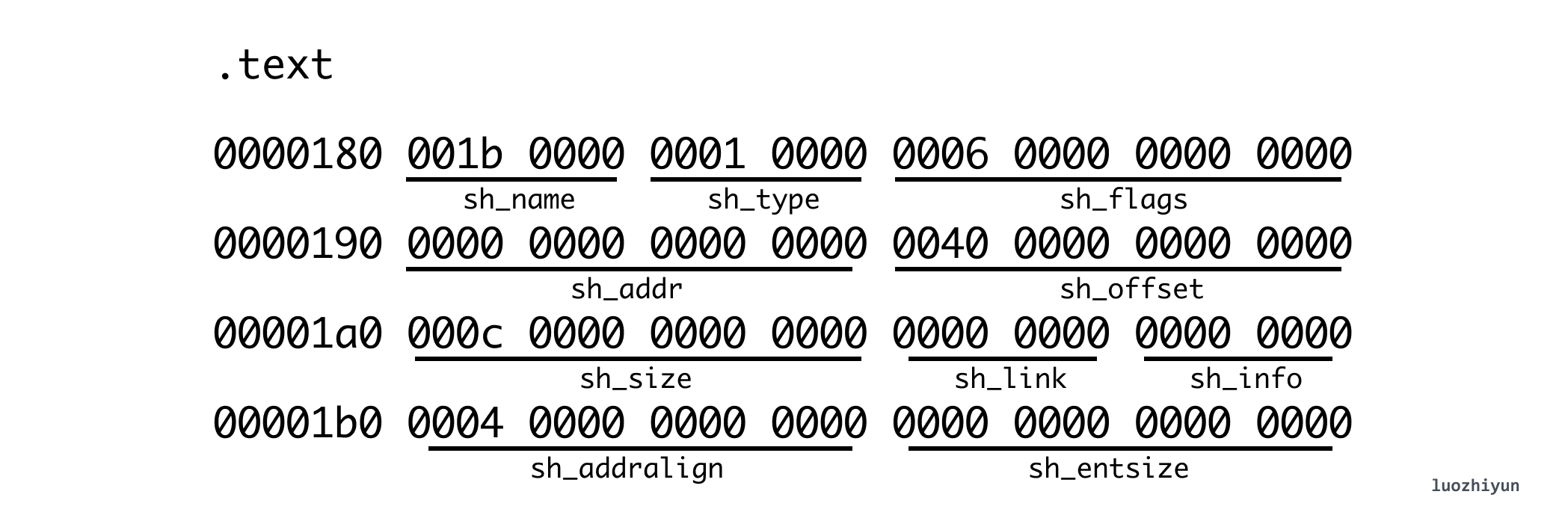
我这里只解析了 text Section,从里面我们可以看到 sh_offset 为 0x0040 (64 bytes),也就是它直接指向了 ELF header 后面的内存块。sh_size 为 0x00c (12 bytes)表示 func1 和 func2 两个空函数占据了 12 bytes。需要注意的是 Section[0] 这一项只做占位用,全是0。
也就是说,我们可以通过上面的 Section 描述信息找到对应的 Section 具体的数据信息。再比如下面的 strtab Section:
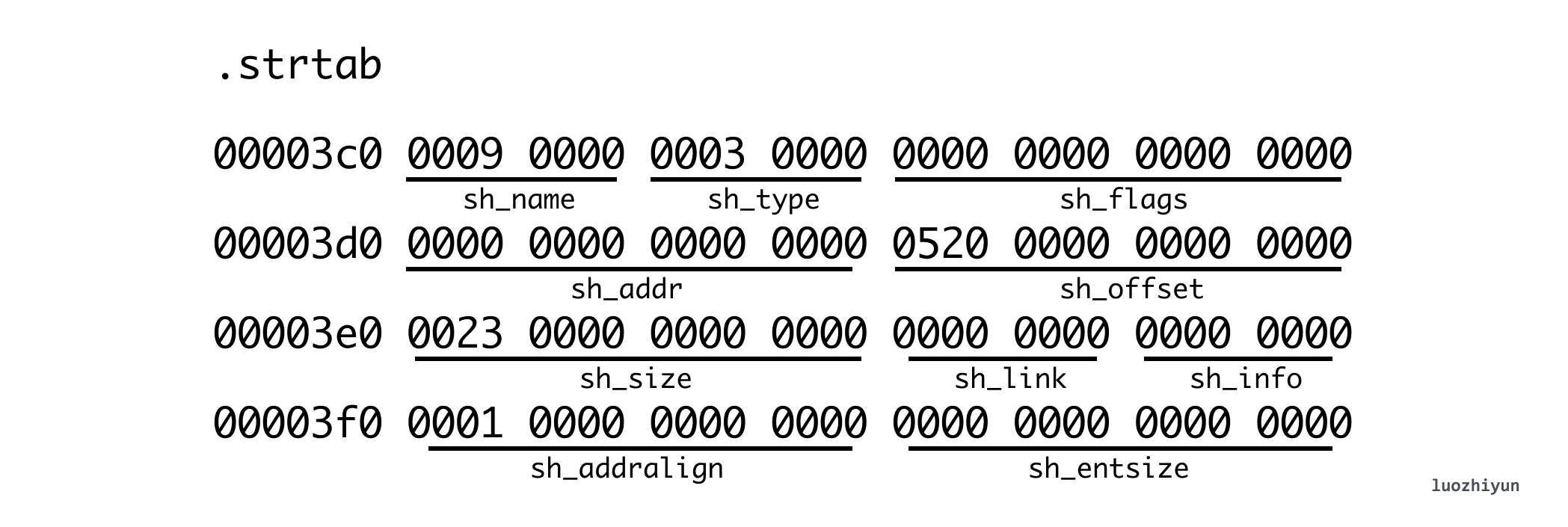
通过上面的 sh_offset 可以知道它在 ELF 文件中偏移位置是 0x520,大小是 0x0023(35 bytes)。那么可以通过这个信息找到对应的字符串表的数据(右边是16进制 ascii 对应的字符),我们可以通过 hexdump -C右边可以输出字符串 ascii:
00000520 00 74 65 73 74 65 6c 66 2e 63 00 64 61 74 61 31 |.testelf.c.data1|
00000530 00 64 61 74 61 32 00 66 75 6e 63 31 00 66 75 6e |.data2.func1.fun|
00000540 63 32 00 00 00 00 00 00 20 00 00 00 00 00 00 00 |c2...... .......|值得一说的是 Elf64_Shdr.sh_name 存放的是 .shstrtab 指向的偏移量,大家可以自己动手找一下。通过上面分析,大致可以看出 ELF 文件是这样的结构:
符号表
在我们上面所讲的 SHT 中有一个 Section 是 .symtab,它就是符号表。在链接器的上下文中,有三种不同的符号:
- 全局符号,它可以被其他模块引用,也就是普通的 C 函数和全局变量;
- 外部符号,在其他模块中定义并被引用的符号。比如在 C 中被 extern 修饰的函数或变量;
- 局部符号,只能被本模块引用的符号,也就是带 static 属性的 C 函数和全局变量,它能在本模块被引用,但是不能被其他模块引用。
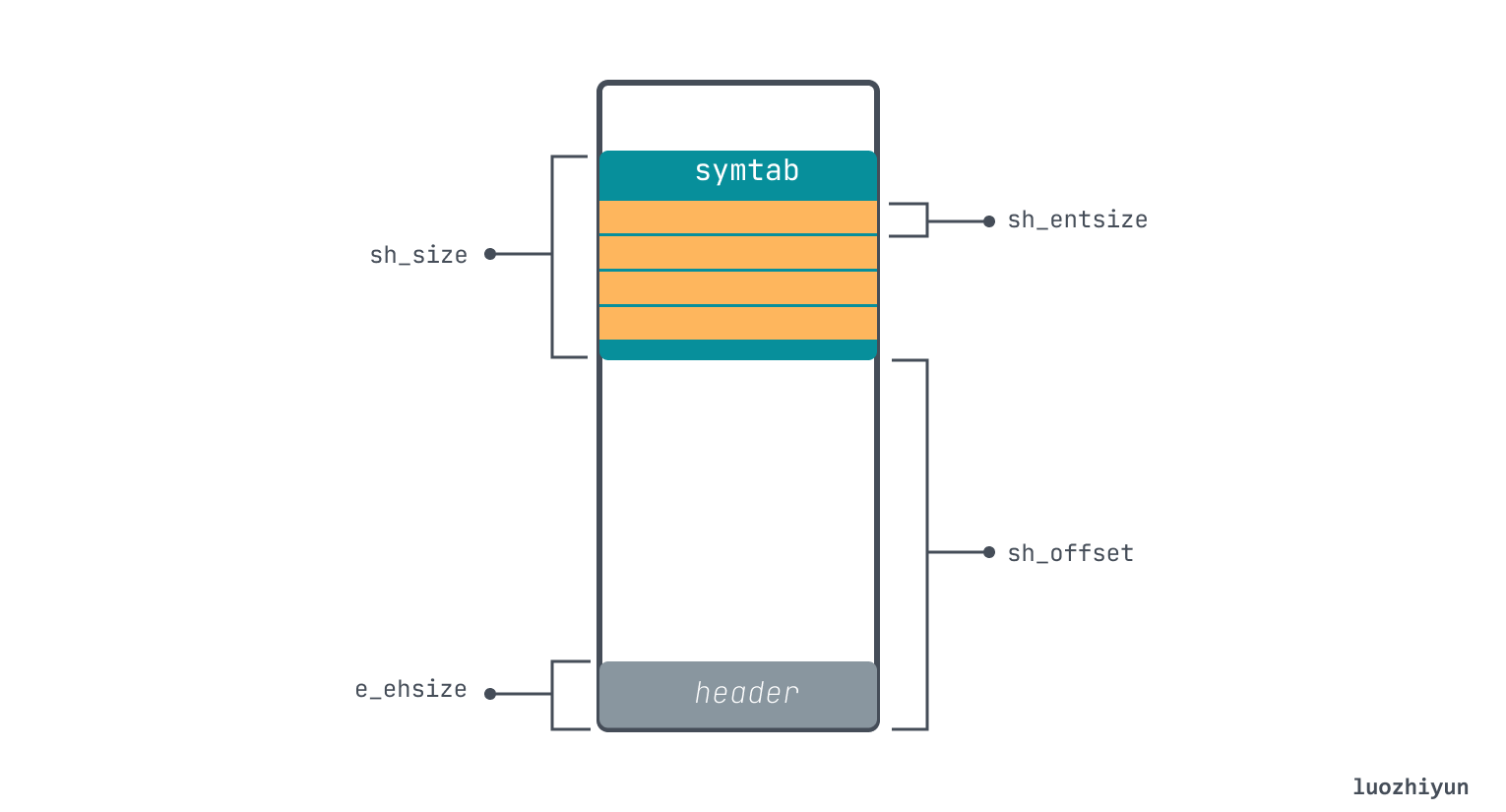
在上面的例子中,我们可以在 SHT 中找到符号表 .symtab:
.symtab Section 指向另外一片内存就是符号表,它里面由多个表项组成,对应到文件里 symtab 是这个样:
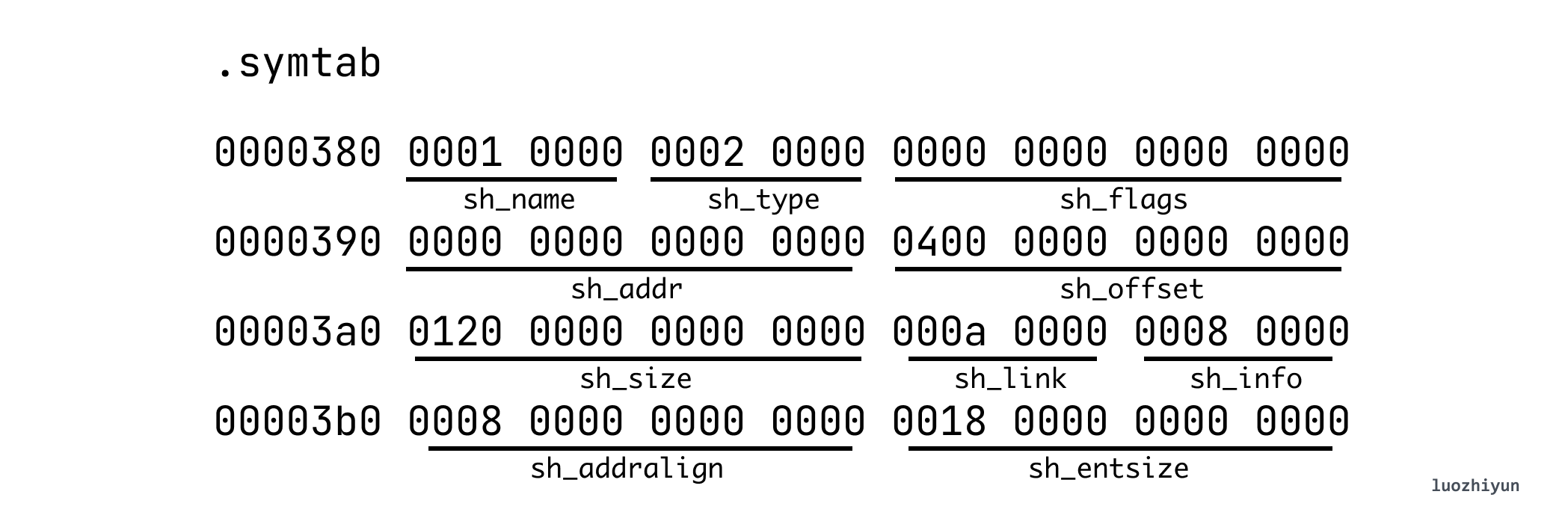
根据我们上面看 Section 的方法可以知道,它的偏移是 0x400,总大小是 0x120(288 bytes), .symtab 每一项都有固定大小是 sh_entsize 0x18(24 bytes),那么可以知道它共有 12 项。symtab 表项的数据结构如下:
/usr/include/elf.h
typedef uint32_t Elf64_Word;
typedef uint16_t Elf64_Section;
typedef uint64_t Elf64_Addr;
typedef uint64_t Elf64_Xword;
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;根据 symtab 的偏移位置,可以找到对应表项,我们从里面取出我们定义的表项:

其中 data1.st_name 0x0b(11 bytes) 表示的是 .strtab 表里面的从偏移量 0x0b 开始到 00 (’\0’)结束,所取得的 16 进制编码就是 64 61 74 61 31,对应的 ascii 就是 d a t a 1。
st_shndx 表示 SHT索引位置,data1.st_shndx 是 0x02 表示的是数据在 SHT[2] 中,也就是在 .data Section 中;
st_value 是每个符号所代表的地址,在目标文件中,符号地址都是相对于该符号所在Section的相对地址,在可执行文件中,这个值表示的是虚拟地址,目前我们解析的是目标文件,所以 data1.st_value 是 0x00,对应在 .data Section 偏移是 0 ;
st_size 是该符号占据的大小,data1.st_size 是 0x08 (8 bytes),那么根据这个信息可以取出 data 中的值为 0x0012d617,转成10进制就是我们填入的 1234455。所以你也可以找出 data2 是 0x03faf713 转成10进制就是 66778899。

那么根据 symtab 的表项的描述,我们就可以确定下面位置:
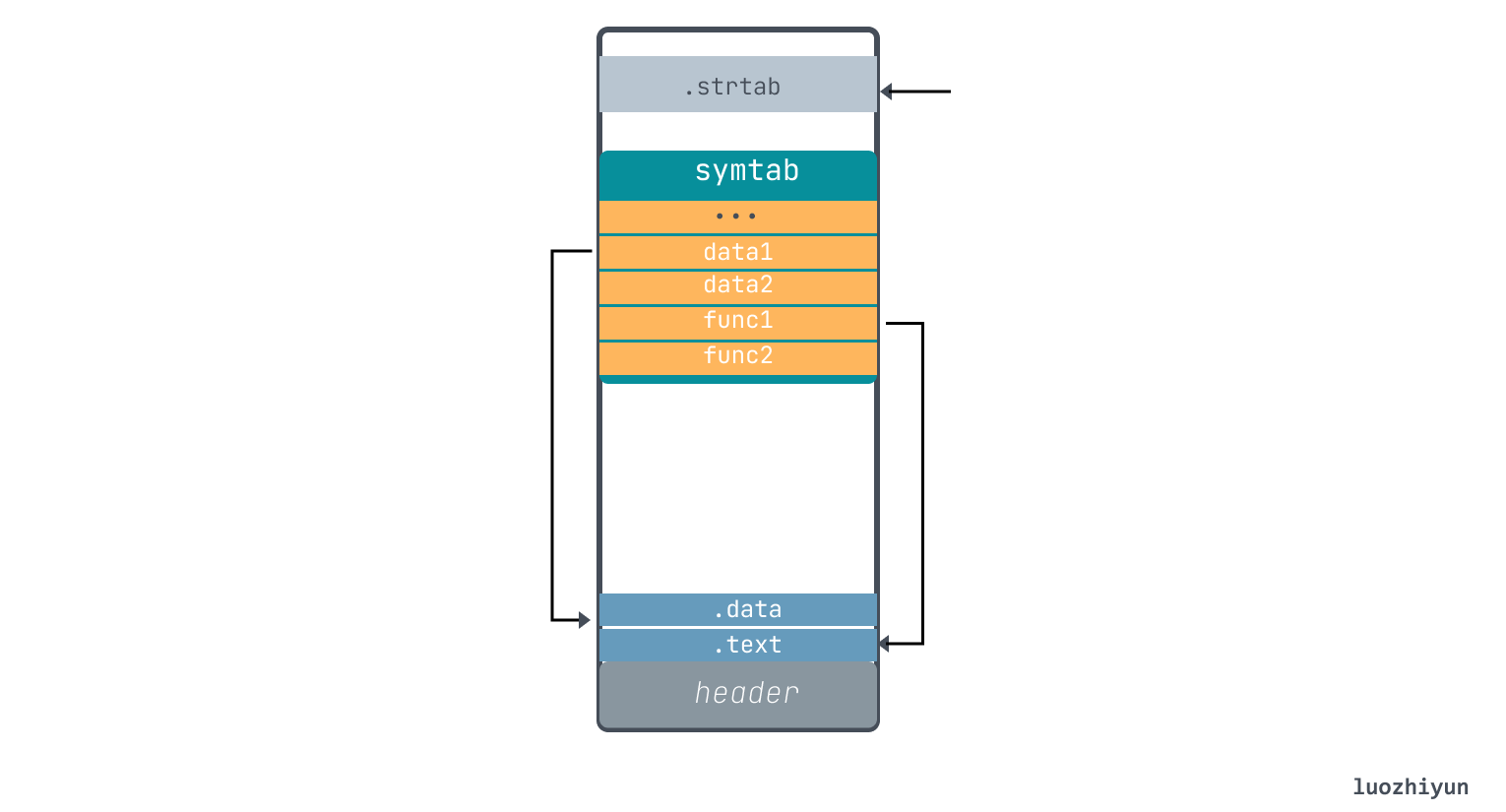
下面我们再来看看 Elf64_Sym.st_info 这个字段,这个字段低四位是符号的类型(Type),高四位是符号在源文件中的关联(Bind)。
Type 主要表述这个符号被定义成变量还是函数等,主要我们看下面这几种:
/usr/include/elf.h
#define STT_NOTYPE 0 /* Symbol type is unspecified */
#define STT_OBJECT 1 /* Symbol is a data object */
#define STT_FUNC 2 /* Symbol is a code object */在上面的例子中, data1 和 data2 Type 都是 0x1,表示是一个 Object 对象。func1 和 func2 都是 0x2 ,表示是一个 func 函数。
Bind 主要描述这个符号的类型,定义了 9 种,我们看前两种:
/usr/include/elf.h
#define STB_LOCAL 0 /* Local symbol */
#define STB_GLOBAL 1 /* Global symbol */data1 、data2、func1 、func2 都是全局符号,所以都是 0x1 为 STB_GLOBAL。
下面我们可以再看看 static 修饰的变量和函数,例如下面我们再声明如下:
static unsigned long long data3 = 0xdddd;
static void func3(){} 除了上面根据 16进制找符号表以外,我们还可以通过 readelf -s来快速查看:
$ readelf -s testelf.o
Symbol table '.symtab' contains 15 entries:
Num: Value Size Type Bind Vis Ndx Name
...
5: 0000000000000010 8 OBJECT LOCAL DEFAULT 2 data3
6: 0000000000000016 11 FUNC LOCAL DEFAULT 1 func3
...通过上面我们可以看出,静态变量 data3 和 func3 与全局变量相比依然分别在 .data 和 .text,由于它们还是变量和函数,所以 Type 没有变,但是由于被 static 修饰,所以 Bind 类型变成了 STB_LOCAL。这是静态符号和全局符号主要的区别。
对于外部符号来说,一般用 extern 修饰,但是 extern 在修饰的时候是可以省略的,所以要分函数和变量进行讨论。对函数来说,不管有没有被 extern 修饰,只要没有定义,那么都会产生相同的符号。但是需要注意的是,如果在当前文件种没有被引用的话,编译器会优化这个无用的声明。如果有被引用才会出现在符号表中:
extern void fun4();
int fun5();对于上面这两个函数,并没有被定义,所以不会在 .text Section 中占用空间,它们的表项是这样的:
$ readelf -s testelf.o
Symbol table '.symtab' contains 18 entries:
Num: Value Size Type Bind Vis Ndx Name
...
16: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND fun4
17: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND fun5st_shndx 都为 UND,也就是 SHT[0] ,表示无定义。同时它们的 Type 也是 NOTYPE 表示无类型的。但是由于没有被 static 修饰,所以 Bind 依然是 GLOBAL 表示全局符号。
对于变量来说,情况要复杂一点,因为如果 extern 省略,不一定是 extern 类型的,可能只是定义了一个全局变量。我们下面定义这三个变量:
extern int data4;
int data5;
int data6 = 0; 下面我们看一下对应的符号表:
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
...
9: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM data5
10: 0000000000000000 4 OBJECT GLOBAL DEFAULT 4 data6
...
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND data4对于 data4 来说被显示的用 extern 修饰,所以与上面被 extern 修饰的函数表现一致。data4 和 data5 一样虽然可以被表示为一个 extern 变量,但是 data5 是缺省赋值的初始化,它的地址位于 SHT 的 .comment Section 中,属于一种弱符号,在符号解析中会被进一步处理。 .comment 是 ELF 中临时的 Section,并不在执行文件中存在,被存放在 .comment 中的变量会在链接中决定它的去向,如果链接找到其定义,那么地址在执行文件中 .data Segment 中,否则初始化为 0 ,并将地址指向 .bss Segment 中。
对于 data6 来说是被显示的初始化为 0,ELF 会将所有被初始化为 0 的变量集中放到 .bss Section中,没必要在 .data 中多次定义。.bss 作用就是用来节省空间,它专门用来存放未初始化的全局和静态变量。
从上面我们也可以看到 .comment 和 .bss 区别很细微,现在的 GCC 版本根据以下规则来将可重定位目标文件中的符号分配到 .comment 和 .bss 中:
- .comment:未初始化的全局变量;
- .bss:未初始化的静态变量,以及初始化为0的全局或静态变量;
重定位表
当汇编器生成一个 ELF 目标文件的时候,会遇到无法处理的引用,可能一个定义在其他 ELF 文件中的函数或变量被当前 ELF 文件代码引用。所以对于这些未知的目标引用,它会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。
代码的重定位条目存放在 .rel.text 中,已初始化数据的重定位条目放在 .rel.data 中。下面时重定位条目的格式:
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
Elf64_Sxword r_addend; /* Addend */
} Elf64_Rela;r_offset 记录了引用的位置,时相对于当前 section 的 byte 偏移;r_info 是个已复合结构,低 4 byte 位重定位的类型,它提示链接器应当如何处理这一重定位项,高 4 byte 为被引用的符号在符号表 .symtab 中的序号;r_addend 是重定位计算中的偏置值,用来矫正最终计算出来的位置。
我们下面举个例子:
test_rel.c
extern void undef_func();
extern int undef_array[2];
void main()
{
undef_func(); // reference<1>
undef_array[0] = 1; // reference<2>
undef_array[1] = 2; // reference<3>
}通过查表我们可以知道:

然后我们执行反汇编 objdump -d test_rel.o 可以看到 text section对应的 16 进制和汇编可以根据 r_offset 偏移找到对应代码:
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: b8 00 00 00 00 mov $0x0,%eax
d: e8 00 00 00 00 callq 12 <main+0x12>
12: c7 05 00 00 00 00 01 movl $0x1,0x0(%rip) # 1c <main+0x1c>
19: 00 00 00
1c: c7 05 00 00 00 00 02 movl $0x2,0x0(%rip) # 26 <main+0x26>
23: 00 00 00
26: 90 nop
27: 5d pop %rbp
28: c3 retq 对于符号索引我们也可以在符号中找到对应的符号:
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
...
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND undef_func
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND undef_array在 Elf64_Rela 中还有一个 type 字段没有讲,因为它涉及到具体计算引用对象位置的策略,不同的策略有不同的计算方式。这些策略其实都在完成一件事,那就是当程序访问到引用对象的时候,会根据引用对象当前的位置计算出被引用者的位置,这些策略在这里就不细聊了。
静态链接
因为我们在实际开发过程中代码都是分文件存放的,不同文件之间会有一个依赖关系,所以静态链接要做的事情就是将多个输入的目标文件加工后合并成一个可执行文件。
我们假设程序里只有这两个文件:
a.c
extern void undef_func();
extern int undef_array[2];
void main()
{
undef_func(); // reference<1>
undef_array[0] = 1; // reference<2>
undef_array[1] = 2; // reference<3>
}
-------------------------------
b.c
void undef_func(){
};
int undef_array[2] = {1,2};然后通过使用 gcc a.o b.o -o ab来将目标文件加工后合并成一个可执行文件,当然我们也可以使用 gcc a.c b.c -o ab直接将源文件生成一个可执行文件。
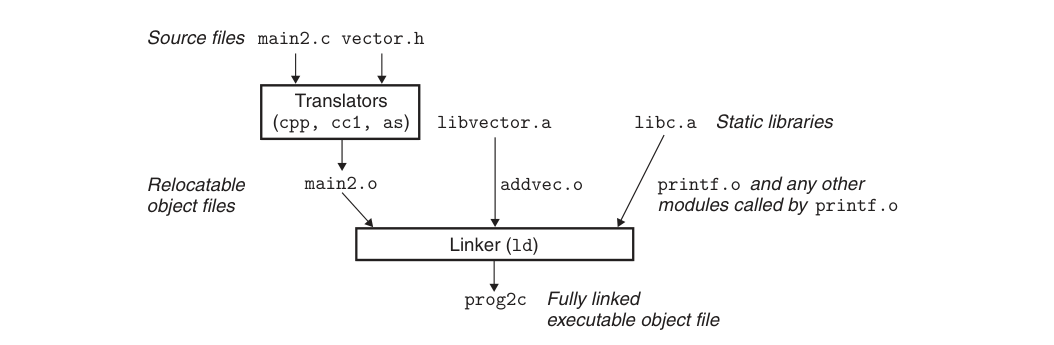
整个链接过程分为以下几步:
- 符号解析,当所有的 ELF 文件被读入内存以后,不同文件可能声明了相同的符号,这一步主要解决冲突;
- section 合并,不同文件会存在相同的 section,那么需要将相同的 section 放入同一 section 中;
- 重定位,当汇编器生成一个 ELF 目标文件的时候,会遇到无法处理的引用,可能一个定义在其他 ELF 文件中的函数或变量被当前 ELF 文件代码引用,那么需要重新设置引用位置;
符号解析
这一步主要解决不同文件之间的符号冲突,所以需要用到符号表,符号表中我们也主要看全局符号,因为只有全局符号才能在不同文件中被引用。在上面讲符号表的时候也提到过,在 .symtab 中 st_shndx 表示该符号在 SHT 中的索引,有数字的代表是有定义的,除此之外有几类特殊的伪节(pseudosection)存在:ABS、COM、UND。
ABS 表示不该被重定位的符号,这里我们可以不用管;COM 表示还未分配位置的未初始化的数据目标,由于它在可执行文件中并不存在,所以表示的是一种临时定义符号;UND 表示未定义的符号,也就是在本目标模块中引用,但是却在其他文件中定义的符号。
除了上面说的这几种外,还有一种被 __attribbute__((weak)) 修饰的符号,也是一种弱引用。
所以总结就是:已定义符号是一种强符号,COM、UND、__attribbute__((weak)) 中几种都是弱符号。那么根据 CSAPP 中的规则就是:
- 不允许有多个同名的强符号;
- 如果有一个强符号和多个若符号同名,那么选择强符号;
- 如果有多个弱符号同名,那么从这些若符号中任意选择一个。
Section 合并
我们的编译器将我们的代码文本转为多个以 .o 结尾的目标文件后链接器会将多个目标文件合并成一个可执行文件(Executable Object File)。通过上面的分析我们知道每个目标文件中都会包含 section,所以需要将相同类型的 section 进行合并。
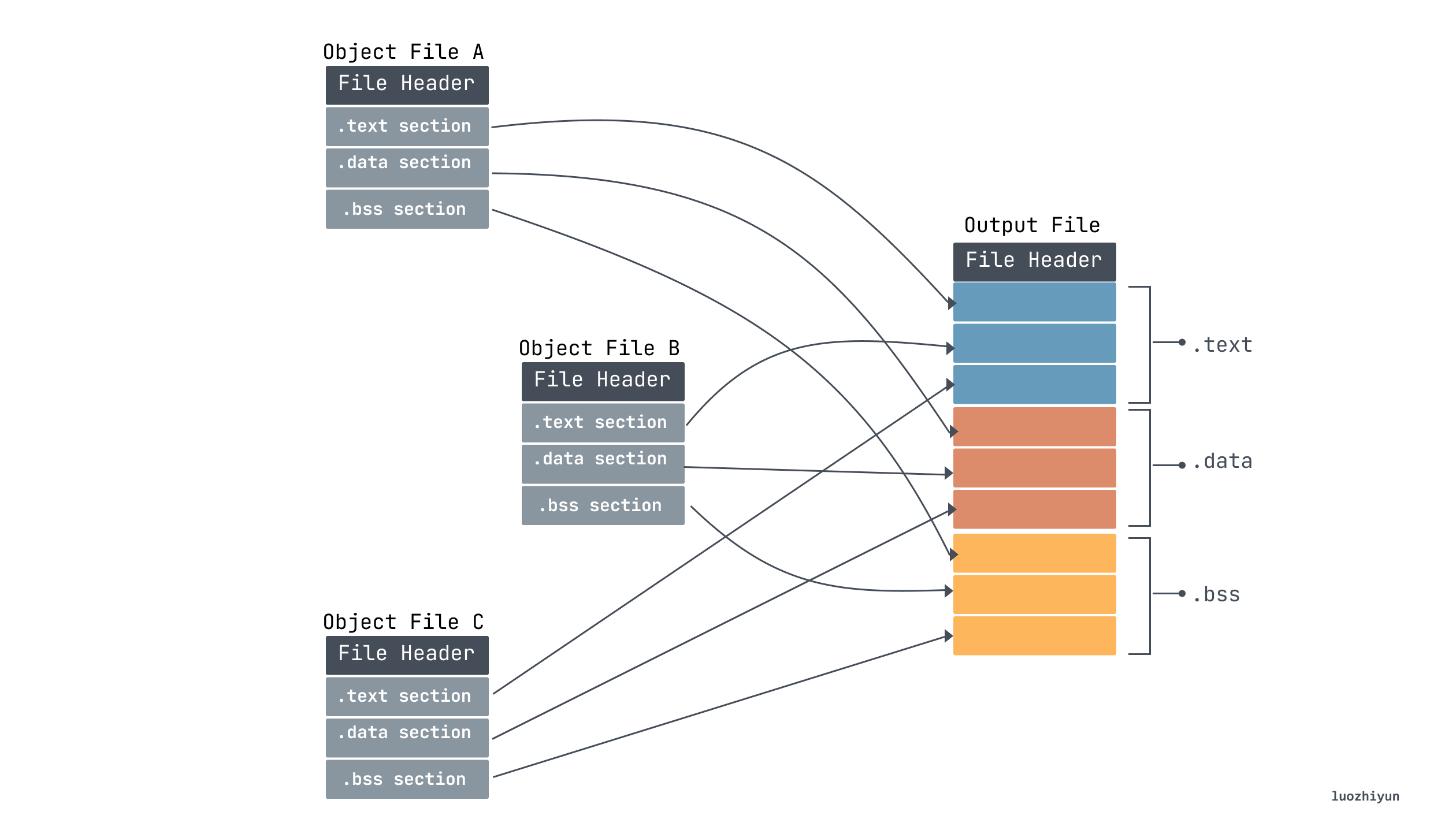
同时合并完成之后,还会将多个 section 合并成 segment,ELF Header 中的 Program Header Table 用来描述 segment 信息。因为 Program Header Table在链接过程中用不到所以在目标文件中一般不存在,Segment 只有加载的时候才会用到,加载器(Loader)根据可执行文件中的Segment信息加载运行这个程序,所以在生成可执行文件的时候会存在。
我们将上面的 a 和 b 两个文件链接之后,可以使用 readelf -l查看对应的 segment 信息:
Elf file type is DYN (Shared object file)
Entry point 0x1040
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002d8 0x00000000000002d8 R 0x8
INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x00000000000005c8 0x00000000000005c8 R 0x1000
LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000
0x00000000000001e5 0x00000000000001e5 R E 0x1000
LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000
0x0000000000000158 0x0000000000000158 R 0x1000
LOAD 0x0000000000002df0 0x0000000000003df0 0x0000000000003df0
0x0000000000000228 0x0000000000000230 RW 0x1000
DYNAMIC 0x0000000000002e00 0x0000000000003e00 0x0000000000003e00
0x00000000000001c0 0x00000000000001c0 RW 0x8
NOTE 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000020 0x0000000000000020 R 0x8
NOTE 0x0000000000000358 0x0000000000000358 0x0000000000000358
0x0000000000000044 0x0000000000000044 R 0x4
GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000020 0x0000000000000020 R 0x8
GNU_EH_FRAME 0x0000000000002004 0x0000000000002004 0x0000000000002004
0x0000000000000044 0x0000000000000044 R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002df0 0x0000000000003df0 0x0000000000003df0
0x0000000000000210 0x0000000000000210 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn
03 .init .plt .plt.got .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id .note.ABI-tag
09 .note.gnu.property
10 .eh_frame_hdr
11
12 .init_array .fini_array .dynamic .got 对于上面的 segment 信息可以清晰的看到和 section 的映射关系。segment 的定义在 /usr/include/elf.h 的 Elf64_Phdr 结构体中可以找到。segment 表中类型为 LOAD 表明它是一个可装载的段,段的内容会被从文件中拷贝到内存中。
重定位
在完成符号解析和 section 和并之后还需要对符号与引用进行重定位,重定位过程中会根据它们的位置计算出一个虚拟地址,根据这个地址程序在运行的时候才可以找到对应的实现。
我们先来看看 main 函数引用位置objdump -d ab
0000000000001129 <main>:
1129: f3 0f 1e fa endbr64
112d: 55 push %rbp
112e: 48 89 e5 mov %rsp,%rbp
1131: b8 00 00 00 00 mov $0x0,%eax
1136: e8 17 00 00 00 callq 1152 <undef_func> # reference<1>
113b: c7 05 cb 2e 00 00 01 movl $0x1,0x2ecb(%rip) # 4010 <undef_array> reference<2>
1142: 00 00 00
1145: c7 05 c5 2e 00 00 02 movl $0x2,0x2ec5(%rip) # 4014 <undef_array+0x4> reference<3>
114c: 00 00 00
114f: 90 nop
1150: 5d pop %rbp
1151: c3 retq 下面我们看看重定位是怎么计算的,首先我们先看看 a.o 的重定位项:
Relocation section '.rela.text' at offset 0x268 contains 3 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000e 000b00000004 R_X86_64_PLT32 0000000000000000 undef_func - 4
000000000014 000c00000002 R_X86_64_PC32 0000000000000000 undef_array - 8
00000000001e 000c00000002 R_X86_64_PC32 0000000000000000 undef_array - 4Type 项表示了寻址的方式,我们通过查询 Relocation Types 知道有下面这些,Calculation 表示计算方式:
| Name | Value | Field | Calculation |
|---|---|---|---|
R_X86_64_NONE |
0 | none | none |
R_X86_64_64 |
1 | word64 | S + A |
R_X86_64_PC32 |
2 | word32 | S + A - P |
R_X86_64_GOT32 |
3 | word32 | G + A |
R_X86_64_PLT32 |
4 | word32 | L + A - P |
R_X86_64_COPY |
5 | none | none |
R_X86_64_GLOB_DAT |
6 | word64 | S |
R_X86_64_JUMP_SLOT |
7 | word64 | S |
R_X86_64_RELATIVE |
8 | word64 | B + A |
R_X86_64_GOTPCREL |
9 | word32 | G + GOT + A - P |
R_X86_64_32 |
10 | word32 | S + A |
R_X86_64_32S |
11 | word32 | S + A |
R_X86_64_16 |
12 | word16 | S + A |
R_X86_64_PC16 |
13 | word16 | S + A - P |
R_X86_64_8 |
14 | word8 | S + A |
R_X86_64_PC8 |
15 | word8 | S + A - P |
A:表示重定位项的 Addend 值;
GOT:表示全局偏移表的地址;
L:符号的过程链接表项的段偏移量或地址;
P:被重定位的存储单元的段偏移或地址,使用 r_offset 计算;
S:索引位于重定位项中的符号的值;
Symbol table '.symtab' contains 65 entries:
Num: Value Size Type Bind Vis Ndx Name
....
46: 0000000000004010 8 OBJECT GLOBAL DEFAULT 23 undef_array
....
59: 0000000000001152 11 FUNC GLOBAL DEFAULT 14 undef_func
...
61: 0000000000001129 41 FUNC GLOBAL DEFAULT 14 main对于标注的 reference<1>位置,调用的是 undef_func 所对应的 Type 是 R_X86_64_PLT32,那么它的计算方式就是 L + A - P。L 在这里通过查符号表知道是 0x1152,A 我们查上面的 .rela.text 表知道是 – 4。P 等于当前 main 函数地址 + r_offset,我们知道 main 地址是 0x1129 ,r_offset 等于 0xe,所以 P 是 0x1137。所以最后算出来的结果就是 0x17 ,换算到汇编指令就是 e8 17 00 00 00 callq 1152 <undef_func>。

我们再来看 reference<2>位置的 undef_array 引用,它的 Type 是 R_X86_64_PC32,它是程序计数器的相对寻址,相对的对象就是 %rip,也就是程序运行到这一行的时候需要用 %rip 指针找到被引用的位置,也就是 undef_array 符号的位置。它的计算方式是 S + A - P。S 我们通过查表也知道是 0x4010,A 查上面的 .rela.text 表知道是 – 8,P 等于 main 地址值 + r_offset 为 0x113D,最终结果为 0x4010 + (- 8)- 0x113D 为 0x2ECB,这个结果对应的指定就是 %rip 的偏移 movl $0x1,0x2ecb(%rip)。

动态链接共享库
按照静态链接,每次静态链接完成后,所有 ELF 文件的 .text 与 .data section 都会被复制到可执行文件中。如果有 n 个可执行文件,那么 .text 与 .data 数据就会被复制多次到内存里面,这是一种对内存的浪费。还有就是随着程序规模的扩大,由于静态链接每次模块更新都必须重新编译链接,也是一件比较浪费时间的事情。
共享库(shared library)就是为了解决静态链接的问题而诞生的产物。它是一个目标模块,在运行或加载的时候,可以加载到任意的内存地址,并和一个内存中的程序链接起来,这个过程称为动态链接(dynamic linking),是由动态链接器(dynamic linker)来执行的。共享库也称为共享目标(shared object),在 Linux 系统中通常用 .so 后缀来表示。
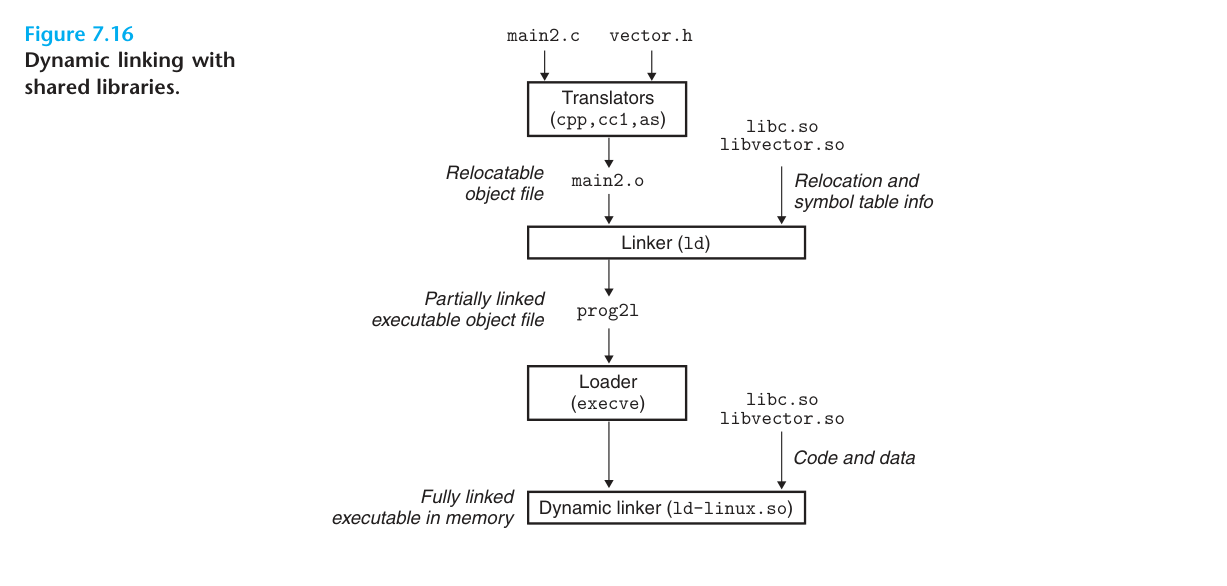
上面这个图就展示了共享库链接的过程。首先我们使用下面指令创建了一个共享库 libvector.so:
$ gcc -shared -fpic -o libvector.so addvec.c multvec.c-fpic 表示生成与地址无关的代码(PIC,Position-independent Code 下面会讲),-shared 选项表示创建一个共享的目标文件。
然后把 libvector.so 库通过动态链接和我们的 main2.c 文件进行链接创建可执行文件 prog21:
$gcc -o prog21 main2.c ./libvect.so上面这一步会把 main2.c 编译成功 main2.o 然后链接称为 prog21 可执行文件。与静态链接不同的是动态链接编译为 main2.o 时编译器不知道 vector 相关的函数地址,如果是静态链接 vector 相关的函数地址会按照静态链接规则将 main.o 与 vector 相关的函数地址引用重定位,但是对于动态链接来说,链接器会将这个引用标记为一个动态链接符号,不对它进行重定位,把这个过程留到装载时再进行。
当加载器加载和运行可执行文件 prog21 时,加载器会运行动态链接器,然后完成 libvector.so 和对其符号引用的重定位。
需要注意的是共享并不是共享整个 libvector.so 内容,而是只共享 .text 可读的代码段部分,数据还是各自的:
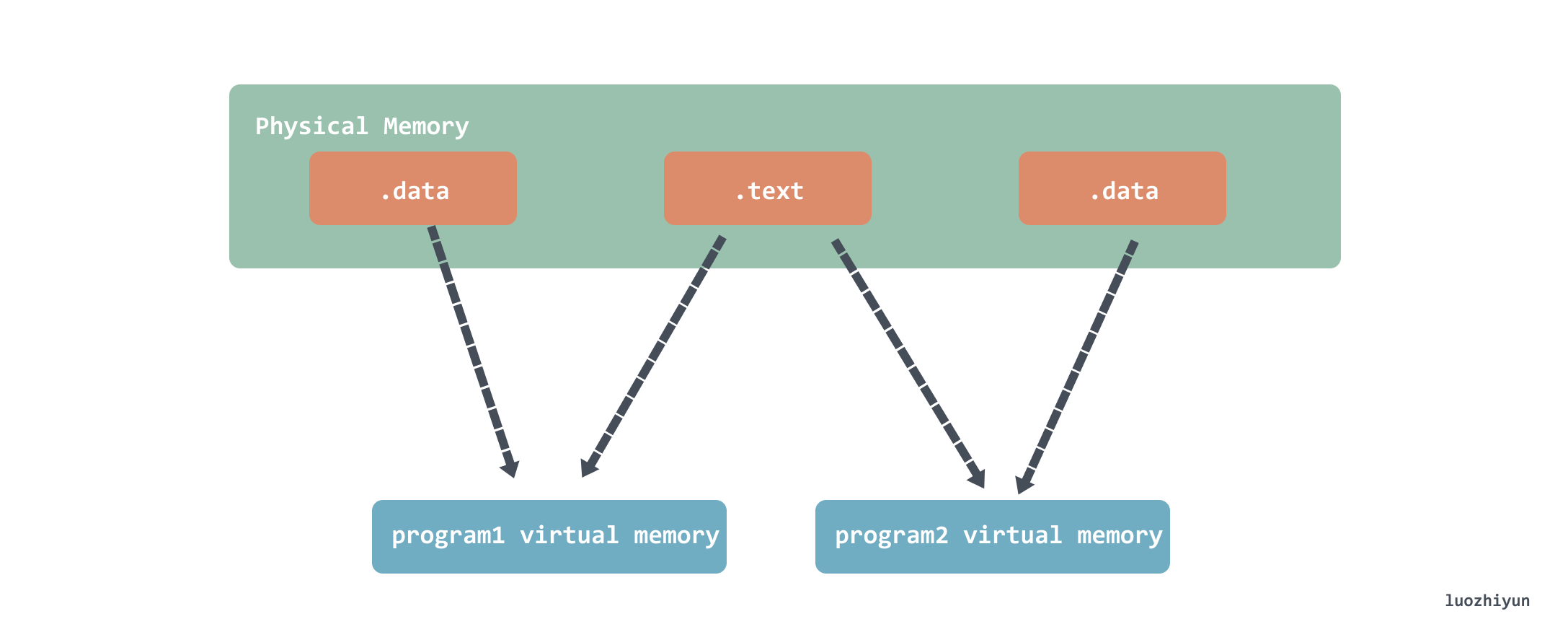
地址无关代码(PIC,Position-independent Code)
因为动态链接共享的是代码,但是指令部分,也就是 .text 部分是不变的,那么就需要在运行的时候能够让指令访问到其他模块的数据或函数。
PIC 数据引用
为了能够让指令能够访问到其他模块的数据或函数,编译器在 .data 段开始的地方创建了一个全局偏移量表( GOT,global offset table )。在 GOT 中每个表项大小为 8 bytes,存放的是被引用的共享库中符号的运行时绝对地址。
比如下面这个例子:
extern int b;
void ext(){
int local_b = b;
}我们编译共享库 test.so:
$gcc -shared -fpic -o test.so test.c 这里引用的另一个共享库中的全局变量 b 其实就是地址无关的,需要通过 GOT 与动态链接器才能确定 b 的地址:
<ext>:
mov 0x2ed0(%rip),%rax # 3fd8
mov (%rax),%eax这里利用了 PC 的相对寻址 0x2ed0(%rip) 找到 GOT 地址为 0x3fd8 的表项。
$ objdump -R test.so
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
0000000000003fd8 R_X86_64_GLOB_DAT b 然后运行时将真实的值从 GOT 写入到 %rax,再将 (%rax) 内存中地址的值拷贝给寄存器 %eax,于是就得到了 b 在运行时的值。
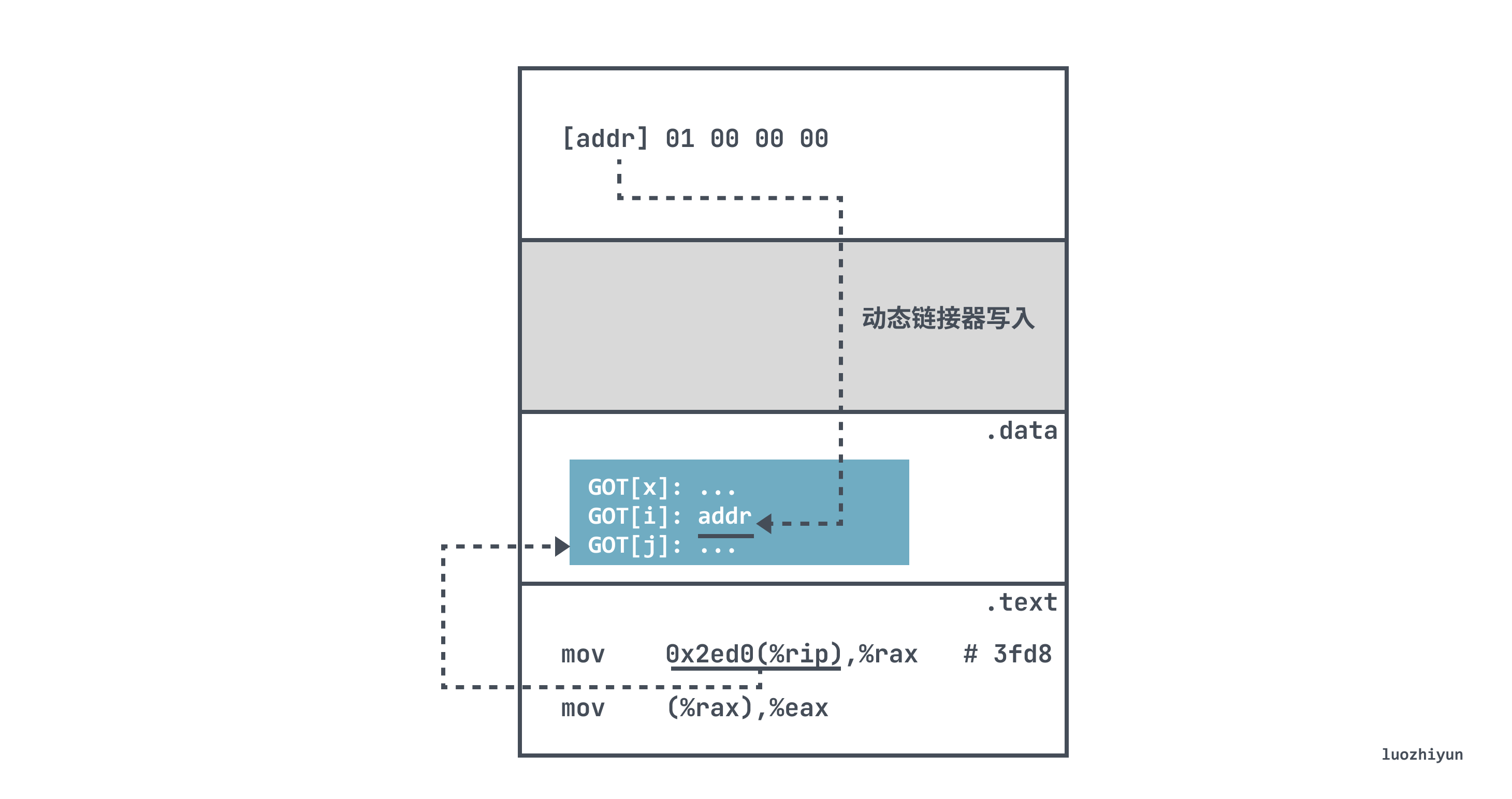
其中 0x2ed0 就是运行时 GOT[2] 和 mov 指令固定距离,这样编译器就可以利用 .text 和 .data 之间不变的距离,产生对变量 a 与 PC 的相对引用,在加载时,动态链接器会重定位 GOT 中的每个条目,使它包含目标的正确的绝对地址。
PIC 函数引用
对于函数引用来说和数据引用稍有不同,函数引用使用了一种叫延迟绑定的做法,基本思想就是当函数第一次使用的时候才进行绑定(符号查找、重定位等),如果没有用到则不进行绑定。
这是因为在动态链接下程序模块之间包含了大量的函数引用(全局变量往往比较少,因为大量的全局变量会导致模块之间耦合变大),所以在程序开始执行前动态链接对函数进行符号查找以及重定位数量过大会耗时不少。另一个原因就是在一个程序运行过程中,可能很多函数在程序执行完都不会被用到,如果一开始就把所有函数都链接好实际上很浪费。
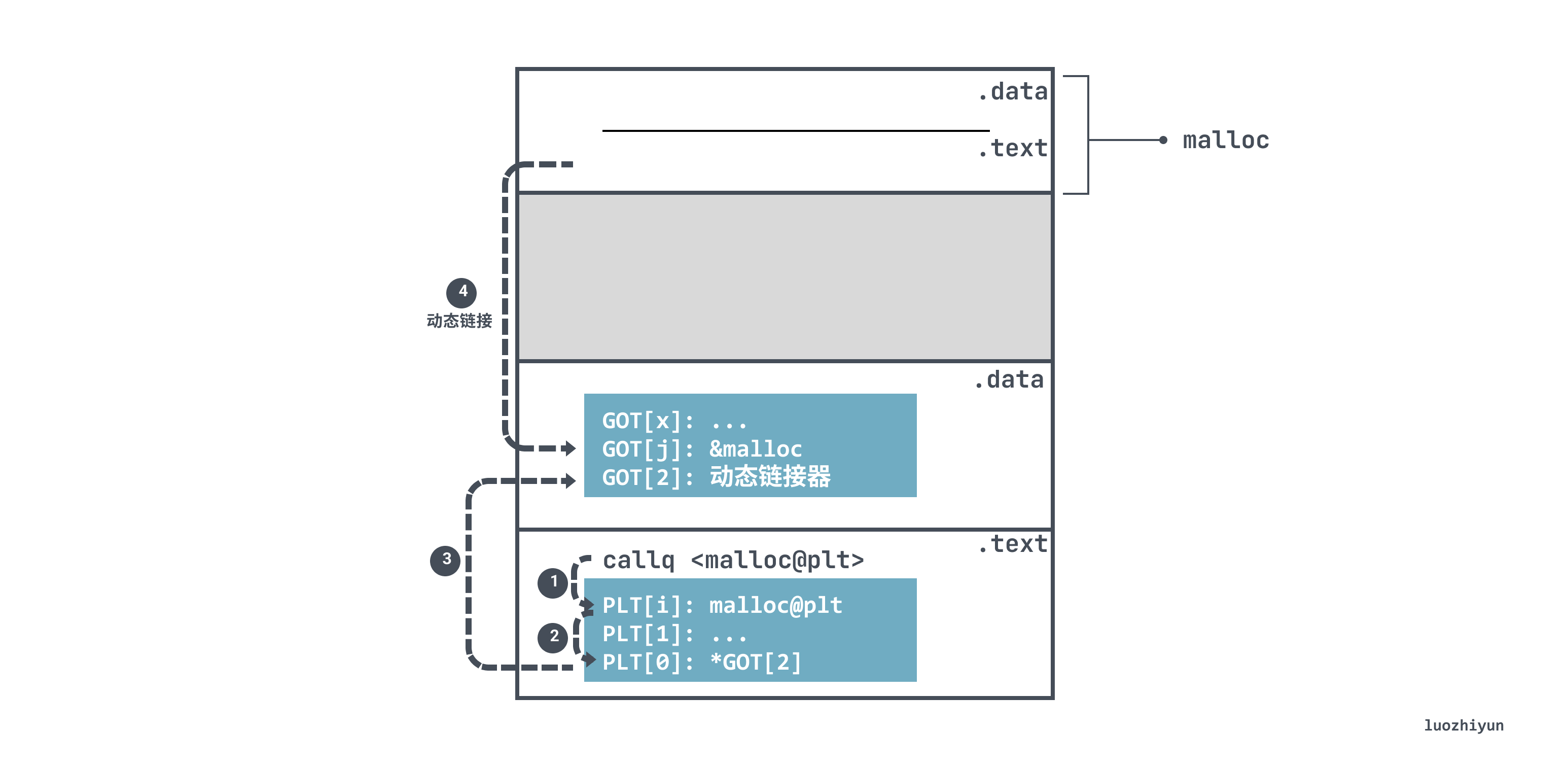
函数引用为了实现延迟绑定,借助过程连接表(PLT,Procedure Linkage Table)来实现。PLT 是一个数组,每个条目是 16 bytes,实现在 .text 段中,内容为若干类似 goto 的标签,rip 可跳转到该地址。
我们弄一个简单的例子来说明:
#include <stdlib.h>
void main()
{
int *a = malloc(64*sizeof(int));
}以上面的 malloc 函数调用为例,由于在 .text 段中的代码并不知道 malloc 的运行地址,所以在执行 call 指令时会跳转到 malloc 对应的 PLT 表项 malloc@plt:
115a: callq 1050 <malloc@plt>malloc@plt 利用了地址无关性,使用相对偏移获取 GOT 表中缓存的 malloc 地址 0x3fd0:
<malloc@plt>:
1054: bnd jmpq *0x2f75(%rip) # 3fd0 <malloc@GLIBC_2.2.5> 但是由于延迟绑定的关系,所以第一次运行的时候跳转到的 GOT 表项中的值实际上是 <.plt> 中动态链接器的位置,然后会跳转到动态链接器的代码段。
当动态链接器取得 malloc 的运行时地址后,就会将相应的的地址值填入到 GOT 表项中。如果再次调用 malloc@plt ,执行到 jmpq *0x2f75(%rip)时,里面的值就是 malloc 的真实地址,不需要通过 <.plt> 项中的动态链接器,可以直接跳转到 malloc。
总结
这篇文章其实总体来说包含三个部分:
-
讲解了 ELF 文件结构,帮助我们理解后面的链接过程;
-
通过静态链接讲了链接一般包含的几个过程;
-
最后讲了静态链接有什么弊端,为什么会有动态链接,以及它是怎么做的。
通过这几个部分的讲解可以清晰的看到链接器在连接过程中做了什么。
Reference
http://www.skyfree.org/linux/references/ELF_Format.pdf
http://chuquan.me/2018/06/03/linking-static-linking-dynamic-linking/
https://www.bilibili.com/video/BV17K4y1N7Q2?p=26&vd_source=f482469b15d60c5c26eb4833c6698cd5
https://github.com/yangminz/bcst_csapp
https://zhuanlan.zhihu.com/p/389408697
https://www.ucw.cz/~hubicka/papers/abi/node19.html
https://mp.weixin.qq.com/s/4ZsNOxHUHOeTk9eI1X0Tcg
《程序员的自我修养——链接、装载与库》
《深入理解计算机系统》
