什么是加密货币
加密货币(Cryptocurrency)是一种运用密码学原理来确保交易安全并控制新单位创造的数字交易介质 。
根据 Jan Lansky 所述,加密货币是满足六个条件的系统:
- 去中心化:该系统无需中心机构,也就是不需要央行,靠共识维持。
- 所有权记录:系统能够清晰地记录每一单位加密货币及其当前的所有权归属。
- 发行机制:该系统定义能否产生新的加密货币。如果可以,则系统需定义新币的来源,并定义如何确定这些新币的所有者。
- 密码学所有权:对加密货币的所有权只能通过密码学手段(即私钥)来证明和行使。
- 所有权转移:该系统允许通过交易来改变加密货币的所有权。交易仅可从能证明加密货币当前所有权的实体发布。
- 双重支付防范:如果同一时间产生了两个改变相同加密货币所有权的指令,该系统最多只能执行其中一个。
这些条件共同定义了一种革命性的资产形式,其价值和安全性不依赖于任何单一机构的信用背书。有些人简单的将它归结为“数字化”,其实是不对的,因为支付宝、信用卡支付等都是数字话的,但是这些传统数字金融系统的核心是建立在对中心化中介机构(如银行、支付网关)的“信任”之上,由它们来维护账本、验证交易的合法性 。加密货币的根本性突破在于,它通过密码学、分布式共识等一系列技术手段,构建了一个“去信任化”(Trustless)的系统。
区块链的核心数据结构
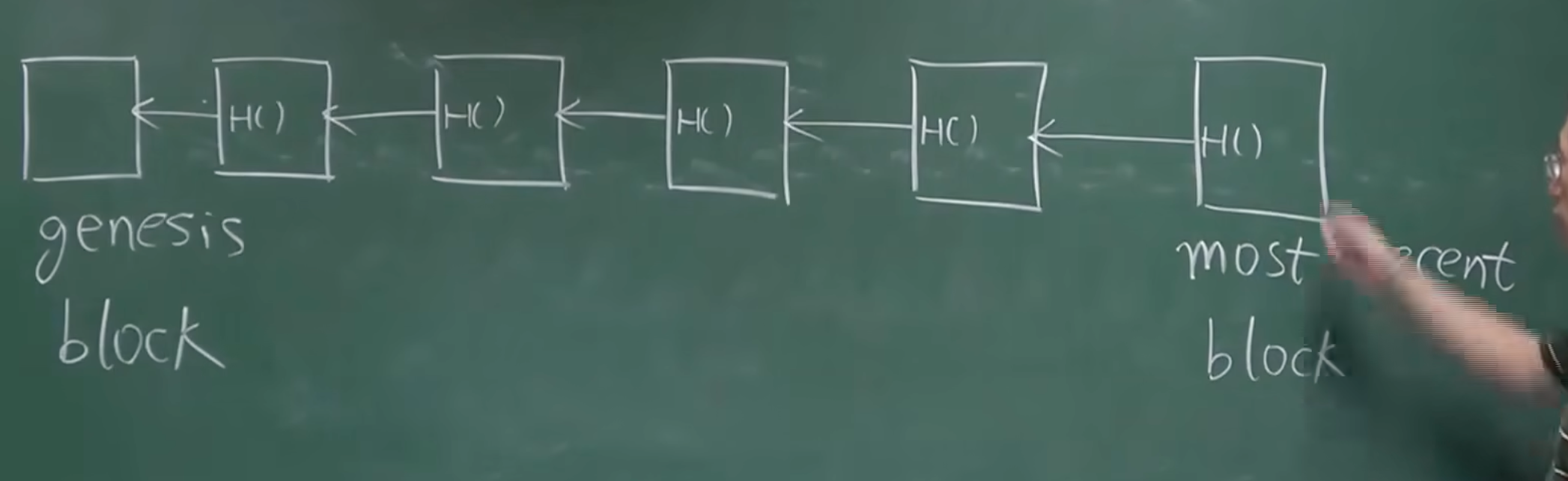
所谓区块链,其实是由一系列按时间顺序连接的数据单元构成的,这些单元被称为“区块”(Block)。每一个区块包含以下内容:
- 每个区块的交易数据;
- 指向前一个区块的加密引用;
链条的起点是一个特殊的区块,被称为“创世区块”(Genesis Block),因此没有指向“前一个区块”的引用。
那么在实现上,区块是如何保存交易数据和引用的呢?数据结构是怎样的?每个区块在数据结构上,包含了区块头(Block Header)和区块体(Block Body):
- 区块头:每个区块起始处的一个紧凑的、固定大小的部分。在btc协议中,其大小为80字节 。头中不含交易数据,仅包含了元数据(metadata)。元数据包括指向前一个区块的链接、时间戳以及对区块体内所有交易数据的加密摘要。
- 区块体:这是一个可变大小的部分,其主要内容是该区块所包含的经过验证的、详细的交易记录列表 。
区块头
我们以btc为例,在btc协议中,区块头大小为80字节 。根据功能,这80字节可以被划分为六个独立的字段,共同构成了区块的元数据 。
-
版本(Version) – 4字节
-
前一区块哈希(Previous Block Hash) – 32字节。这是区块链数据结构中最关键的连接元素,它就是哈希指针。该字段存储的是其父区块(即链上的前一个区块)的区块头的SHA256(SHA256())双重哈希值 。通过这个字段,每个区块都牢固地指向其前驱,从而将独立的区块编织成一条不可分割的、按时间顺序排列的链。
-
Merkle Root – 32字节。btc 中使用的 merkle tree 的形式存储了区块体内所有交易,所以在头里面,还存储了区块中 merkle tree 的头节点,也就是 merkle root;
-
时间戳(Timestamp) – 4字节,记录了该区块被矿工创建的大致时间。
-
难度目标/比特(Difficulty Target / Bits) – 4字节。表示了当前区块挖矿的难度目标 ,也就是用来挖矿的。
-
随机数(Nonce) – 4字节。这是一个由矿工在挖矿过程中不断改变的计数器 。矿工将版本、前一区块哈希、默克尔根、时间戳、难度目标和这个随机数拼接在一起,形成80字节的区块头,然后对其进行哈希计算。如果结果不满足难度目标,矿工就将随机数加一,然后再次尝试。这个暴力枚举的过程就是工作量证明的核心。
区块体
区块体则承载了该区块内所有经过验证的交易信息,所以可以把它理解为账本。以btc为例,它的区块体的结构由两部分构成:
- 交易计数器 (Transaction Counter):记录该区块中包含的交易总数。
- 交易列表 (Transactions):连续存放的、该区块内所有交易的原始数据。
那么如何记录一笔交易呢?比如,我们现实生活中进行转账,A 要给 B 转账,那么对于这笔记录首先我们需要知道这个币从哪里来的,这个叫做输入(Inputs);然后需要知道这个币是转给了谁,这个叫做输出(Outputs)。在转账的过程中,由于互联网上是基于互不信任的原则,所以这笔转账的过程还需要密钥加密,这叫数字签名(Digital Signatures),数字签名由资金所有者使用其私钥生成。
A转了5个币给B,给了 5个币给 C,这个过程中不停的交易,形成的这个链就是账本。比如下图,可以看成是交易账本的简化形式。
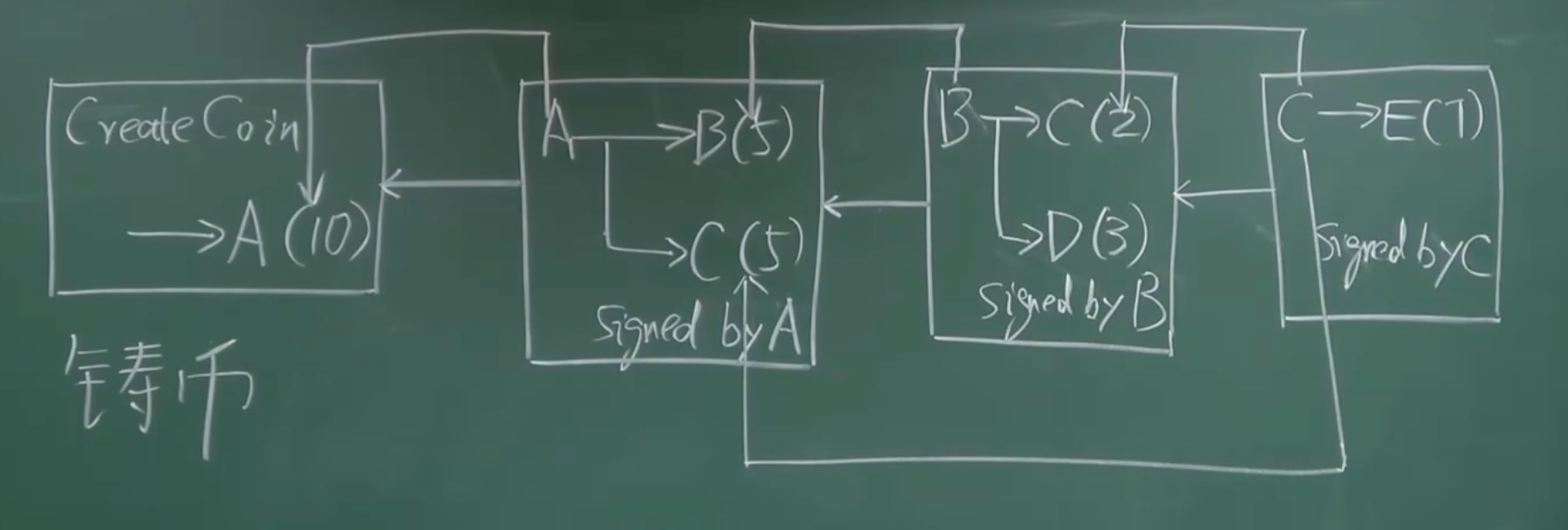
那么交易账本的形式有了,那么如何构建安全的交易呢?首先,我们要了解一下什么是签名,上面我们也说了,在交易的过程中,A 转帐给 B,A 需要给这笔转账用 A 的私钥加密,这其实就是签名。
整个签名,其实就是非对称加密的过程,在btc钱包中,公钥相当于银行账号,私钥相当于银行密码。比如说A 要给 B 转 1 个 BTC,当 A 发起这笔交易时,他的钱包软件会做以下事情:
-
首先要回答 A 的“钱包”里有什么?
假设 A 的钱包里并不是一个写着“我有 1.2 BTC”的数字。实际上,他的钱包知道他拥有两笔“未花费的钱”(Unspent Transaction Output,简称 UTXO),比如:
- UTXO-1:价值 0.5 BTC(来自之前别人付给 A 的一笔钱)
- UTXO-2:价值 0.7 BTC(来自更早之前别人付给 A 的另一笔钱)
-
A 要给 B 转 1 个 BTC
当 A 发起这笔交易时,他的钱包软件会做以下事情:
- 输入 (Input):交易的“输入”必须明确指出它要花费哪几笔 UTXO。在这个例子里,钱包会选择 UTXO-1 (0.5 BTC) 和 UTXO-2 (0.7 BTC) 作为输入。总输入金额为 1.2 BTC。
- 指定输出 (Output)
- 输出1:向 B 的地址支付 1 BTC。这会为 B 创建一个价值 1 BTC 的新 UTXO。
- 输出2 (找零):将多余的 0.2 BTC(1.2 – 1.0 = 0.2)转回给 A 自己的一个新地址。这会为 A 自己创建一个价值 0.2 BTC 的新 UTXO。
- 签名:A 用自己的私钥对这笔完整的交易(包括输入和输出)进行数字签名。
-
最后就是验证这笔交易如何验证,在 BTC 中整笔交易要达成共识,入链才算完成。
这笔交易被广播到btc网络后,每一个收到它的节点(矿工)都会进行严格的验证:
- 验证签名:首先,用 A 的公钥验证交易签名是否有效。
- 验证资金来源(最关键的一步!):节点会追溯整个区块链历史,去检查 A 在交易输入中声称要花费的 UTXO-1 和 UTXO-2 是否真的存在,并且是否真的是“未花费”的状态。
- 检查结果:
- 如果节点在过去的区块里找到了这两笔 UTXO,确认它们属于 A,并且之前从未被花掉过,那么节点就确认 A 确实拥有这笔钱。
- 如果 A 试图花费一个不存在的、或者已经被花掉的 UTXO(这就是“双花攻击”),全网的节点在查账时会立刻发现这个输入是无效的,从而拒绝这笔交易。
- 一旦验证通过,矿工就会把这笔交易打包进一个新的区块。
好了,到这里,一笔交易内容有什么,以及如何保证安全已经说明了,那么如何在不下载全部数据的情况下,高效地验证某一个“小数据”是否属于这个“大数据集合”?就比如,我的手机钱包,如果验证 1 笔交易,而不用下载整个区块?
这就要提到 Merkle Tree,它是交易列表构成的一个树形结构,Merkle Tree 的叶子节点存的是每一笔交易的哈希值(Transaction Hash,也叫 TXID),可以看成是下图这样的结构:
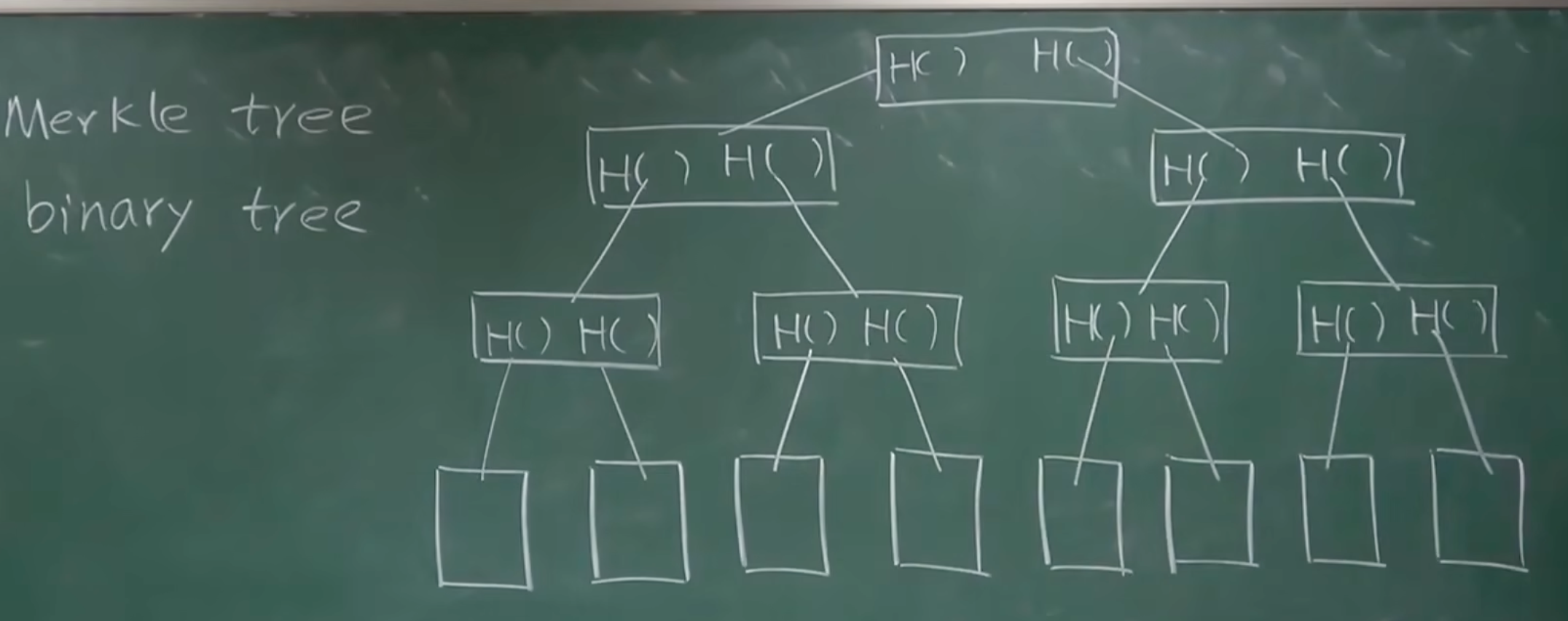
merkle tree 本质上是一棵哈希二叉树:
-
树的叶子节点是原始数据块(在区块链中就是一笔笔的交易)的哈希值。
-
树的非叶子节点(树枝和树干)是它下面两个子节点哈希值拼接后再计算出的哈希值。
-
这个过程不断重复,层层向上,直到只剩下一个最终的、位于最顶端的节点,这个节点被称为 merkle root。
merkle tree被发明出来主要有两个目的:
-
保证数据完整性(防篡改)
merkle root 是对区块内所有交易的最终摘要。任何一笔交易哪怕被改动一个字节,其对应的叶子哈希就会改变,这个改变会像多米诺骨牌一样,层层向上传导,最终导致计算出的merkle root 完全不同。
-
极高的验证效率(轻量级验证)
它允许在不下载整个区块数据的情况下,就能快速验证某笔交易是否存在于该区块中。
比如手机钱包知道自己的交易哈希
H3,钱包从网络上下载了该区块的区块头(只有80字节,非常小),并从中获取了正确的merkle root ,那么对于H3来说,它的验证路径是H3 -> H34 -> Merkle Root。也就是只需要,它的直接兄弟H4,它的上一层节点的兄弟H12,然后就可以通过计算 hash 进行对比验证,这个过程就叫Merkle Proof。整个过程,手机钱包只需要下载几十字节的区块头和几十字节的 Merkle Proof,就能完成验证,而无需下载整个区块(可能好几MB)的所有交易数据,极大得节省了资源。
所以通过 merkle tree 就可以实现高效的“存在性证明”(Merkle Proof)以及保证数据完整性(防篡改)。
Hash 在区块链的作用?
其中在区块链中使用 Hash 算法有其关键的作用:
-
collision resistance:在btc中使用的是SHA256(SHA256())双重哈希值,几乎不可能出现hash碰撞,因为如果可以轻易找到“碰撞”(两个不同输入得到相同输出),那么恶意攻击者就可能用一笔伪造的交易来替代合法的交易,从而破坏整个系统的信任;
-
Hiding:由于算法的不可逆,所以无法由hash值推导出原值。这个特性对于保护数据隐私至关重要。在密码学中,这也被称为抗原像性 (Pre-image Resistance)。;
-
puzzle friendly:如果想要找到某个特定的hash值对应的输入是什么,只能挨个去尝试,没有其他任何途径可以找到符合条件的hash值。
区块链中,由于下一个的指针是指向前一个,如果某个块的hash发生了改变,那么后续的也要改变,也就是牵一发而动全身,比如一个Merkle tree,叶子节点变了,其他节点也要变,因为其他节点是根据叶子节点算出来的。
[ Merkle Root ]
/ \
/ \
[ Hash_ABCD ] [ Hash_EFGH ]
/ \ / \
/ \ / \
[ Hash_AB ] [ Hash_CD ] [ Hash_EF ] [ Hash_GH ]
/ \ / \ / \ / \
H(A) H(B) H(C) H(D) H(E) H(F) H(G) H(H)所以btc 中某个本地节点可以只保存最近的某些节点,如果需要前面的其他的节点可以问别人要,并且可以通过hash计算的方式来保证别人给的区块一定是正确的。就比如上图,只有几个节点,但是可以通过后面的节点计算别人给过来的前面的节点是否正确。
举例:
- 全节点发给你三样东西:
TX_C(交易 C 本身)H(D)(你的“兄弟”哈希)Hash_AB(你“叔叔”辈的哈希)Hash_EFGH(你“伯父”辈的哈希)
- 轻钱包开始自己计算:
- 第 1 步: 先把
TX_C自己哈希一次,得到H(C)。 - 第 2 步: 用自己算出的
H(C)和全节点给你的H(D)组合起来哈希:H( H(C) + H(D) )算出了Hash_CD
- 第 3 步: 用全节点给你的
Hash_AB和上一步算出的Hash_CD组合起来哈希:H( Hash_AB + Hash_CD )算出了Hash_ABCD
- 第 4 步: 用上一步算出的
Hash_ABCD和全节点给你的Hash_EFGH组合起来哈希:H( Hash_ABCD + Hash_EFGH )算出了一个“最终的 Root”
- 算出来的“最终的 Root” 和从区块头里拿到的那个“标准答案 Merkle Root”进行对比。
因为哈希的collision resistance特性。如果“别人”的 TX_C 是假的,或者 H(D)、Hash_AB 中任何一个是假的,最终算出来的 Root 都不可能与“标准答案”一致。
分布式共识 distributed consensus
一个交易要被认可要取得分布式共识。那么什么什么是分布式共识?
想象一下,一群好朋友(比如 100 个人)共同记一本账本,记录着大家之间谁欠谁钱。他们没有一个中心记账员(比如银行),而是每个人手上都有一本一模一样的账本。
当其中一位朋友 A 要转 100 元给朋友 B 时,他会向所有人大喊:“我要从我的账上转 100 元给 B!”。
这时候问题来了:
- 怎么确保 A 真的有这 100 元?
- 怎么确保 A 没有同时跟别人说“我要把这 100 元转给 C”?(也就是所谓的“双花攻击”)
- 最重要的是,在没有中心决策者的情况下,如何让这 100 个人全都同意在自己的账本上写下“A 转给 B 100 元”这同一笔记录,并且确保之后没有人可以反悔或篡改?
分布式共识 就是为了解决这个问题而设计的一套规则和方法。它的目标是:让一个分布式系统中的所有参与者(节点),在没有中央指挥的情况下,最终能够对某个状态或数值达成一致的协议。
如何达成分布式共识
上面我们也提到了,如果想要 A 转给 B 1 个 BTC,在 BTC 中整笔交易要达成共识,入链才算完成。这个共识算法就是工作量证明(Proof of Work, PoW)。
在 A 转 1 个 BTC 给 B 的时候,会用私钥对一笔交易进行数字签名,然后钱包会将这笔签好名的交易广播到整个区块链网络中,附近的节点会接收到这笔交易。
之后:
-
节点验证与传播
-
初步验证:
接收到交易的节点(我们称之为“矿工节点”)会立即进行验证,首先用A的公钥检查数字签名是否正确,再来就是追溯A的交易历史,确保您确实拥有足够的资金来支付这笔交易;
-
验证通过后,这笔交易会被放入该节点的“内存池(Mempool)”中,这是一个等待被打包的交易的临时集合;
-
该节点会将这笔验证过的交易继续传播给与它相连的其他节点,直到这笔交易遍布全网。
-
-
竞争记账权(挖矿)
- 所有矿工节点会从自己的交易池中挑选一批交易,将选中的交易和上一个区块的哈希值等信息打包成一个“候选区块”
- 矿工们开始进行疯狂的哈希计算,不断变换候选区块头中的一个随机数(Nonce),试图找到一个满足特定难度目标的哈希值(例如,开头有非常多个零);
-
达成共识与全网同步
- 假设矿工 M 率先找到了正确的哈希值,他立刻向全网广播他创建的、包含您交易的新区块;
- 网络上其他矿工收到这个新区块后,会停止自己的计算,并立即验证这个区块的有效性(包括验证其中的每一笔交易和那个“幸运哈希值”是否符合规则);
- 验证非常快速。一旦确认无误,其他节点就会承认这个新区块是合法的,并将其添加到自己的区块链副本的末端。
- 这就代表,全网对“这个新区块以及其中包含的所有交易是有效的”这件事达成了共识。
由于网络问题产生分叉怎么办?比如即同时有两个矿工挖出区块,这个时候为了确保交易不可逆转,通常需要等待更多的区块在此基础上继续生成。
一般来说,在btc网络中,等待 6 个区块确认(大约 1 小时)后,该笔交易就被认为是完全被承认且不可篡改的了。
为什么矿工要帮忙做工作量证明
上面的工作量证明看起来实际上需要很大的计算量,需要很多计算机的算力,所以矿工做这些事情也会获得相应的报酬去激励他们继续保护和运行整个区块链网络。矿工主要有两部分收益:
-
区块奖励(Coinbase Reward)
这是系统凭空创造出来、作为对矿工维护网络安全奖励的新币。这部分奖励是btc(或其他加密货币)通货膨胀的主要来源。对于btc来说这个奖励的数额是协议预先规定好的,并且会定期“减半”(Halving)。例如,btc最初每个区块奖励50个btc,现在(2024年减半后)是3.125个btc;
-
交易手续费(Transaction Fees)
这是该矿工从他打包的那个区块中,所有交易的发起者支付的手续费的总和。用户为了让自己的交易能被矿工尽快打包,会附加一笔手续费。矿工自然会优先选择手续费高的交易来打包。这部分收益的数额是不固定的,取决于当时网络的拥堵情况和用户愿意支付的费用。
所以矿工的总收益 = 区块奖励 + 该区块内所有交易的手续费总和。
但是在 btc 中随着时间的推移,区块奖励会越来越少,直到最终变为零(预计在2140年左右)。到那时,矿工维护网络的唯一动力就将完全来自于交易手续费。这个设计确保了即使在所有币都发行完毕后,依然有经济激励促使矿工继续保护和运行整个区块链网络。
挖矿
上面我们提到了,挖矿的过程其实就是改变block header 里面的 Nonce 字段,计算出一个有效的“哈希值”,计算出的哈希值必须小于或等于当前网络设定的“目标值” (Target)。
举个例子,假设目标是: 00000000000000000005a3f6d8a4c1d8d3f6a8b3c5d1e7f9a2b4c6d8e。那么,任何计算出来的哈希值,只要在数值上比上面这个小,就是有效的。比如:00000000000000000001b8d3c5d1e7f9a2b4c6d8e4a3f6d8a4c1d8 (这个值更小,所以是有效的)。
但是Nonce 只是一个 32 位的字段,目前来说矿机每秒可以执行数百亿亿次哈希运算(TH/s)。一台高端ASIC矿机(例如140 TH/s)可以在微秒级别的时间内遍历整个Nonce空间。
所以仅靠Nonce 是找不到对应难度目标(Target)的值,当然Timestamp也可以有一定的调整空间,但是比较有限,后面就演变成使用 ExtraNonce 来扩展搜索空间。ExtraNonce 指的是矿工放置并修改在铸币交易(Coinbase Transaction)的scriptSig字段(也被称为coinbase data)中的任意数据,它可以进行修改 。
scriptSig 字段通常是用来数字签名来证明所有权用的,但是Coinbase交易是凭空创造新币的,它不消耗任何已存在的UTXO。因此,其输入中的scriptSig字段无需包含任何解锁脚本或数字签名。根据btc协议,这部分空间可以由矿工自定义填充,长度限制在2到100字节之间。
那么挖矿算法的大致流程就会变成:
- 构建区块模板:
- 从内存池(mempool)中选择交易,通常按费率(fee rate)高低排序。
- 构建铸币交易,包含区块奖励、交易费,并设置一个初始的
ExtraNonce值(如0)。 - 基于此交易集合计算出
hashMerkleRoot。 - 组装候选区块头,填入
Version、hashPrevBlock、hashMerkleRoot、当前的Time和Bits。
- 内层循环(Nonce迭代):
FOR nonce FROM 0 TO 2^32:- 在区块头中设置当前的
nonce值。 - 计算
hash = SHA256(SHA256(header))。 IF hash <= Target:- 找到解。广播完整的区块。
- 返回第一步,开始构建下一个区块的模板。
- 在区块头中设置当前的
- 外层循环(ExtraNonce迭代):
IF内层循环完成仍未找到解:- 在铸币交易中递增
ExtraNonce的值。 - 重新计算
hashMerkleRoot。 - 更新区块头中的
hashMerkleRoot字段。 - (可选)如果时间变化足够大,更新
Time字段。 - 返回第二步,使用新的区块头重新开始
Nonce的迭代.
- 在铸币交易中递增
并且为了控制 btc 的产量,在btc网络诞生之初,矿工每成功打包一个区块,可以获得 50 BTC 的奖励。并且btc的协议规定,每产生210,000个区块,区块奖励就会减少一半(减半)。由于比特币网络的目标是平均每10分钟产生一个区块,210,000个区块大致相当于4年的时间(10分钟×210,000≈4年)。
我们可以用一个等比数列求和的公式来表示这个过程:
总供应量 = 210000×(50+25+12.5+6.25+…) = 210000×50×(1+0.5+0.25+0.125+…)=210000×50×2=2100w
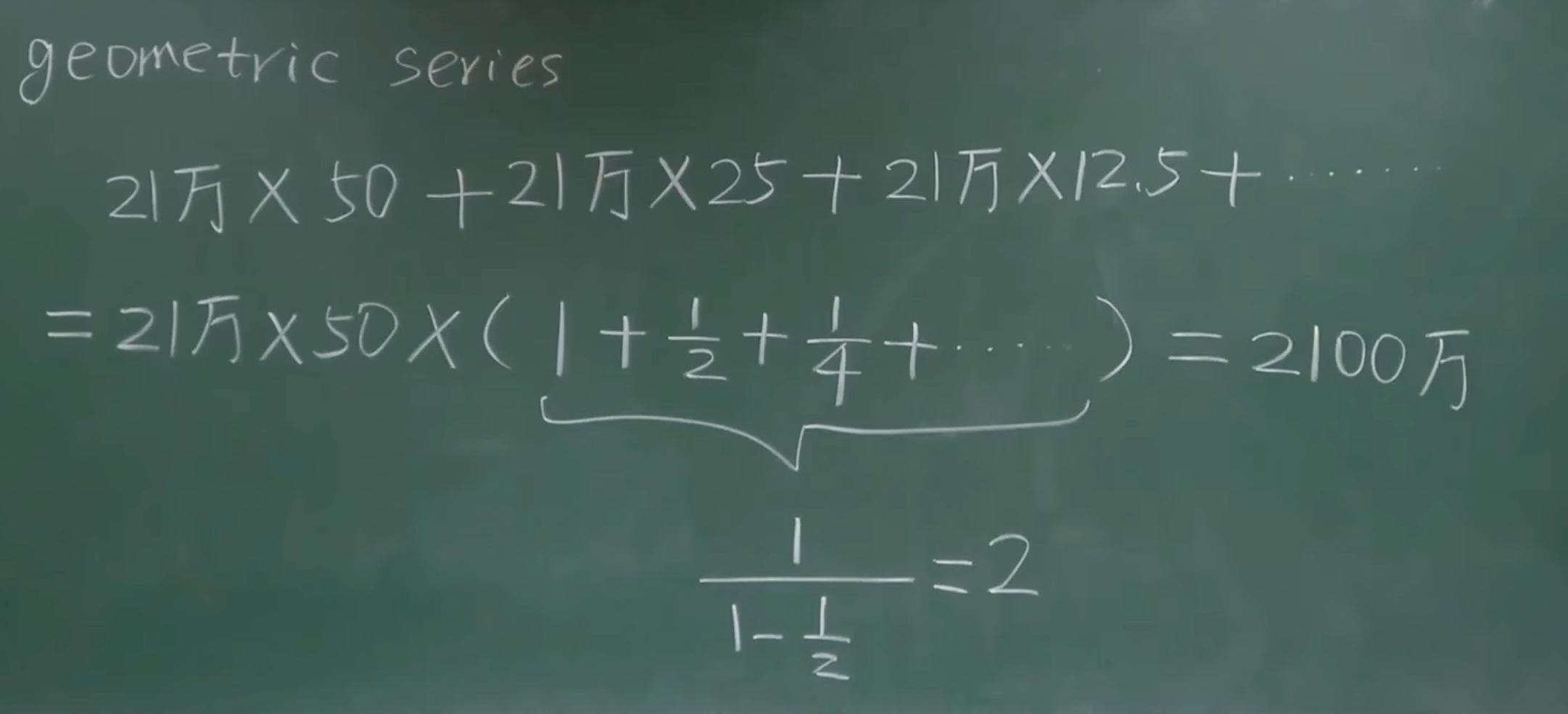
由于区块奖励不断减半,奖励金额会变得越来越小。大约在第33次减半(约2140年左右)之后,区块奖励将变得微不足道(小于1聪,即比特币的最小单位)。届时,可以说几乎所有的比特币都已被挖出,矿工的收入将完全依赖于交易手续费。
这种通缩模型的设计,使得比特币具有了稀缺性,从而避免了像传统法定货币那样因无限增发而导致的通货膨胀问题。
为什么早期仅遍历Nonce就可以,现在却不行?
主要是因为btc它会自动的调整难度,早期的时候参与者少,算力低在只有几 MH/s 的算力下,要遍历完这43亿种可能性需要很长时间(几百秒甚至更久)。当时网络的目标是大约10分钟产生一个区块,因此,仅仅通过不断尝试和改变Nonce,就有非常大的概率能在这10分钟内找到一个符合条件的哈希值。
现在对于一台算力为 100 TH/s(1014 次哈希/秒)的现代ASIC矿机来说,遍历完43亿的Nonce仅需要0.000043 秒,如果还是这个难度,估计用不了几秒就要被挖光了。
btc的难度调整是其协议中最优雅的设计之一,它确保了无论全网算力如何变化,新区块的产生速度都能稳定在平均10分钟一个。
btc的难度目标(Target)是个以一个256位的数字。挖矿的本质就是找到一个区块头的哈希值,使其小于或等于这个目标值。目标值越低,挖矿越难。因为一个更低的目标值意味着哈希结果的开头必须有更多的“0”,符合条件的哈希值就越少,找到它所需要的计算次数就越多。
所以为了实现大约10分钟产生一个区块这个目标,btc会动态的调整难度,难度调整的具体机制如下:
- 比特币网络中的每个全节点都会每2016个区块自动进行一次难度调整。节点会计算生成这最近的2016个区块所花费时间,即 2016区块 × 10分钟/区块 = 14天;
- 节点会根据实际时间与期望时间的偏差来调整下一个周期的目标值,公式:
New Target = Old Target * (Actual Time / Expected Time)- 挖得太快了。如果
Actual Time小于20160分钟(比如只用了12天),说明全网算力增强了。此时(Actual Time / Expected Time)这个比率小于1,New Target就会变小,从而增加挖矿难度。 - 挖得太慢了。如果
Actual Time大于20160分钟(比如用了16天),说明全网算力下降了。此时这个比率大于1,New Target就会变大,从而降低挖矿难度。
- 挖得太快了。如果
- 为了防止网络因算力剧烈波动而产生过大的难度变化,单次调整的幅度被限制在一个4倍的范围内。即,调整系数(
Actual Time / Expected Time)最大不会超过4,最小不会低于1/4。
我们也可以看到下面图的难度曲线的设置,是越来越陡峭的,跟价格几乎是成正比:
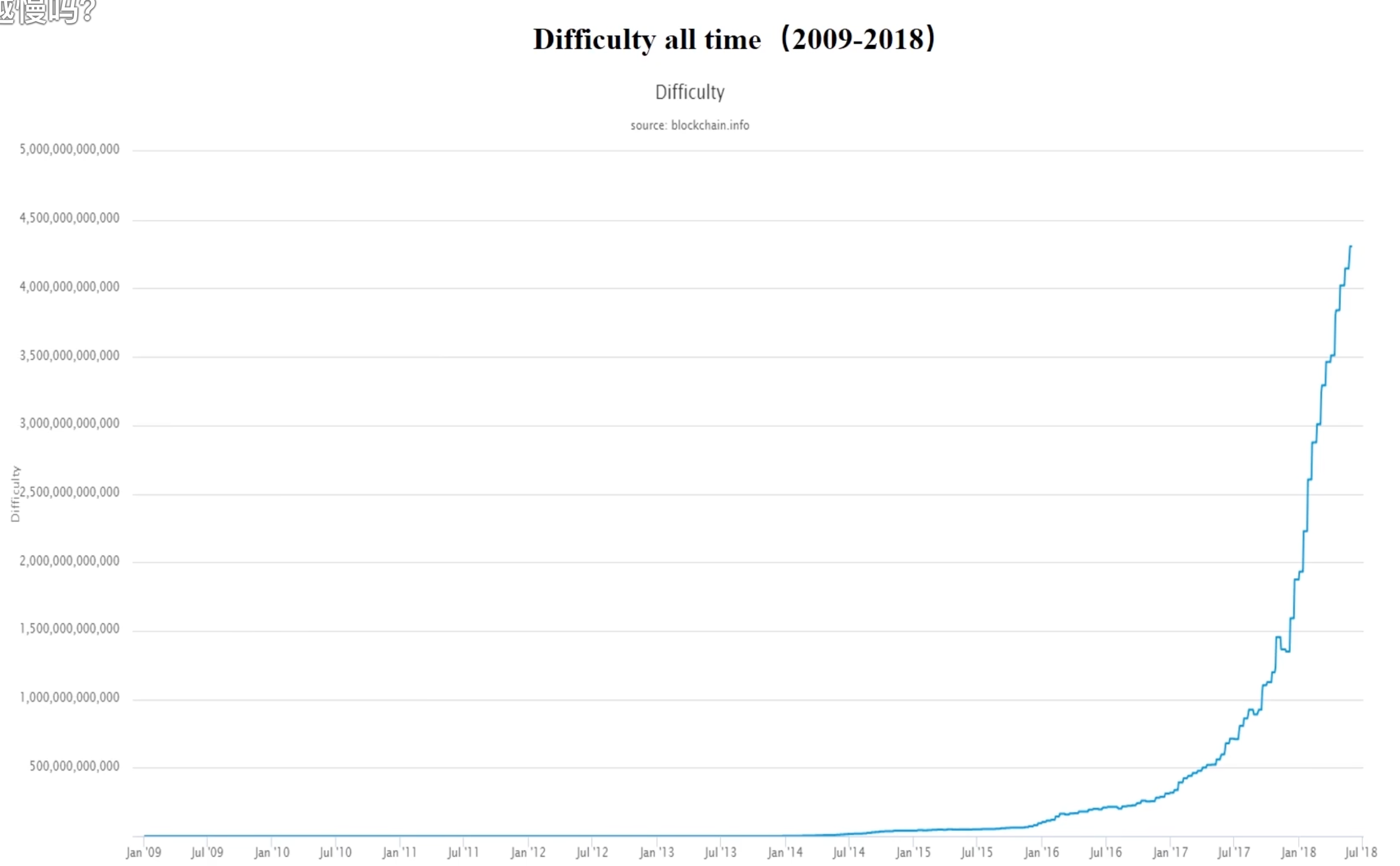
并且比特币矿机也不再是以前的 GPU 时代了,而是专门的专用矿卡进行挖矿。比特币矿机的演变是一场追求极致算力和能效比的“军备竞赛”:最初人们用个人电脑(CPU) 就能挖矿,很快被游戏显卡(GPU) 的高并行算力所取代;接着,更省电的FPGA(半定制芯片) 短暂出现,但最终被ASIC(专用定制芯片) 以绝对的算力和能效优势彻底统治,使挖矿从此进入了专业的工业化时代。
Progress-Free性质
Progress-Free 指的是“无记忆性”(Memoryless),也就是在任何给定时刻,矿工找到下一个区块的概率与他们过去已经付出的努力无关。
在btc挖矿中,矿工们不断地进行哈希运算,尝试找到一个小于当前网络目标难度的哈希值。每一次哈希运算都是一个独立的、随机的尝试。也就是说包含两个特性:
- 独立的尝试: 每一次哈希运算都使用一个略有不同的输入值(通过改变一个称为“nonce”的随机数)。因此,前一次哈希运算的结果对后一次完全没有影响。就像抛硬币一样,无论您已经连续掷出了多少次反面,下一次掷出正面的概率永远是50%,和过去的努力无关。
- 成功的偶然性: 能否找到有效的哈希值,完全取决于运气。
由于这两个特性,表示过去的努力不会累积,每时每刻都是一个全新的开始,确保了挖矿的公平性,即便是算力较低的矿工,理论上也有机会在任何时刻找到区块。
挖矿攻击
Boycott Attack
指的是网络中掌握显著比例算力(或权益)的参与者(通常是大型矿池或PoS验证者)联合起来,故意“抵制”或“排斥”网络中的某些特定元素。
在这种攻击中最常见的就是一个或多个拥有大量算力的矿池故意拒绝将某些合法的交易打包到他们挖出的区块中。比如,某个矿池为了遵守其所在国的法规(如美国的 OFAC 制裁名单),宣布将“抵制”所有与黑名单地址相关的交易。
这种攻击的严重程度取决于“抵制联盟”掌握的算力。如果抵制联盟的算力低于 51%,被抵制的交易仍然可以被确认,但它们必须等待那些“不参与抵制”的矿池(例如只占 30% 算力)来挖到区块。
如果抵制联盟的算力超过 51%。他们不仅自己不打包这些交易,他们还会故意孤立(orphaning)任何包含了这些交易的诚实区块(因为他们总能挖出更长的链)。结果就是被抵制的交易将永远无法被打包上链。这等同于将某个用户或应用永久地“踢出”了网络。
这种攻击并不像“双花”那样直接窃取资产,但它直接攻击了区块链最核心的价值主张之一:抗审查性(Censorship Resistance)和中立性(Neutrality)。
51% Attack
当单个矿工或矿池掌握了全网超过 50% 的算力时,他们就有能力制造出一条比诚实网络更长的“分叉链”。攻击者可以在主链上将 BTC 发送给商家(例如,换取法币或商品),然后在自己的分叉链上构造一笔交易将同样的 BTC 发送回自己的地址。当他的分叉链长度超过主链并被网络接受时,之前给商家的交易就被“撤销”了,从而实现Double Spending。
但是这样的攻击需要天价的硬件和电力成本,而且成功攻击会摧毁人们对 BTC 的信心,导致币价暴跌,攻击者自身的收益也会大打折扣,,因此在经济上是不理智的。
虽然在BTC上不太可能这么做,但是这一点在那些算力较低的山寨币(altcoins)上体现得淋漓尽致。攻击者可以按小时租用强大的算力(OPEX)。对于一个小币种来说,攻击者可能只需租用比特币网络总算力的一小部分,就能轻松达到该小币种网络51%以上的算力。
Selfish Mining
攻击者,不需要 51% 的算力(理论上超过25%就有可能获利)。攻击者挖到区块后并不立即广播,而是选择不发布,并基于这个秘密区块继续挖下一个。
当诚实矿工挖到区块A时,自私矿工如果已经秘密挖到了区块A’和B’(比诚实链长),他就会立刻广播自己的A’和B’。网络会接受更长的链,导致诚实矿工的区块A作废,他们的算力被浪费。
为了防范这种攻击,在比特币中一笔交易通常需要等待6个区块的“确认”(Confirmations)后才被认为是最终、不可逆转的,这大约需要一个小时的时间。因为每增加一个确认,攻击者就需要付出更多的算力和时间来追赶并超越诚实的区块链。
中本聪的计算表明,如果一个攻击者掌握了10%的网络算力,那么在6个区块确认之后,他成功实现双花攻击的概率已经下降到了0.1%以下。这个概率被认为足够低,可以保障绝大多数商业交易的安全。“6个确认”因此成为了一个在安全性与用户体验之间取得平衡的行业“黄金标准”。
分叉
硬分叉
“硬”分叉 (Hard Fork) 是一种永久性的、不向后兼容的“规则升级”。当硬分叉发生时,旧版本的软件(节点)将不再接受新版本软件(节点)创建的区块,导致区块链永久性地分裂成两条不同的链。
它强制要求所有参与者(矿工、节点、交易所、钱包)必须升级到新软件。如果你不升级,你就会被“留在”旧的、即将被淘汰的链上。
硬分叉在 BTC 最著名的例子就是 Bitcoin Cash (BCH),它在 2017 年 8 月从 BTC 硬分叉出去。
- 分歧点: 如何解决比特币的“拥堵”(扩容)问题。们认为 1MB 的上限(以及 SegWit 的 4M WU)太小了,于是他们通过硬分叉,直接把区块大小上限改到了 8MB,后来又改到 32MB。
- BTC 阵营(旧规则): 选择“隔离见证”(SegWit),这是一种复杂的“软分叉”升级(可以理解为优化道路,让每辆车坐更多人)。
- BCH 阵营(新规则): 认为 SegWit 太复杂,主张简单粗暴的“硬分叉”——直接把区块大小上限(1MB)提高到 8MB(可以理解为直接把两车道公路扩建成八车道)。
- 结果:
- BCH 修改了规则代码,并在特定区块高度激活。
- 坚持旧规则的节点继续留在 BTC 链上。
- 运行新规则的节点分裂出去,形成了 Bitcoin Cash 链。
- 新币诞生: 在分叉的那一刻,如果你持有 1 个 BTC,你现在会同时拥有 1 个 BTC(在原始链上)和 1 个 BCH(在新链上)。
这里有个有意思点,如果是在硬分叉之前拥有了某个加密货币,那么在分叉之后将同时拥有“原始货币”和所有“新分叉出来的货币”。
软分叉
软分叉 (Soft Fork) 是一种向后兼容的升级,可以认为是把旧规则变得更严格。
比如,以前的规则是“区块大小不能超过 1MB”。软分叉的新规则是“区块大小不能超过 1MB,并且里面必须包含 A 数据”。旧节点(只懂旧规则)看到新区块时,会觉得:“它没超过 1MB,合法。”(它看不懂 A 数据,但不影响)。新节点会严格执行新规则。
这样只要大多数矿工升级,网络就会被“拉”到新规则上,而不会像硬分叉那样导致区块链分裂。
SegWit (Segregated Witness,隔离见证)就是btc链上一次最重大技术升级实现的软分叉。在 SegWit 之前,比特币网络面临两个主要问题:
- 在比特币交易被确认(打包进区块)之前,任何人都可以轻微地修改这笔交易的数字签名(
scriptSig),而不会使交易失效,这种修改会导致交易ID(txid)发生变化。如果这个txid在交易确认前可以被篡改,就会引发严重问题,比如双花攻击的变种,或者让依赖txid的复杂合约(如闪电网络)变得极难实现。 - 比特币的区块大小被限制在 1MB,数字签名(见证数据)通常会占据一笔交易 60% 甚至更多的空间。这些数据都挤在 1MB 的空间里,大大限制了每个区块能容纳的交易数量。
SegWit 通过改变交易和区块的数据结构,重新定义了一笔交易的结构。它把交易分为两个部分:
- 核心交易数据 (Base Transaction Data):
- 包含:发送方地址、接收方地址、金额等。
- 不包含: 数字签名和解锁脚本。
- 关键点: 交易ID(
txid)只根据这部分数据来计算。
- 见证数据 (Witness Data):
- 包含:所有的数字签名和解锁脚本(即
scriptSig和scriptWitness)。 - 这部分数据被“隔离”出来,存放在交易的一个新字段中。
- 包含:所有的数字签名和解锁脚本(即
由于 txid 现在只根据核心交易数据计算,而签名(scriptSig)这个唯一可以被延展(篡改)的部分已经被移到了见证数据中,不再参与 txid 的计算。因此,一旦交易发出,其 txid 就被永久固定,交易延展性问题被彻底解决。
再来就是SegWit 并没有直接把 1MB 的区块大小限制(Block Size)改掉,而是引入了一个全新的概念:区块权重 (Block Weight)。
- 旧规则: 区块大小上限为 1MB。
- 新规则: 区块“权重”上限为 4,000,000 WU (Weight Units)。
这个权重的计算方式是:
- 1 字节 的 核心交易数据 = 4 WU
- 1 字节 的 见证数据 = 1 WU
那么:
- 如果一个区块全是老式交易(数据和签名混在一起),所有数据都按 4 WU/字节 计算,那么 4,000,000 WU/ 4 = 1,000,000 字节,区块大小仍然是 1MB。
- 如果一个区块全是SegWit交易(签名被隔离),大部分数据(签名)都按 1 WU/字节 计算。这使得区块可以塞下更多的交易数据。
在理想的(全是SegWit交易的)情况下,一个区块的实际物理大小可以达到接近 4MB,但其“权重”仍然是 400 万 WU。